Python - Video Processing with OpenCV

- Basic Video Operations
- Extracting Frames
- Detect Faces using OpenCV Cascades & Alarm Recordings
- Continuous Video Display with Face Detection
see Git Repository for source code.
Basic Video Operations
pip install opencv-python
Requirement already satisfied: opencv-python in /usr/lib/python3.10/site-packages (4.5.5.62)
Getting Video Information
import cv2
video = cv2.VideoCapture('security_cam.mp4')
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(video.get(cv2.CAP_PROP_FPS))
print(width, height, frames, fps)
The security camera footage has a 1440p resolution and consists of 451 frames that are displayed at a frame rate of 30 fps:
python main.py
2560 1440 451 30
Extracting Frames
The OpenCV read() function allows you to grab a single frame from the video file in from of a Numpy array:
print(video.read())
python main.py
(True, array([[[ 45, 45, 45],
[ 47, 47, 47],
[ 39, 39, 39],
...,
[122, 122, 122],
[126, 126, 126],
[140, 140, 140]]], dtype=uint8))
Repeated calls will return the consecutive frames until the last, after which the function will return a False, None. To extract all frames into a folder images we can run a while loop:
# get the first frame and see if successful
success, frame = video.read()
# initiate count
count = 1
# keep extracting frames as long as success is True
while success:
cv2.imwrite(f'images/{count}.jpg', frame)
success, frame = video.read()
count += 1
Extract Frame at Timestamp
This way I now ended up with 450, mostly useless, images from my cameras alarm video. The next step has to be to specify a timestamp from where a frame should be extracted - e.g. given by an Object Detection algorithm:
# get frame at a specific timestamp
timestamp = '00:00:03.00'
hours, minutes, seconds = [float(i) for i in timestamp.split(':')]
# print(hours, minutes, seconds)
# get number of frames up to timestamp
trigger_frame = hours * 3600 * fps + minutes * 60 * fps + seconds * fps
print(frames, trigger_frame)
The total amount of frames in the video file is represented by frames and the number of fames up to the specified timestamp are represented by trigger_frame - in this example it is frame number 90 we want to take a look at:
python main.py
451 90.0
Now we can select this frame and store it inside the images directory:
# Go to frame selected by timestamp
video.set(1, trigger_frame)
success, frame = video.read()
# save the frame into an image file
if success:
cv2.imwrite(f'images/{filename}_{hours}-{minutes}-{seconds}.jpg', frame)
security_cam_0.0-0.0-4.25.jpg

Detect Faces using OpenCV Cascades & Alarm Recordings
Still Images
import cv2
# load image file & frontal face cascade
image = cv2.imread('images/faces.jpg', 1)
face_cascade = cv2.CascadeClassifier('cascades/adaboost_frontal_face_detector.xml')
# use cascade to detect frontal faces
faces = face_cascade.detectMultiScale(image, 1.1, 4)
# print(faces)
# use returned coordinates to draw a frame
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (30,211,198), 3)
# save edited image to file
cv2.imwrite('images/faces_detected.jpg', image)
faces_detected.jpg

Videos
Using a Harr Cascade to detect faces in a video file:
import cv2
# load video file & frontal face cascade
video = cv2.VideoCapture('videos/faces_01.mp4')
face_cascade = cv2.CascadeClassifier('cascades/adaboost_frontal_face_detector.xml')
# read first frame of the video
success, frame = video.read()
# get video fps of input video
fps = int(video.get(cv2.CAP_PROP_FPS))
# prepare empty video file
output = cv2.VideoWriter('videos/output.avi', cv2.VideoWriter_fourcc(*'DIVX'), fps, (1280, 720))
while success:
resize = cv2.resize(frame, (1280, 720))
# use cascade to detect frontal faces
faces = face_cascade.detectMultiScale(resize, 1.4, 4)
# use returned coordinates to draw a frame
for (x, y, w, h) in faces:
cv2.rectangle(resize, (x, y), (x+w, y+h), (30,211,198), 3)
# write frame to empty output
output.write(resize)
# read next frame to start the loop
success, frame = video.read()
# generate video when you reached end of file
output.release()
This code will detect faces, and use the detected coordinates to draw a bounding box around them. These edited frames are then stashed in a new video file:

To issues with this code - the detectMultiScale function is struggling with my source video. Setting the scale factor to 1.4 and minimum neighbors to 4 still gives me false positives on background objects. I hope to improve this by turning the image grayscale.
And secondly, I am returning the entire video. By moving the write() function into the for-loop I would get an output video that only contains frames with detected faces. But I can also simply save every frame into a jpg file instead:
import cv2
# load video file & frontal face cascade
video = cv2.VideoCapture('videos/faces_01.mp4')
face_cascade = cv2.CascadeClassifier('cascades/adaboost_frontal_face_detector.xml')
# read first frame of the video
success, frame = video.read()
count = 1
while success:
# convert image to grayscale and resize
resize = cv2.resize(frame, (1280, 720))
gray_image = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY)
# use cascade to detect frontal faces on grayscale frame
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.4, minNeighbors=4)
# use returned coordinates to draw bounding box on colour frame
for (x, y, w, h) in faces:
cv2.rectangle(resize, (x, y), (x+w, y+h), (198,211,30), thickness=3)
cv2.imwrite(f'images/face_detection_{count}.jpg', resize)
count += 1
# read next frame to start the loop
success, frame = video.read()
This time I am still seeing a few false positives but the detection rate in general has much improved. And I end up with a collection of images that I can process further:
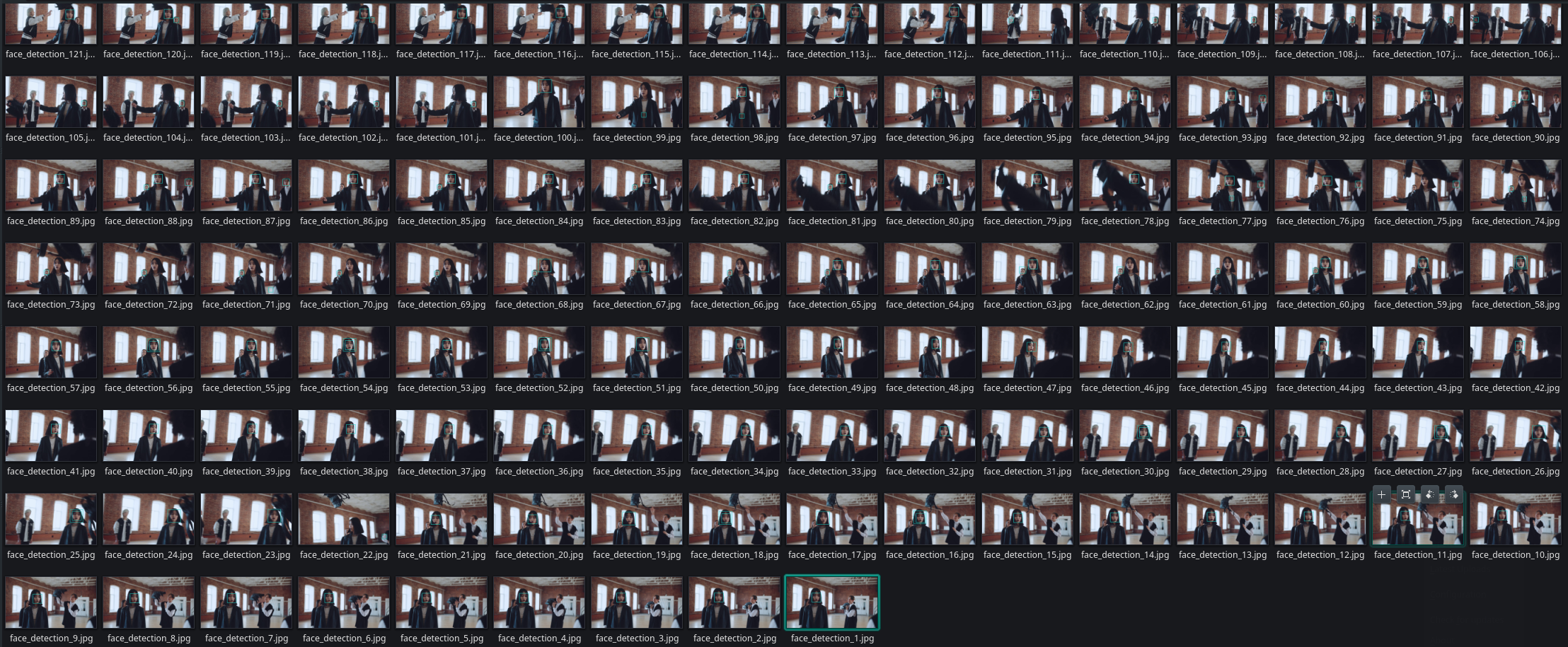
IP Camera Streams
Now that I am able to handle local video files I now want to use an RTSP stream from my INSTAR 2k+ WQHD camera as input source. I already looked at how to process RTSP streams with OpenCV. So now I just have to merge those codes to get an Alarm Snapshot function that will record a single JPG image whenever a face is detected:
import cv2
import os
face_cascade = cv2.CascadeClassifier('cascades/adaboost_frontal_face_detector.xml')
RTSP_URL = 'rtsp://admin:instar@192.168.2.120/livestream/12'
# use tcp instead of udp if stream is unstable
os.environ['OPENCV_FFMPEG_CAPTURE_OPTIONS'] = 'rtsp_transport;udp'
# start the stream and verify
cap = cv2.VideoCapture(RTSP_URL, cv2.CAP_FFMPEG)
if not cap.isOpened():
print("ERROR :: Cannot open RTSP stream")
exit(-1)
# start reading frames
success, frame = cap.read()
count = 0
while success:
# resize frame and convert to grayscale
resize = cv2.resize(frame, (1280, 720))
gray_image = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY)
# use cascade to detect frontal faces on grayscale frame
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.4, minNeighbors=4)
# use returned coordinates to draw bounding box on colour frame
for (x, y, w, h) in faces:
cv2.rectangle(resize, (x, y), (x+w, y+h), (198,211,30), thickness=3)
cv2.imwrite(f'images/face_detection_{count}.jpg', resize)
count += 1
success, frame = cap.read()
So now I have a piece of code that systematically ignores James May. But rigorously triggers whenever Richard Hammond or Jeremy Clarkson walk in - fair enough:
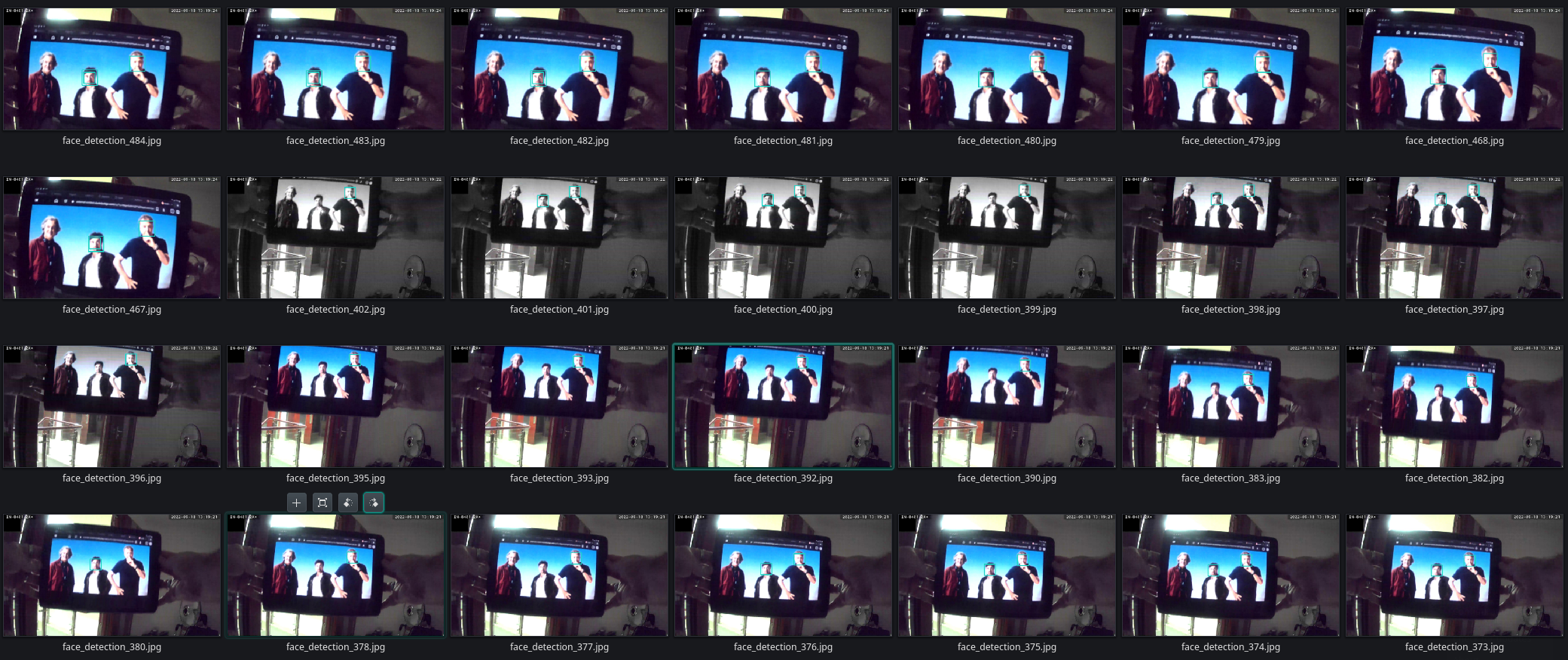
And with a minor change I am also able to record every frame - with a successful face detection - into a video file:
# prepare empty video file
output = cv2.VideoWriter('videos/face_detection.avi', cv2.VideoWriter_fourcc(*'DIVX'), 15, (1280, 720))
# start reading frames
success, frame = cap.read()
count = 0
while success:
# resize frame and convert to grayscale
resize = cv2.resize(frame, (1280, 720))
gray_image = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY)
# use cascade to detect frontal faces on grayscale frame
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.4, minNeighbors=4)
# use returned coordinates to draw bounding box on colour frame
for (x, y, w, h) in faces:
cv2.rectangle(resize, (x, y), (x+w, y+h), (198,211,30), thickness=3)
output.write(resize)
count += 1
success, frame = cap.read()
output.release()
Continuous Video Display with Face Detection
To be able to monitor the live video while recording with face detection use the following code:
import cv2
import os
face_cascade = cv2.CascadeClassifier('cascades/adaboost_frontal_face_detector.xml')
RTSP_URL = 'rtsp://admin:instar@192.168.2.120/livestream/12'
os.environ['OPENCV_FFMPEG_CAPTURE_OPTIONS'] = 'rtsp_transport;udp' # Use tcp instead of udp if stream is unstable
cap = cv2.VideoCapture(RTSP_URL, cv2.CAP_FFMPEG)
if not cap.isOpened():
print('Cannot open RTSP stream')
exit(-1)
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
fps = 15
video_codec = cv2.VideoWriter_fourcc(*'DIVX')
# video_output = cv2.VideoWriter('videos/captured_video.avi', video_codec, fps, (frame_width, frame_height))
video_output = cv2.VideoWriter('videos/captured_video.avi', video_codec, 15, (1280, 720))
while True:
success, frame = cap.read()
if success:
# resize frame and convert to grayscale
resize = cv2.resize(frame, (1280, 720))
gray_image = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY)
# use cascade to detect frontal faces on grayscale frame
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.4, minNeighbors=4)
# use returned coordinates to draw bounding box on colour frame
for (x, y, w, h) in faces:
cv2.rectangle(resize, (x, y), (x+w, y+h), (198,211,30), thickness=3)
cv2.imshow("Video Recording", resize)
video_output.write(resize)
if cv2.waitKey(1) & 0xFF == ord('q'):
cap.release()
video_output.release()
cv2.destroyAllWindows()
print('INFO :: Video was saved.')
break
else:
cap.release()
video_output.release()
cv2.destroyAllWindows()
print('ERROR :: Video recording aborted!')
break