Python - Build an Elasticsearch Index for your Docusaurus Blog

I looked into retrieving text from webpages using Beautiful Soup. And continued with looking into processing text. I was able to bring both together by pulling text from an URL, process the content and write it into an Elasticsearch JSON Document. Now I want to automate this process a little by using a pages sitemap.
Elasticsearch
There are many different ways to automatically generate Elasticsearch entries. But I always had the problem that the Elasticsearch entry should contain a few information that are not part of the page itself. Since I only rarely add new content I have been doing it by had so far.
Mapping
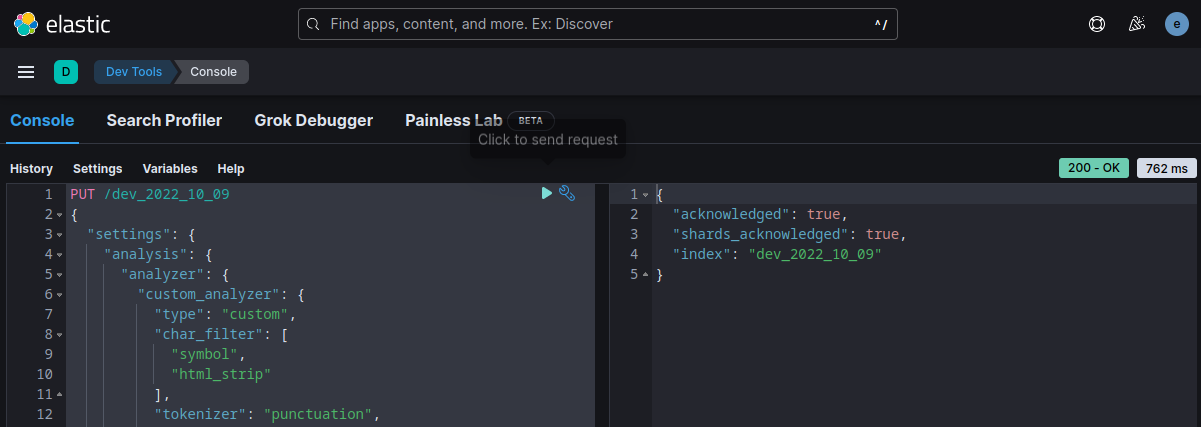
First you create a mapping that suits your content. This is optional in NoSQL - but it allows you to define analyzer that Elasticsearch should use. Also, if you want to filter your Search results you have to set those fields to be treated as keywords and stored unprocessed. The example mapping for this blog is:
PUT /dev_2022_10_09
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"char_filter": [
"symbol",
"html_strip"
],
"tokenizer": "punctuation",
"filter": [
"lowercase",
"word_delimiter",
"english_stop",
"english_stemmer"
]
}
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_ "
},
"english_stemmer": {
"type": "stemmer",
"language": "english"
}
},
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": "[.,!?&=_:;']"
}
},
"char_filter": {
"symbol": {
"type": "mapping",
"mappings": [
"& => and",
":) => happy",
":( => unhappy",
"+ => plus"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "custom_analyzer",
"index": "true"
},
"type": {
"type": "text",
"index": "true",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"date": {
"type": "text",
"index": "true",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"description": {
"type": "text",
"analyzer": "custom_analyzer",
"index": "true"
},
"link": {
"type": "text",
"index": "false"
},
"chapter": {
"type": "text",
"index": "true",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"tags": {
"type": "text",
"index": "true",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"imagesquare": {
"type": "text",
"index": "false"
},
"abstract": {
"type": "text",
"analyzer": "custom_analyzer",
"index": "true"
},
"short": {
"type": "text",
"analyzer": "custom_analyzer",
"index": "true"
}
}
}
}
Just modify it to your needs and feed it into Kibana to set up your Elasticsearch index:
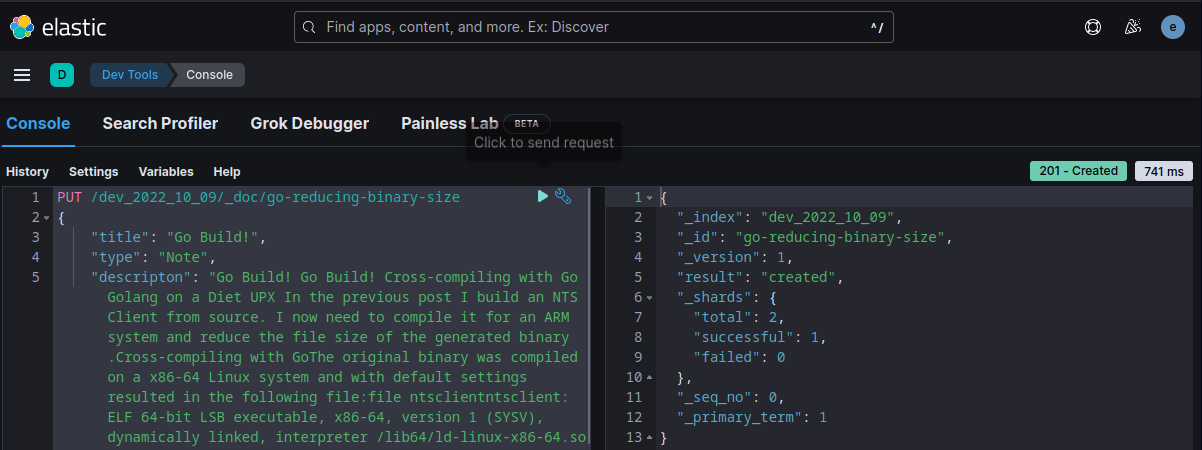
Every article now needs to be added following the structure defined in your mapping. For example the JSON doc for the Go build! looks like this:
PUT /dev_2022_10_09/_doc/go-reducing-binary-size
{
"title": "Go Build!",
"type": "Note",
"descripton": "Go Build! Go Build! Cross-compiling with Go Golang on a Diet UPX In the previous post I build an NTS Client from source. I now need to compile it for an ARM system and reduce the file size of the generated binary.Cross-compiling with GoThe original binary was compiled on a x86-64 Linux system and with default settings resulted in the following file:file ntsclientntsclient: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, Go BuildID=jk1ySsUE9xCbQQElzPBj/mKJ-lNqe4rCLOALwJ0Uh/lg1ziBDAYw1FdjS_SnD_/6JHvJ15niw3mnL010nFR, with debug_info, not strippedTo use the binary on an ARM system we need to use the amazing cross-compiling capabilities of Go. E.g. to create the arm64 version of the file I can run:env GOOS=linux GOARCH=arm64 go build -o ntsclient_arm64The resulting binary can be used on an 64bit ARM system:file ntsclient_arm64ntsclient_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, Go BuildID=MR5GvnV5S4XWxDENNLTE/ZZ2k_Dx5K6CdKRTzWlK5/Zbl1ahI9CUA-f28opmhH/0Zh0CFmxrhuWRZ-kOiMt, with debug_info, not strippedYou can check the supported combinations of GOOS and GOARCH with:go tool dist listaix/ppc64 | android/386 | android/amd64 | android/arm | android/arm64 | darwin/amd64 | darwin/arm64 | dragonfly/amd64 | freebsd/386 | freebsd/amd64 | freebsd/arm | freebsd/arm64 | illumos/amd64 | ios/amd64 | ios/arm64 | js/wasm | linux/386 | linux/amd64 | linux/arm | linux/arm64 | linux/loong64 | linux/mips | linux/mips64 | linux/mips64le | linux/mipsle | linux/ppc64 | linux/ppc64le | linux/riscv64 | linux/s390x | netbsd/386 | netbsd/amd64 | netbsd/arm | netbsd/arm64 | openbsd/386 | openbsd/amd64 | openbsd/arm | openbsd/arm64 | openbsd/mips64 | plan9/386 | plan9/amd64 | plan9/arm | solaris/amd64 | windows/386 | windows/amd64 | windows/arm | windows/arm64We can automate a multi-architecture build with a script build.sh: usr/bin/basharchs=(amd64 arm arm64)for arch in ${archs[@]}do env GOOS=linux GOARCH=${arch} go build -o prepnode_${arch}doneGolang on a DietThe resulting files - compared to a similar C program - are generally huge. In the NTS client example I end up with 7.4 - 7.7 MB files:7965759 Oct 5 15:37 ntsclient_amd647665133 Oct 5 15:37 ntsclient_arm7635040 Oct 5 15:24 ntsclient_arm64The following build flags can help us reducing the binary size:ldflags-s omits the symbol table and debug information-w omits DWARF debugging information.So lets update the build script accordingly: usr/bin/basharchs=(amd64 arm arm64)for arch in ${archs[@]}do env GOOS=linux GOARCH=${arch} go build -ldflags -s -w -o prepnode_${arch}doneNow we are down to 5.0 - 5.2 MB:5459968 Oct 5 16:55 ntsclient_amd645242880 Oct 5 16:55 ntsclient_arm5242880 Oct 5 16:55 ntsclient_arm64UPXUPX is a free, secure, portable, extendable, high-performance executable packer for several executable formats. You can install the latest version from Github or use your package manager:sudo pacman -S utxupx --help Ultimate Packer for eXecutables Copyright (C) 1996 - 2020UPX git-d7ba31+ Markus Oberhumer, Laszlo Molnar & John Reiser Jan 23rd 2020Usage: upx [-123456789dlthVL] [-qvfk] [-o file] file..Commands: -1 compress faster -9 compress better --best compress best (can be slow for big files) -d decompress -l list compressed file -t test compressed file -V display version number -h give this help -L display software licenseOptions: -q be quiet -v be verbose -oFILE write output to FILE -f force compression of suspicious files --no-color, --mono, --color, --no-progress change lookCompression tuning options: --brute try all available compression methods & filters [slow] --ultra-brute try even more compression variants [very slow]So to get the maximum amount of compress let s try Ultra Brute:upx --ultra-brute -ontsclient_upx_arm ntsclient_arm File size Ratio Format Name-------------------- ------ ----------- -----------5242880 -> 1421184 27.11% linux/arm ntsclient_upx_arm So we went from around 7 MB down to 1.4 MB. Tags: Go",
"link": "/docs/Development/Go/2022-10-05-go-reducing-binary-size/2022-10-05",
"chapter": "Dev Notes",
"date": "2022-10-05",
"tags": [
"Go",
"LINUX"
],
"imagesquare": "/img/search/go.png",
"abstract": "Cross-compile in Go and reduce the binary size of your Go program."
}
And can be added to your index using Kibana and the be searched in your React Frontend:
Automate with Python
In the previous step I used Python to create the Elasticsearch Document for a single page - Github.
Now I want to use this approach to pull the Blog's XML Sitemap, loop over all URLs and create a mostly filled template for each page. There are still a few fields that I cannot fill based on the pages content. But I will just add some placeholder text and copy&paste the rest in by hand (In the future I will see to it that all of those information will be embedded in all articles ~ but this is already a big improvement over doing all of it by hand).
Ok, I will break this project up into 2 steps. First, I will pull the sitemap and write those URLs into a text file. The second part will then be to loop over this file and generate the JSON objects. The advantage of breaking this up into two scripts is that I will be able to feed manually created text files to the second script and append new articles later on.
XML Sitemap Parsing
I can use lxml to parse the XML Sitemap in parse_sitemap.py:
from lxml import etree
import requests
sideLinks = {}
r = requests.get("https://mpolinowski.github.io/sitemap.xml")
root = etree.fromstring(r.content)
print("INFO :: {0} pages imported from sitemap.".format(len(root)))
for sitemap in root:
children = sitemap.getchildren()
sideLinks[children[0].text] = children[1].text
# write to file
with open('pages/sideLinks.txt', 'w') as file:
file.writelines('\n'.join(sideLinks))
This will generate a file sideLinks.txt with the extracted URLs. One URL per line.
Generate Elasticsearch Docs
write_object.py now loops over every line of the generated text file and runs the code to generate the JSON object:
import requests
import re
from bs4 import BeautifulSoup
# add some infos that are not on the page
camera_series = '["PLACEHOLDER"]'
article_type = 'PLACEHOLDER'
chapter = 'PLACEHOLDER'
tags = '["PLACEHOLDER"]'
image = 'PLACEHOLDER'
imagesquare = 'PLACEHOLDER'
# read in list of page urls
pages = open('pages/sideLinkscopy.txt', 'r')
# loop over urls and request content
for line in pages:
page = line.split()[0]
# print(page[0])
# exit()
# use page url to fetch/parse content
response = requests.get(page)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# find in content
## get article title from meta tag
article_title = (soup.find("meta", property="og:title"))["content"]
## get article description from meta tag
article_description = (soup.find("meta", property="og:description"))["content"]
## get article description from meta tag
article_content = soup.find('main', attrs={'class': 'docMainContainer_gTbr'}).text
## replace quotation marks
jsonfied_content = article_content.replace('"', ' ')
## strip multiple-space character
single_space = re.sub('\s+',' ',jsonfied_content)
# create json object from results
json_template = """{
"title": "ARTICLE_TITLE",
"series": ARTICLE_SERIES,
"type": "ARTICLE_TYPE",
"description": "ARTICLE_BODY",
"sublink1": "ARTICLE_URL",
"chapter": "ARTICLE_CHAPTER",
"tags": ARTICLE_TAGS,
"image": "ARTICLE_THUMB",
"imagesquare": "ARTICLE_SQUAREIMAGE",
"short": "ARTICLE_SHORT",
"abstract": "ARTICLE_ABSTRACT"
}"""
add_body = json_template.replace('ARTICLE_BODY', single_space)
add_title = add_body.replace('ARTICLE_TITLE', article_title)
add_series = add_title.replace('ARTICLE_SERIES', camera_series)
add_type = add_series.replace('ARTICLE_TYPE', article_type)
add_url = add_type.replace('ARTICLE_URL', page[29:])
add_chapter = add_url.replace('ARTICLE_CHAPTER', chapter)
add_tags = add_chapter.replace('ARTICLE_TAGS', tags)
add_image = add_tags.replace('ARTICLE_THUMB', image)
add_imagesquare = add_image.replace('ARTICLE_SQUAREIMAGE', imagesquare)
add_short = add_imagesquare.replace('ARTICLE_SHORT', article_description)
add_abstract = add_short.replace('ARTICLE_ABSTRACT', article_description)
with open('pages/articles.json', 'a') as file:
file.write(add_abstract)
pages.close()
This now generates the entries I need to feed into Kibana - with a few PLACEHOLDER's added where I still need to add informations by hand - articles.json.
Good enough for now ~ to be improved later :)