Elasticsearch 7 Refresher

I did not have a chance to work with Elasticsearch a lot these days. I want to dive in to a few online courses and refresh my knowledge. Hoping that I can find something that I can plug in to a work project.
Introduction
Ok, I spun up a Docker ELK Stack version 7.13.3. I now have to login to Kibana and create a simple mapping with the following content:
{
"mappings" : {
"properties" : {
"speaker" : {"type": "keyword" },
"play_name" : {"type": "keyword" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
And load it into Elasticsearch:
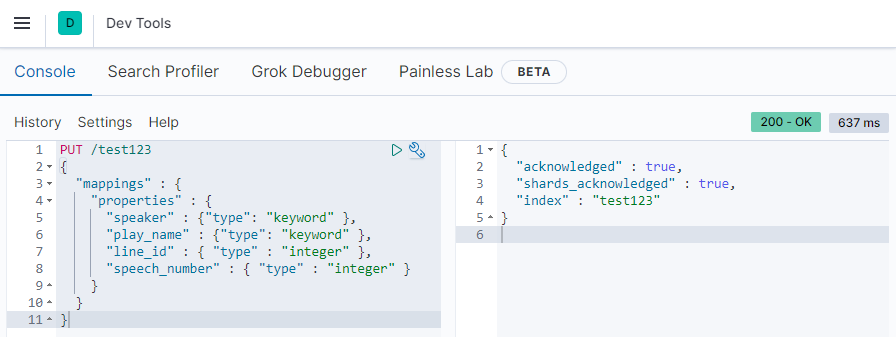
The Data that I am going to work with is available for download here. Just download the file, copy it's content and add it to the index you created - in my case the test123:
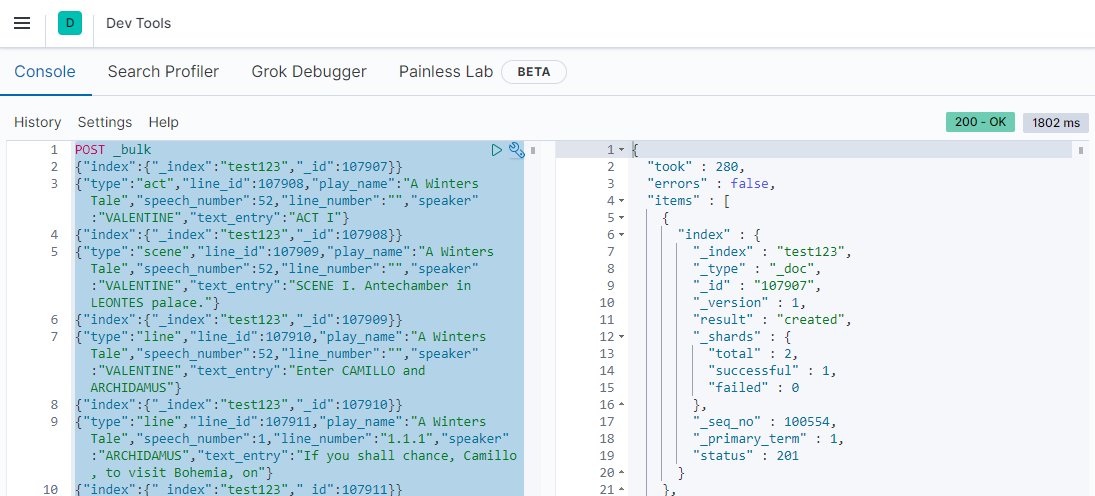
The JSON file contains to many entries - either break them up by plays or check out the CURL way later on!
Now I will create an index pattern based on the index I just created:
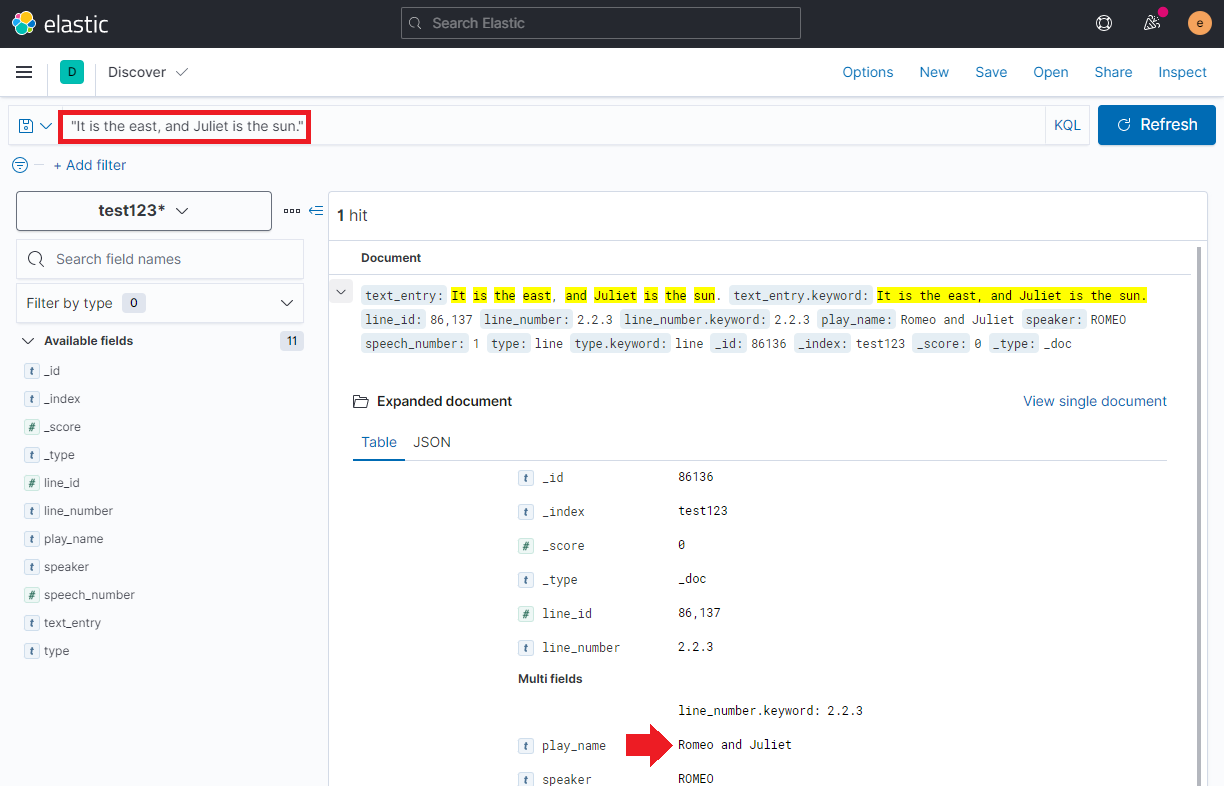
And can test it with a search query - what play is the quote It is the east, and Juliet is the sun. from?
Advanced Mappings
Types and Analyzer
- Type =
keyword: Value will not be analysed. Only exact matches will be a hit. - Analyzer =
english: Defining a language analyzer will help you clean up your full text search by removing stop words and reducing words to their root form:
PUT /television
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"year": {
"type": "date"
},
"genre": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "english"
}
}
}
}
We can add some data from imdb.com and format it to conform with the mapping above:
PUT _bulk
{ "create" : { "_index" : "television", "_id" : "band-of-brothers" } }
{ "id": "135569", "title" : "Band of Brothers", "year":2001 , "genre":["Action", "Drama", "History", "War"] }
{ "create" : { "_index" : "television", "_id" : "chernobyl" } }
{ "id": "122886", "title" : "Chernobyl", "year":2019 , "genre":["Drama", "History", "Thriller"] }
{ "create" : { "_index" : "television", "_id" : "firefly" } }
{ "id": "109487", "title" : "Firefly", "year":2002 , "genre":["Sci-Fi", "Adventure", "Drama"] }
{ "create" : { "_index" : "television", "_id" : "battlestar-galactica" } }
{ "id": "58559", "title" : "Battlestar Galactica", "year":2004 , "genre":["Action", "Adventure", "Drama", "Sci-Fi"] }
{ "create" : { "_index" : "television", "_id" : "top-gear" } }
{ "id": "1924", "title" : "Top Gear", "year":2002 , "genre":["Talk Show", "Adventure", "Travel"] }
We can now search for a TV Series in Kibana:
GET /television/_search
{
"query": {
"match": {
"title": "galactica"
}
}
}
I am only using a partial title and the wrong case - still I am getting the correct response from Elasticsearch:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2576691,
"hits" : [
{
"_index" : "television",
"_type" : "_doc",
"_id" : "battlestar-galactica",
"_score" : 1.2576691,
"_source" : {
"id" : "58559",
"title" : "Battlestar Galactica",
"year" : 2004,
"genre" : [
"Action",
"Adventure",
"Drama",
"Sci-Fi"
]
}
}
]
}
}
And since we are using the English Analyzer we can even use brother instead of Brothers and get a correct hit:
GET /television/_search
{
"query": {
"match": {
"title": "brother"
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2576691,
"hits" : [
{
"_index" : "television",
"_type" : "_doc",
"_id" : "band-of-brothers",
"_score" : 1.2576691,
"_source" : {
"id" : "135569",
"title" : "Band of Brothers",
"year" : 2001,
"genre" : [
"Action",
"Drama",
"History",
"War"
]
}
}
]
}
}
But searching for the Genre Talk (nor talk show) will not get you any hits as we mapped this value as a Keyword that is not going to be analysed - only the entire value Talk Show will work:
GET /television/_search
{
"query": {
"match": {
"genre": "Talk"
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
Relationships
Elasticsearch allows us to join documents in a Parent / Child relationship. E.g. joining all episodes of a season into a group:
PUT /the-expanse
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"air-date": {
"type": "date"
},
"title": {
"type": "text",
"analyzer": "english"
},
"abstract": {
"type": "text",
"analyzer": "english"
},
"imdb-rating": {
"type": "float"
},
"filming-season": {
"type": "join",
"relations": {"season": "episode"}
}
}
}
}
POST _bulk
{ "create" : { "_index" : "the-expanse", "_id" : "the-expanse", "routing" : 1} }
{ "id": "the-expanse", "filming-season": {"name": "season"}, "title" : "Season 01" }
{ "create" : { "_index" : "the-expanse", "_id" : "dulcinea", "routing" : 1} }
{ "id": "dulcinea", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Dulcinea", "imdb-rating":"7.7", "air-date": "2015-11-23", "abstract":"In the asteroid belt near Saturn, James Holden and the crew of the ice freighter Canterbury, on its way to Ceres Station, investigate a distress call from an unknown derelict ship, the Scopuli." }
{ "create" : { "_index" : "the-expanse", "_id" : "the-big-empty", "routing" : 1} }
{ "id": "the-big-empty", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "The Big Empty", "imdb-rating":"7.7", "air-date": "2015-12-15", "abstract":"Holden and crew are trapped in a badly damaged shuttle. On Ceres, Miller uncovers clues about Julie Mao. On Earth, Chrisjen Avasarala questions a terrorist. " }
{ "create" : { "_index" : "the-expanse", "_id" : "remember-the-cant", "routing" : 1} }
{ "id": "remember-the-cant", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Remember the Cant", "imdb-rating":"8.0", "air-date": "2015-12-16", "abstract":"While Avasarala plays a dangerous game of politics, Holden and his crew are forced to turn on one another while held captive by the Martian Navy." }
{ "create" : { "_index" : "the-expanse", "_id" : "cqb", "routing" : 1} }
{ "id": "cqb", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "CQB", "imdb-rating":"8.7", "air-date": "2015-12-16", "abstract":"Holden and crew are caught in the middle of a desperate battle as mysterious war ships attack and board the Donnager. As Miller continues to investigate Julie Mao, his partner Havelock continues to go missing." }
{ "create" : { "_index" : "the-expanse", "_id" : "back-to-the-butcher", "routing" : 1} }
{ "id": "back-to-the-butcher", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Back to the Butcher", "imdb-rating":"7.8", "air-date": "2016-01-05", "abstract":"The crew has survived the loss of the Canterbury and the Donnager and are contacted by an unlikely ally. Miller, on Ceres, continues his investigation and his thoughts of a conspiracy grow." }
{ "create" : { "_index" : "the-expanse", "_id" : "rock-bottom", "routing" : 1} }
{ "id": "rock-bottom", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Rock Bottom", "imdb-rating":"8.0", "air-date": "2016-01-12", "abstract":"Holden's team makes an uneasy alliance with Fred Johnson while Miller fights for his life against Anderson Dawe's thugs." }
{ "create" : { "_index" : "the-expanse", "_id" : "windmills", "routing" : 1} }
{ "id": "windmills", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Windmills", "imdb-rating":"7.9", "air-date": "2016-01-19", "abstract":"Holden and crew realize that they're not alone on the Rocinante and find themselves up against a Martian Marine blockade. Miller's dark night of the soul, believing all is lost, finds a new reason to keep going. Avasarala visits Holden's family in Montana." }
{ "create" : { "_index" : "the-expanse", "_id" : "salvage", "routing" : 1} }
{ "id": "salvage", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Salvage", "imdb-rating":"8.7", "air-date": "2016-01-26", "abstract":"A derelict vessel holds a potentially devastating secret. Holden and his crew cross paths with Miller on Eros. Avasarala receives bad news. " }
{ "create" : { "_index" : "the-expanse", "_id" : "critical-mass", "routing" : 1} }
{ "id": "critical-mass", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Critical Mass", "imdb-rating":"8.7", "air-date": "2016-02-02", "abstract":"A flashback to Julie's origin story reveals her trajectory. Holden and Miller finally meet and team up to get to the bottom of the strange emergency situation happening on Eros. As the true horror of the events on Eros is revealed, an ailing Holden and Miller must overcome incredible odds if they hope to live to fight another day. Part 1 of 2" }
{ "create" : { "_index" : "the-expanse", "_id" : "leviathan-wakes", "routing" : 1} }
{ "id": "leviathan-wakes", "filming-season": {"name": "episode", "parent": "the-expanse"}, "title" : "Leviathan Wakes", "imdb-rating":"8.7", "air-date": "2016-02-02", "abstract":"A flashback to Julie's origin story reveals her trajectory. Holden and Miller finally meet and team up to get to the bottom of the strange emergency situation happening on Eros. As the true horror of the events on Eros is revealed, an ailing Holden and Miller must overcome incredible odds if they hope to live to fight another day. Part 2 of 2" }
We can now run a search query that returns to us all the episodes of season one of the TV series The Expanse:
GET /the-expanse/_search
{
"query": {
"has_parent": {
"parent_type": "season",
"query": {
"match": {
"title": "Season 01"
}
}
}
}
}
Find out which Season the Episode Leviathan Wakes belonged to:
GET /the-expanse/_search
{
"query": {
"has_child": {
"type": "episode",
"query": {
"match": {
"title": "Leviathan Wakes"
}
}
}
}
}
Delete Documents by Query
I just wanted to delete a couple of documents from an index and noticed that you cannot use regular expressions to do so:
DELETE /wiki_de_prefix_2021_06_07/_doc/yt-*
Instead you have to use a query like
GET /wiki_de_prefix_2021_06_07/_search
{
"query": {
"match": {
"tags": "Youtube"
}
}
}
And instead of directing it to _search select _delete_by_query to delete all documents that matched to search query:
POST wiki_de_prefix_2021_06_07/_delete_by_query
{
"query": {
"match": {
"tags": "Youtube"
}
}
}
A Few More Search Examples
Simple Search
curl -XGET 'https://my.domain.com/my_index/_search?q=avm'
Paginate
curl -XGET 'https://my.domain.com/my_index/_search?q=avm&size=5&from=0'
curl -XGET 'https://my.domain.com/my_index/_search?q=avm&size=5&from=5'
curl -XGET 'https://my.domain.com/my_index/_search?q=avm&size=5&from=10'
Weighted Multi-Match
curl -XGET 'https://my.domain.com/my_index/_search?pretty=true' -H 'Content-Type: application/json' -d '{
"query": {
"multi_match" : {
"query": "IN-9020 Full HD Cameras",
"fields": ["title^8", "tags^10", "abstract^5", "description^3"]
}
}
}'
Illegal Characters
I found out that Elasticsearch does not like it when you use the colon character ::
curl -XGET 'https://my.domain.com/my_index/_search?pretty=true&q=FAQ+::+9020+Full+HD'
{
"error" : {
"root_cause" : [
{
"type" : "query_shard_exception",
"reason" : "Failed to parse query [FAQ :: 9020 Full HD]",
"index_uuid" : "XwBTMA_jS0G1CaEK7we_3Q",
"index" : "my_index"
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "my_index",
"node" : "bFc0o2JrTBqG0zf9Wydh3g",
"reason" : {
"type" : "query_shard_exception",
"reason" : "Failed to parse query [FAQ :: 9020 Full HD]",
"index_uuid" : "XwBTMA_jS0G1CaEK7we_3Q",
"index" : "my_index",
"caused_by" : {
"type" : "parse_exception",
"reason" : "Cannot parse 'FAQ :: 9020 Full HD': Encountered \" \":\" \": \"\" at line 1, column 5.\nWas expecting one of:\n <BAREOPER> ...\n \"(\" ...\n \"*\" ...\n <QUOTED> ...\n <TERM> ...\n <PREFIXTERM> ...\n <WILDTERM> ...\n <REGEXPTERM> ...\n \"[\" ...\n \"{\" ...\n <NUMBER> ...\n ",
"caused_by" : {
"type" : "parse_exception",
"reason" : "Encountered \" \":\" \": \"\" at line 1, column 5.\nWas expecting one of:\n <BAREOPER> ...\n \"(\" ...\n \"*\" ...\n <QUOTED> ...\n <TERM> ...\n <PREFIXTERM> ...\n <WILDTERM> ...\n <REGEXPTERM> ...\n \"[\" ...\n \"{\" ...\n <NUMBER> ...\n "
}
}
}
}
]
},
"status" : 400
}
I can see the same in Kibana:
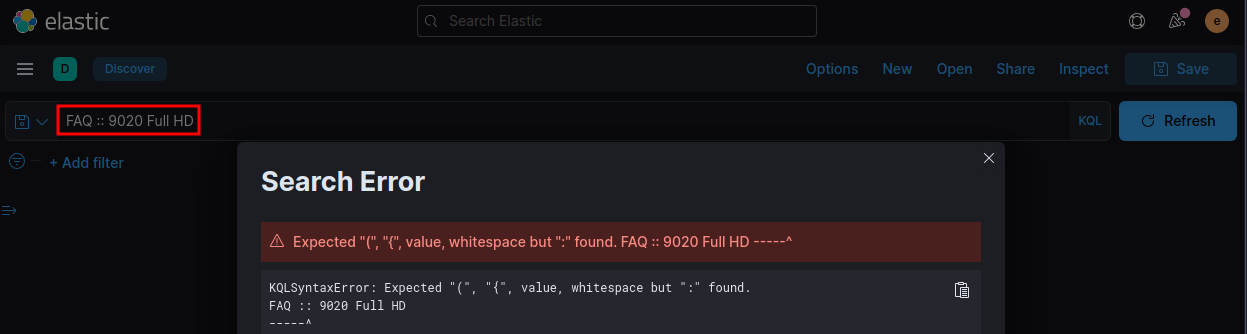
__Search Error: Expected "(", "{", value, whitespace but ":" found. FAQ :: 9020 Full HD -----^ KQLSyntaxError: Expected "(", "{", value, whitespace but ":" found. FAQ :: 9020 Full HD
Here I can simply escape the offending characters with a slash:
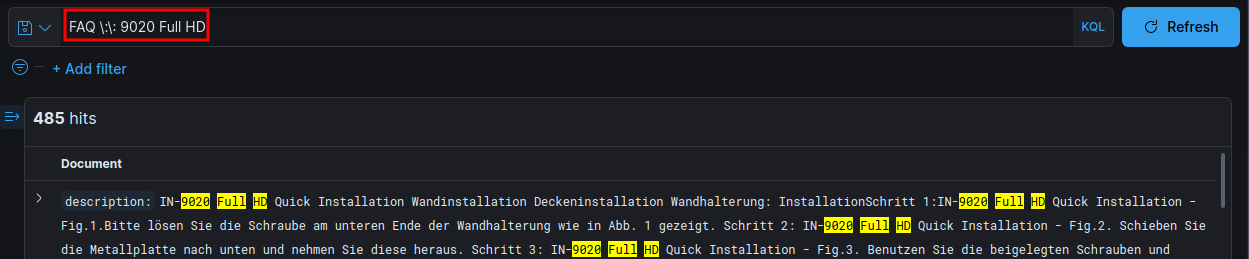
Transferring this to my Curl command I first need to escape:
FAQ \:\: 9020 Full HD
and then add the URL Encoding:
FAQ+%5C%3A%5C%3A+9020+Full+HD
Now it is possible to use URL query params as before:
curl -XGET 'https://my.domain.com/my_index/_search/_search?pretty=true&q=FAQ+%5C%3A%5C%3A+9020+Full+HD'
Alternatively, I can use the JSON format in my request to begin with:
curl -XGET 'https://my.domain.com/my_index/_search/_search?pretty=true' -H 'Content-Type: application/json' -d '{
"query": {
"multi_match" : {
"query": "FAQ :: 9020",
"fields": ["title^8", "tags^10", "abstract^5", "description^3"]
}
}
}'