Logstash 7 Working with Structured Data

Working with CSV Data
Data Source see Github/Coralogix:
Create a file payment.csv with the following content in /opt/logstash:
id,timestamp,paymentType,name,gender,ip_address,purpose,country,age
1,2019-08-29T01:53:12Z,Amex,Yuki Calvaire,Female,185.216.194.245,Industrial,Canada,55
2,2019-11-16T14:55:13Z,Mastercard,Misaki Zelretch,Male,131.61.251.254,Clothing,Japan,32
3,2019-10-07T03:52:52Z,Amex,Michaella Gerrietz,Female,208.21.209.84,Computers,Taiwan,32
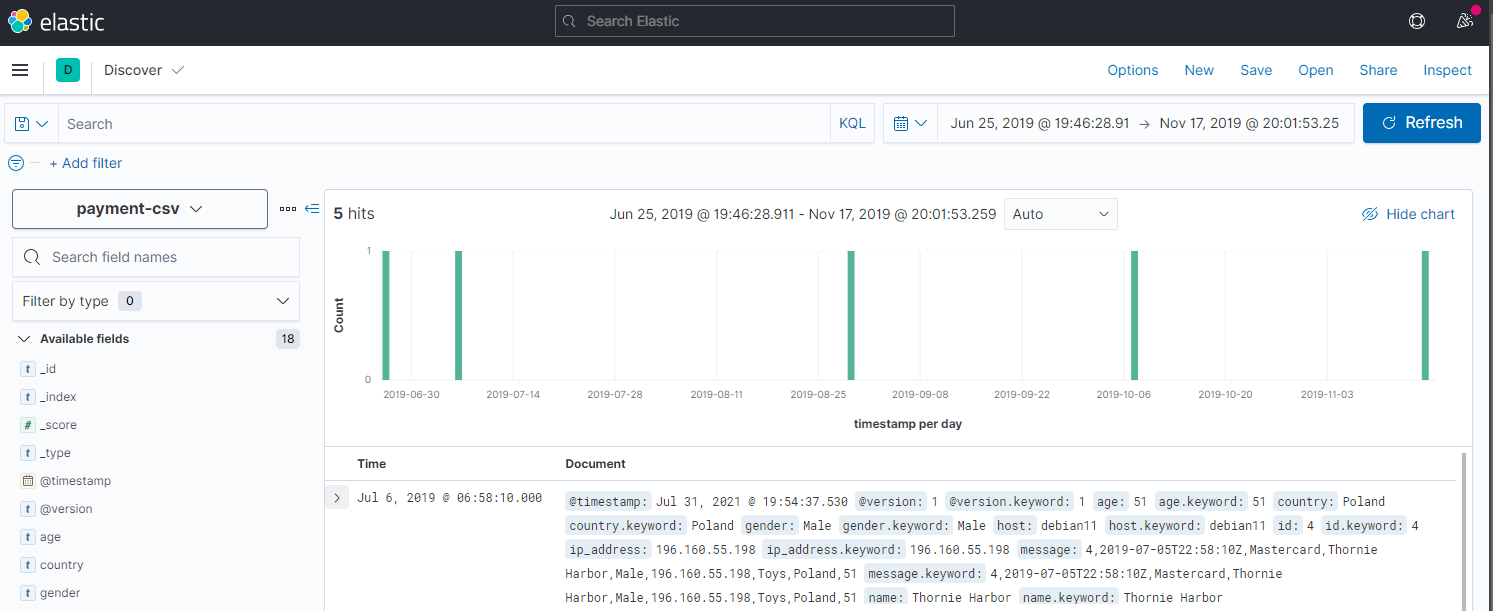
4,2019-07-05T22:58:10Z,Mastercard,Renee Markov,Male,196.160.55.198,Toys,Estonia,51
5,2019-06-26T08:53:59Z,Visa,Sion Fiori,Male,64.237.78.240,Computers,Paraguay,25
Now create the /opt/logstash/pipeline/logstash.conf file:
input {
file {
path => "/usr/share/logstash/payment.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
skip_header => "true"
columns => ["id","timestamp","paymentType","name","gender","ip_address","purpose","country","age"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-csv"
}
stdout {}
}
Now run the Logstash container:
chown -R 1000:1000 /opt/logstash
docker run \
--name logstash \
--net=host \
--rm -it \
-v /opt/logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /opt/logstash/payment.csv:/usr/share/logstash/payment.csv \
-e "ELASTIC_HOST=localhost:9200" \
-e "XPACK_SECURITY_ENABLED=false" \
-e "XPACK_REPORTING_ENABLED=false" \
-e "XPACK_MONITORING_ENABLED=false" \
-e "XPACK_MONITORING_ELASTICSEARCH_USERNAME=elastic" \
-e "XPACK_MONITORING_ELASTICSEARCH_PASSWORD=changeme" \
logstash:7.13.4
Logstash will now ingest the CSV file. Once it is done open Kibana and create an index pattern payment-csv and set the Time Field to timestamp:
Data Mutation
We can also use Logstash to modify the data before forwarding it to Elasticsearch:
input {
file {
path => "/usr/share/logstash/payment.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
skip_header => "true"
columns => ["id","timestamp","paymentType","name","gender","ip_address","purpose","country","age"]
}
mutate {
convert => {
age => "integer"
}
remove_field => ["message","@timestamp","path","host","@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-csv-clean"
}
stdout {}
}
The Mutate Section will now convert the age field Type to Integer and remove meta fields that will be added automatically by Logstash in the CSV Section before.
BEFORE:
{
"message" => "4,2019-07-05T22:58:10Z,Mastercard,Renee Markov,Male,196.160.55.198,Toys,Poland,51",
"path" => "/usr/share/logstash/payment.csv",
"@version" => "1",
"paymentType" => "Mastercard",
"country" => "Poland",
"@timestamp" => 2021-07-31T11:54:37.530Z,
"host" => "debian11",
"id" => "4",
"purpose" => "Toys",
"timestamp" => "2019-07-05T22:58:10Z",
"age" => "51",
"ip_address" => "196.160.55.198",
"name" => "Renee Markov",
"gender" => "Male"
}
AFTER:
{
"paymentType" => "Mastercard",
"gender" => "Male",
"purpose" => "Toys",
"country" => "Poland",
"age" => 51,
"id" => "4",
"ip_address" => "196.160.55.198",
"timestamp" => "2019-07-05T22:58:10Z",
"name" => "Renee Markov"
}
To verify the mapping (age has to be type (long) integer) we can run the following command:
curl -XGET 'http://localhost:9200/payment-csv-clean/_mapping/field/age?pretty=true'
{
"payment-csv-clean" : {
"mappings" : {
"age" : {
"full_name" : "age",
"mapping" : {
"age" : {
"type" : "long"
}
}
}
}
}
}
Working with JSON Data
Now let's do the same with a JSON file - /opt/logstash/payment.json:
{"id":1,"timestamp":"2019-09-12T13:43:42Z","paymentType":"WeChat","name":"Jenna Starr","gender":"Female","ip_address":"132.150.218.21","purpose":"Toys","country":"Canada","age":23}
{"id":2,"timestamp":"2019-08-11T17:55:56Z","paymentType":"WeChat","name":"Yuki Calvaire","gender":"Female","ip_address":"77.72.239.47","purpose":"Shoes","country":"Japan","age":34}
{"id":3,"timestamp":"2019-07-14T04:48:25Z","paymentType":"AliPay","name":"Misaki Zelretch","gender":"Female","ip_address":"227.6.210.146","purpose":"Sports","country":"Taiwan","age":53}
{"id":4,"timestamp":"2020-02-29T12:41:59Z","paymentType":"WeChat","name":"Renee Markov","gender":"Male","ip_address":"139.224.15.154","purpose":"Home","country":"Estonia","age":47}
{"id":5,"timestamp":"2019-08-03T19:37:51Z","paymentType":"Mastercard","name":"Sion Fiori","gender":"Female","ip_address":"252.254.68.68","purpose":"Health","country":"Paraguay","age":37}
Now create the /opt/logstash/pipeline/logstash.conf file:
input {
file {
path => "/usr/share/logstash/payment.json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-json"
}
stdout {}
}
And run Logstash with the new configuration file:
docker run \
--name logstash \
--net=host \
--rm -it \
-v /opt/logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /opt/logstash/payment.json:/usr/share/logstash/payment.json \
-e "ELASTIC_HOST=localhost:9200" \
-e "XPACK_SECURITY_ENABLED=false" \
-e "XPACK_REPORTING_ENABLED=false" \
-e "XPACK_MONITORING_ENABLED=false" \
-e "XPACK_MONITORING_ELASTICSEARCH_USERNAME=elastic" \
-e "XPACK_MONITORING_ELASTICSEARCH_PASSWORD=changeme" \
logstash:7.13.4
From the Logstash STDOUT we can now see that the data was ingested:
{
"path" => "/usr/share/logstash/payment.json",
"@timestamp" => 2021-07-31T13:10:41.370Z,
"timestamp" => "2019-08-11T17:55:56Z",
"@version" => "1",
"paymentType" => "WeChat",
"gender" => "Female",
"age" => 34,
"country" => "Japan",
"ip_address" => "77.72.239.47",
"id" => 2,
"purpose" => "Shoes",
"host" => "debian11",
"message" => "{\"id\":2,\"timestamp\":\"2019-08-11T17:55:56Z\",\"paymentType\":\"WeChat\",\"name\":\"Yuki Calvaire\",\"gender\":\"Female\",\"ip_address\":\"77.72.239.47\",\"purpose\":\"Shoes\",\"country\":\"Japan\",\"age\":34}",
curl 'localhost:9200/payment-json/_search?pretty=true'
Data Mutation
Again we can drop meta fields that we don't need with a Mutation section and also add an IF Statement to exclude payment options we don't care about:
input {
file {
path => "/usr/share/logstash/payment.json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
if [paymentType] == "Mastercard" {
drop{}
}
mutate {
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-json-clean"
}
stdout {}
}
And this cleaned up our index nicely:
{
"paymentType" => "WeChat",
"country" => "Japan",
"gender" => "Female",
"age" => 34,
"purpose" => "Shoes",
"timestamp" => "2019-08-11T17:55:56Z",
"id" => 2,
"ip_address" => "77.72.239.47",
"name" => "Yuki Calvaire"
}
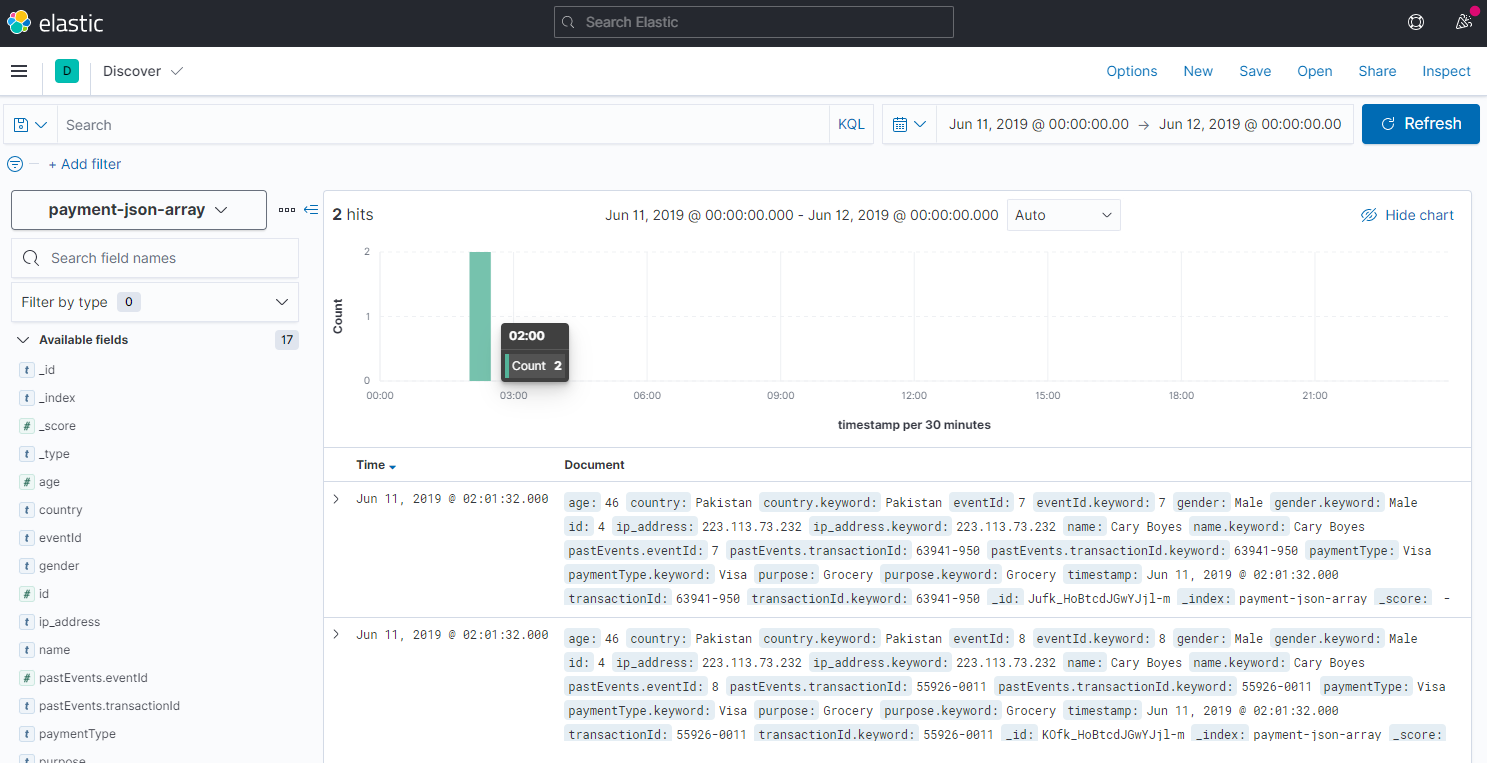
Splitting Arrays
If your JSON Data contains arrays (see pastEvents):
{"id":1,"timestamp":"2019-06-19T23:04:47Z","paymentType":"Mastercard","name":"Ardis Shimuk","gender":"Female","ip_address":"91.33.132.38","purpose":"Home","country":"France","pastEvents":[{"eventId":1,"transactionId":"trx14224"},{"eventId":2,"transactionId":"trx23424"}],"age":34}
{"id":2,"timestamp":"2019-11-26T15:40:56Z","paymentType":"Amex","name":"Benoit Urridge","gender":"Male","ip_address":"26.71.230.228","purpose":"Shoes","country":"Brazil","pastEvents":[{"eventId":3,"transactionId":"63323-064"},{"eventId":4,"transactionId":"0378-3120"}],"age":51}
{"id":3,"timestamp":"2019-05-08T16:24:25Z","paymentType":"Visa","name":"Lindsy Ketchell","gender":"Female","ip_address":"189.216.71.184","purpose":"Home","country":"Brazil","pastEvents":[{"eventId":5,"transactionId":"68151-3826"},{"eventId":6,"transactionId":"52125-611"}],"age":26}
{"id":4,"timestamp":"2019-06-10T18:01:32Z","paymentType":"Visa","name":"Cary Boyes","gender":"Male","ip_address":"223.113.73.232","purpose":"Grocery","country":"Pakistan","pastEvents":[{"eventId":7,"transactionId":"63941-950"},{"eventId":8,"transactionId":"55926-0011"}],"age":46}
{"id":5,"timestamp":"2020-02-18T12:27:35Z","paymentType":"Visa","name":"Betteanne Diament","gender":"Female","ip_address":"159.148.102.98","purpose":"Computers","country":"Brazil","pastEvents":[{"eventId":9,"transactionId":"76436-101"},{"eventId":10,"transactionId":"55154-3330"}],"age":41}
You can create the /opt/logstash/pipeline/logstash.conf file with an additional Split Section to expand the data structure:
input {
file {
#type => "json"
path => "/usr/share/logstash/payment-array.json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
split {
field => "[pastEvents]"
}
mutate {
add_field => {
"eventId" => "%{[pastEvents][eventId]}"
"transactionId" => "%{[pastEvents][transactionId]}"
}
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-json-array"
}
stdout {}
}
And run Logstash with the new configuration file:
docker run \
--name logstash \
--net=host \
--rm -it \
-v /opt/logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /opt/logstash/payment-array.json:/usr/share/logstash/payment-array.json \
-e "ELASTIC_HOST=localhost:9200" \
-e "XPACK_SECURITY_ENABLED=false" \
-e "XPACK_REPORTING_ENABLED=false" \
-e "XPACK_MONITORING_ENABLED=false" \
-e "XPACK_MONITORING_ELASTICSEARCH_USERNAME=elastic" \
-e "XPACK_MONITORING_ELASTICSEARCH_PASSWORD=changeme" \
logstash:7.13.4
The result is, that every entry will be split in two:
{
"country" => "Brazil",
"purpose" => "Home",
"age" => 26,
"ip_address" => "189.216.71.184",
"pastEvents" => {
"eventId" => 5,
"transactionId" => "68151-3826"
},
"gender" => "Female",
"timestamp" => "2019-05-08T16:24:25Z",
"name" => "Lindsy Ketchell",
"paymentType" => "Visa",
"id" => 3
}
{
"country" => "Brazil",
"purpose" => "Home",
"age" => 26,
"ip_address" => "189.216.71.184",
"pastEvents" => {
"eventId" => 6,
"transactionId" => "52125-611"
},
"gender" => "Female",
"timestamp" => "2019-05-08T16:24:25Z",
"name" => "Lindsy Ketchell",
"paymentType" => "Visa",
"id" => 3
}
We can now also extract the eventId and transactionId - to get rid of the pastEvents key all together:
input {
file {
#type => "json"
path => "/usr/share/logstash/payment-array.json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
split {
field => "[pastEvents]"
}
mutate {
add_field => {
"eventId" => "%{[pastEvents][eventId]}"
"transactionId" => "%{[pastEvents][transactionId]}"
}
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "payment-json-array"
}
stdout {}
}
And the result is:
{
"ip_address" => "189.216.71.184",
"timestamp" => "2019-05-08T16:24:25Z",
"purpose" => "Home",
"gender" => "Female",
"age" => 26,
"country" => "Brazil",
"id" => 3,
"pastEvents" => {
"transactionId" => "68151-3826",
"eventId" => 5
},
"transactionId" => "68151-3826",
"eventId" => "5",
"paymentType" => "Visa",
"name" => "Lindsy Ketchell"
}
{
"ip_address" => "189.216.71.184",
"timestamp" => "2019-05-08T16:24:25Z",
"purpose" => "Home",
"gender" => "Female",
"age" => 26,
"country" => "Brazil",
"id" => 3,
"pastEvents" => {
"transactionId" => "52125-611",
"eventId" => 6
},
"transactionId" => "52125-611",
"eventId" => "6",
"paymentType" => "Visa",
"name" => "Lindsy Ketchell"
}