Python Ray Basic Concepts

see Youtube Ray: A General Purpose Serverless Substrate? - Eric Liang, Anyscale
- Github Repository
- Python Ray Remote Functions
- Python Ray Remote Actors
- Python Ray Deployments
- Python Ray Model Serving
Ray is a unified framework for scaling AI and Python applications. Ray consists of a core distributed runtime and a toolkit of libraries (Ray AIR) for simplifying ML compute.
In a cloud computing model, the cloud provider allocates machine resources on demand, taking care of the servers on behalf of its customers. Ray provides a great foundation for general-purpose serverless platforms by providing the following features:
- Ray autoscaling transparently manages hardware resources while hiding the actual servers.
- With
actorsRay not only implements a stateless but also a stateful programming model. - It allows you to specify resources, including hardware accelerators.
- It supports direct communications between your tasks.
Installation
Setting up a local Single Node "Cluster". There are two versions that can be installed via pip. You cannot install it with pip install ray if you want to use the dashboard. Use the following to install Ray with the proper dependencies:
pip install -U "ray[default]"
You can access the dashboard through a URL printed when Ray is initialized (the default URL is http://localhost:8265).
To use Ray’s AI Runtime install Ray with the optional extra air packages:
pip install "ray[air]"
Hello World
Ray Remote (Task/Futures)
Execute a remote function that reports back where it was executed:
import os
import socket
def hello_from():
print( f"Running on {socket.gethostname()} in pid {os.getpid()}" )
return
hello_from()
You can use the ray.remote decorator to create a remote function. Ray returns a
future. You can get the values returned in those futures with ray.get:
import ray
import os
import socket
@ray.remote
def hello_from():
return f"Running on {socket.gethostname()} in pid {os.getpid()}"
future = hello_from.remote()
ray.get(future)
I am going to add the following lines to pause the execution - giving me some time to explore the Ray dashboard:
os.system("/bin/bash -c 'read -s -n 1 -p \"Press any key to continue...\"'")
print()
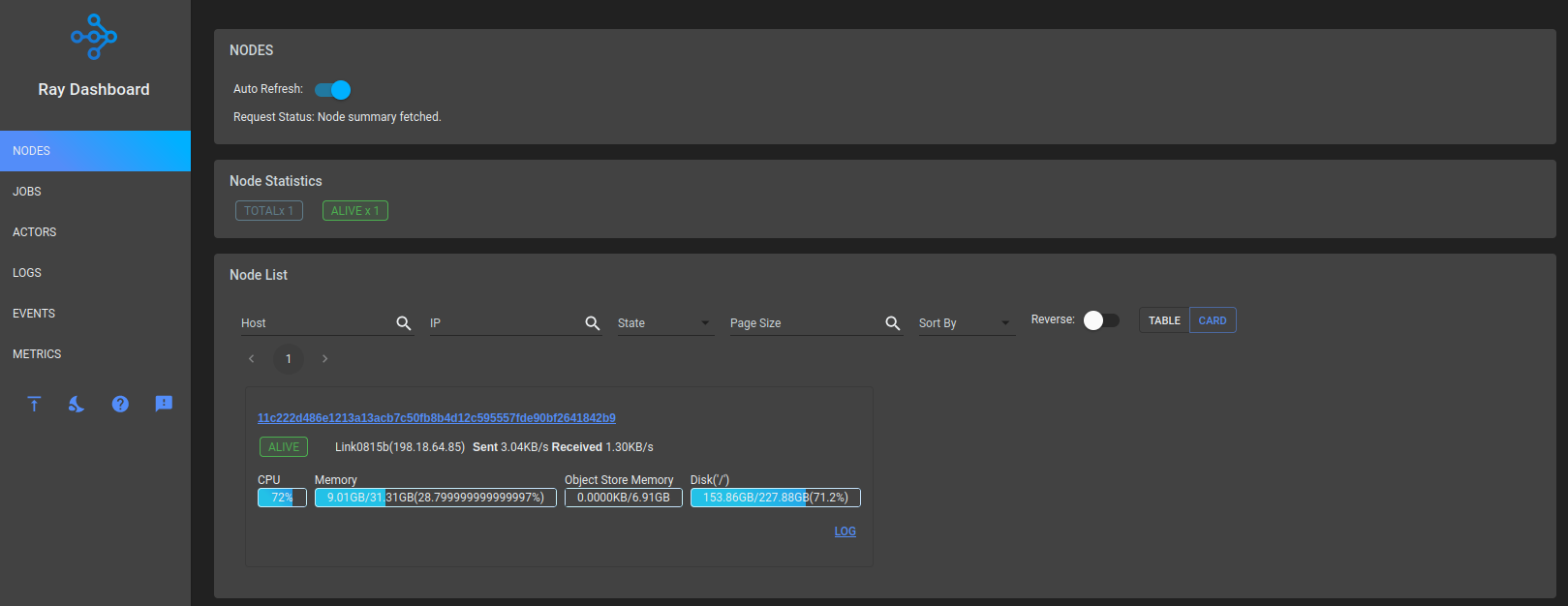
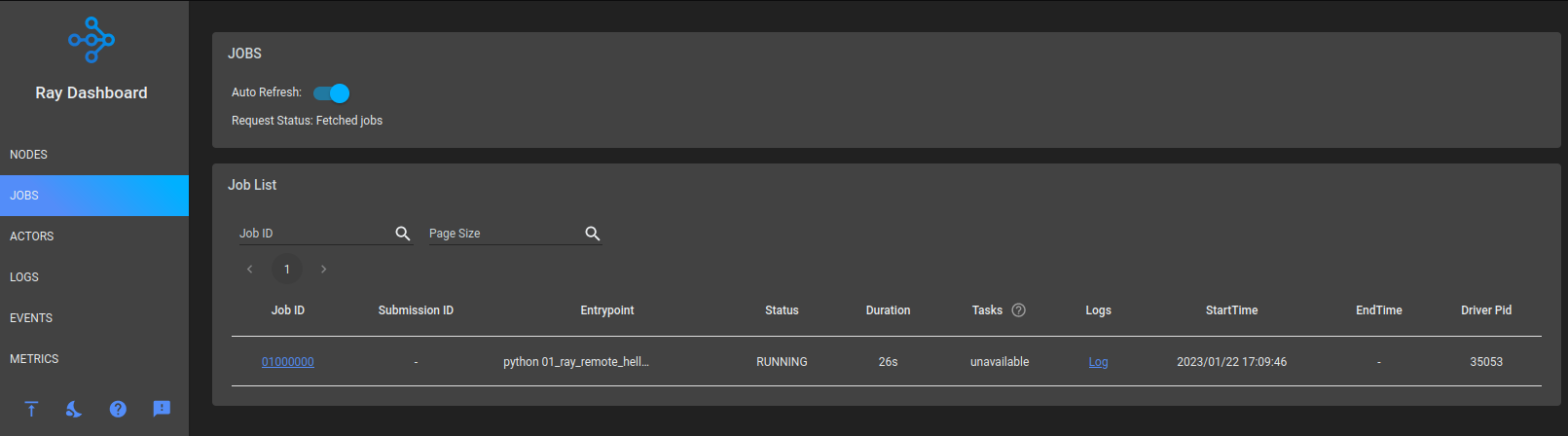
Since we are running Ray locally the remote function is executed "remotely" in a separate process:
Running on Link0815b in pid 35053
2023-01-22 17:09:45,201 INFO worker.py:1529 -- Started a local Ray instance.
View the dashboard at 127.0.0.1:8265
Running on Link0815b in pid 35278
Press any key to continue...
Nested Remote Functions
from bs4 import BeautifulSoup
import ray
import requests
@ray.remote
def crawl(url, depth=0, maxdepth=2, maxlinks=5):
# prepare arrays for scraped links / futures
links = []
link_futures = []
try:
# get target url
f = requests.get(url)
# add found URL to link array
links += [url]
# continue following till max depth
if (depth > maxdepth):
return links
# run web scraper on target url
soup = BeautifulSoup(f.text, 'html.parser')
i = 0
# follow links and and find more links
for link in soup.find_all('a'):
try:
i = i+1
link_futures += [crawl.remote(link["href"], depth=(depth+1), maxdepth=maxdepth)]
if i > maxlinks:
break
except:
pass
# add links and title to array
for r in ray.get(link_futures):
links += r
return links
except requests.exceptions.InvalidSchema:
return [] # Skip on invalid links
except requests.exceptions.MissingSchema:
return [] # Skip on invalid links
print(ray.get(crawl.remote("https://wiki.instar.com/en/Assistants/Review_Wall/")))
The nested call returns an array of all the links that were found on the target URL and on pages found at the end of those links (within the set limitations of max links and depth):
['https://wiki.instar.com/en/Assistants/Review_Wall/', 'https://forum.instar.de', 'https://youtu.be/l3EF_JgdGQg', 'https://www.youtube.com/about/', 'https://www.youtube.com/howyoutubeworks/', 'https://www.youtube.com/creators/', 'https://www.youtube.com/trends/', 'https://blog.youtube/', 'https://www.youtube.com/about/press/', 'https://www.youtube.com/about/copyright/', 'https://youtu.be/Ac1trrZhu9o', 'https://www.youtube.com/about/', 'https://www.youtube.com/howyoutubeworks/', 'https://www.youtube.com/creators/', 'https://www.youtube.com/trends/', 'https://blog.youtube/', 'https://www.youtube.com/about/press/', 'https://www.youtube.com/about/copyright/', 'https://youtu.be/6N0FATzh1BU', 'https://www.youtube.com/about/', 'https://www.youtube.com/howyoutubeworks/', 'https://www.youtube.com/creators/', 'https://www.youtube.com/trends/', 'https://blog.youtube/', 'https://www.youtube.com/about/press/', 'https://www.youtube.com/about/copyright/', 'https://youtu.be/2t7Y7I6l6A0', 'https://www.youtube.com/about/', 'https://www.youtube.com/howyoutubeworks/', 'https://www.youtube.com/creators/', 'https://www.youtube.com/trends/', 'https://blog.youtube/', 'https://www.youtube.com/about/press/', 'https://www.youtube.com/about/copyright/']
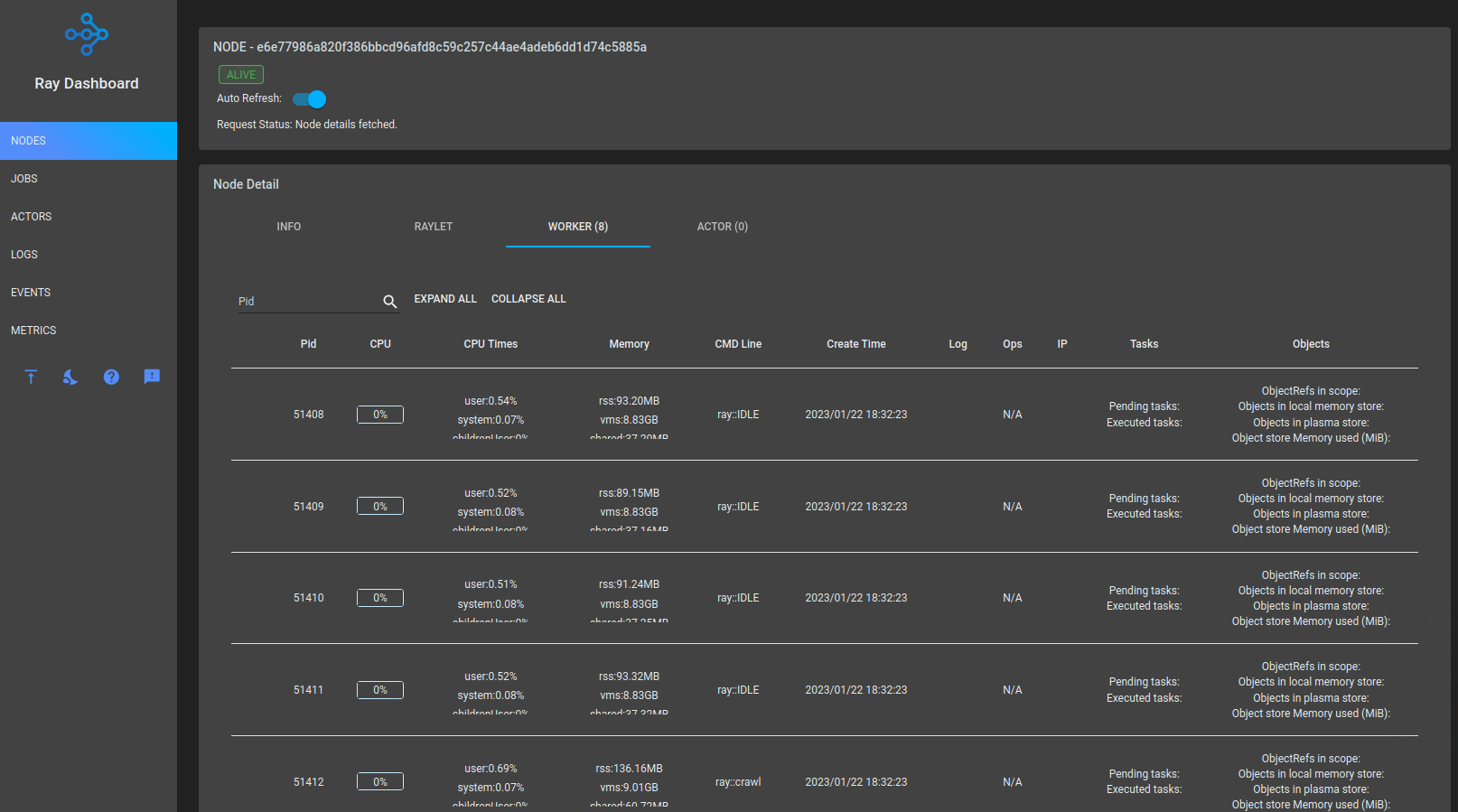
I can see that up to 10 worker processes are spawned to work on this task - if I increase the number of links and depth of the search the amount of worker increases as well:
Ray Datasets - Distributed Data Preprocessing
Ray Datasets are the standard way to load and exchange data in Ray libraries and applications. They provide basic distributed data transformations such as maps (map_batches), global and grouped aggregations (GroupedDataset), and shuffling operations (random_shuffle, sort, repartition), and are compatible with a variety of file formats, data sources, and distributed frameworks.
Let's create a dataset from the URLs we just downloaded:
import ray
import requests
# use list of urls created above
dataset=["https://wiki.instar.com/en/Assistants/Review_Wall/", "https://forum.instar.de", "https://youtu.be/l3EF_JgdGQg", "https://www.youtube.com/about/", "https://www.youtube.com/howyoutubeworks/", "https://www.youtube.com/creators/", "https://www.youtube.com/trends/", "https://blog.youtube/", "https://www.youtube.com/about/press/", "https://www.youtube.com/about/copyright/", "https://youtu.be/Ac1trrZhu9o", "https://www.youtube.com/about/", "https://www.youtube.com/howyoutubeworks/", "https://www.youtube.com/creators/", "https://www.youtube.com/trends/", "https://blog.youtube/", "https://www.youtube.com/about/press/", "https://www.youtube.com/about/copyright/", "https://youtu.be/6N0FATzh1BU", "https://www.youtube.com/about/", "https://www.youtube.com/howyoutubeworks/", "https://www.youtube.com/creators/", "https://www.youtube.com/trends/", "https://blog.youtube/", "https://www.youtube.com/about/press/", "https://www.youtube.com/about/copyright/", "https://youtu.be/2t7Y7I6l6A0", "https://www.youtube.com/about/", "https://www.youtube.com/howyoutubeworks/", "https://www.youtube.com/creators/", "https://www.youtube.com/trends/", "https://blog.youtube/", "https://www.youtube.com/about/press/", "https://www.youtube.com/about/copyright/"]
# and create a dataset from them
urls = ray.data.from_items(dataset)
# download all pages
def get_page(url):
f = requests.get(url)
return f.text
# map url dataset and get page content
pages = urls.map(get_page)
# verify that pages where downloaded
# print(pages.take(1))
ERROR:
ModuleNotFoundError: No module named 'pkg_resources._vendor'solved bypip install --upgrade setuptools.
By calling groupby with either a column name or a function that returns a key, you get a GroupedDataset. GroupedDataset has built-in support for count, max, min, and other common aggregations:
# split page content into words
words = pages.flat_map(lambda x: x.split(" ")).map(lambda w: (w, 1))
# create GroupedDataset
grouped_words = words.groupby(lambda wc: wc[0])
# take a look at it
print('Generated Data: ', grouped_words)
Map: 100%|████████████████████████████████| 34/34 [00:05<00:00, 5.71it/s]
Flat_Map: 100%|███████████████████████████| 34/34 [00:00<00:00, 92.36it/s]
Map: 100%|████████████████████████████████| 34/34 [00:00<00:00, 45.92it/s]
Generated Data: GroupedDataset(dataset=Dataset(num_blocks=34, num_rows=900977, schema=<class 'tuple'>), key=<function <lambda> at 0x7fbe21277be0>)
Ray Actors
Actors extend the Ray API from functions (tasks) to classes. An actor is essentially a stateful worker (or a service). Actors send and receive messages, updating their state in response. These messages can come from other actors, programs, or the Ray main execution thread with the Ray client. Just like before in Ray the actor will return a future that you can then collect on later.
Ray Actors are very similar to Remote Functions but use Python classes to handle state. They can be used to retrieve the newest weights from your running ML training or - for example - get the latest sensor read-out from your IoT device:
import ray
@ray.remote
class ReadSensor(object):
def __init__(self):
self.value = 0
def get_value(self):
self.value += 1
return f"Current value is: {self.value}"
# create an actor instance
sensor_reading = ReadSensor.remote()
# call the actor multiple times
print(ray.get(sensor_reading.get_value.remote()))
print(ray.get(sensor_reading.get_value.remote()))
print(ray.get(sensor_reading.get_value.remote()))
print(ray.get(sensor_reading.get_value.remote()))
print(ray.get(sensor_reading.get_value.remote()))
By requesting the value multiple times we increment the value itself. The next returned value we get reflects the change:
python 04_ray_actors_distributed_state.py
2023-01-22 21:47:50,961 INFO worker.py:1529 -- Started a local Ray instance.
View the dashboard at 127.0.0.1:8265
Current value is: 1
Current value is: 2
Current value is: 3
Current value is: 4
Current value is: 5