MLFlow Docker
This is just an experiment to see if I can use MLFlow inside my pytorch-jupyter Docker container. To do this I added MLFlow to the Dockerfile:
FROM pytorch/pytorch:latest
# Set environment variables
ENV DEBIAN_FRONTEND=noninteractive
# Install system dependencies
RUN apt-get update && \
apt-get install -y \
git \
tini \
python3-pip \
python3-dev \
python3-opencv \
libglib2.0-0
# intall optional python deps
RUN python -m pip install --upgrade pip
# jupyter notebooks
RUN pip install jupyter
# fastdup https://github.com/visual-layer/fastdup
RUN pip install fastdup
RUN pip install opencv-python
RUN pip install matplotlib matplotlib-inline pandas
RUN pip install pillow
RUN pip install pyyaml
# YOLO 8.1
RUN pip install ultralytics Cython>=0.29.32 lapx>=0.5.5
# MLFlow 2.10
RUN pip install mlflow pytorch_lightning
# Set the working directory
WORKDIR /opt/app
# Start the notebook
RUN chmod +x /usr/bin/tini
ENTRYPOINT ["/usr/bin/tini", "--"]
CMD ["jupyter", "notebook", "--port=8888", "--no-browser", "--ip=0.0.0.0", "--allow-root"]
Let's build this custom image with:
docker build -t pytorch-jupyter . -f Dockerfile
I can now create the container and mount my working directory into the container WORKDIR to get started:
docker run --ipc=host --gpus all -ti --rm \
-v $(pwd):/opt/app -p 8888:8888 -p 5000:5000 \
--name pytorch-jupyter \
pytorch-jupyter:latest
This will start Jupyter on Port 8888 and I can start MLFlow manually:
docker exec -ti pytorch-jupyter mlflow ui --host 0.0.0.0
The MLFlow is now available on localhost:5000 on my host system:
Just to be sure I stop MLFlow and try to run it directly from a Jupyter Notebook:
get_ipython().system_raw("mlflow ui --port 5000 --host 0.0.0.0 &")
And the UI is still available on localhost:5000 - nice:
Create an MLFlow Experiment
experiment_name = "emnist_classifier_dnn"
mlflow.create_experiment(experiment_name)
mlflow.set_experiment(experiment_name)
Dataset
Starting a classification run on the EMNIST Handwritten Character Set:
emnist_train_data = pd.read_csv("./datasets/emnist-letters-train.csv", header=None)
emnist_test_data = pd.read_csv("./datasets/emnist-letters-test.csv", header=None)
emnist_test_data = emnist_test_data.sample(frac=1)
# extract labels
train_labels = emnist_train_data.values[:, 0]
train_images = emnist_train_data.values[:, 1:]
# reshape image to the original 28x28 shape
train_images = train_images.reshape(-1, 28, 28)
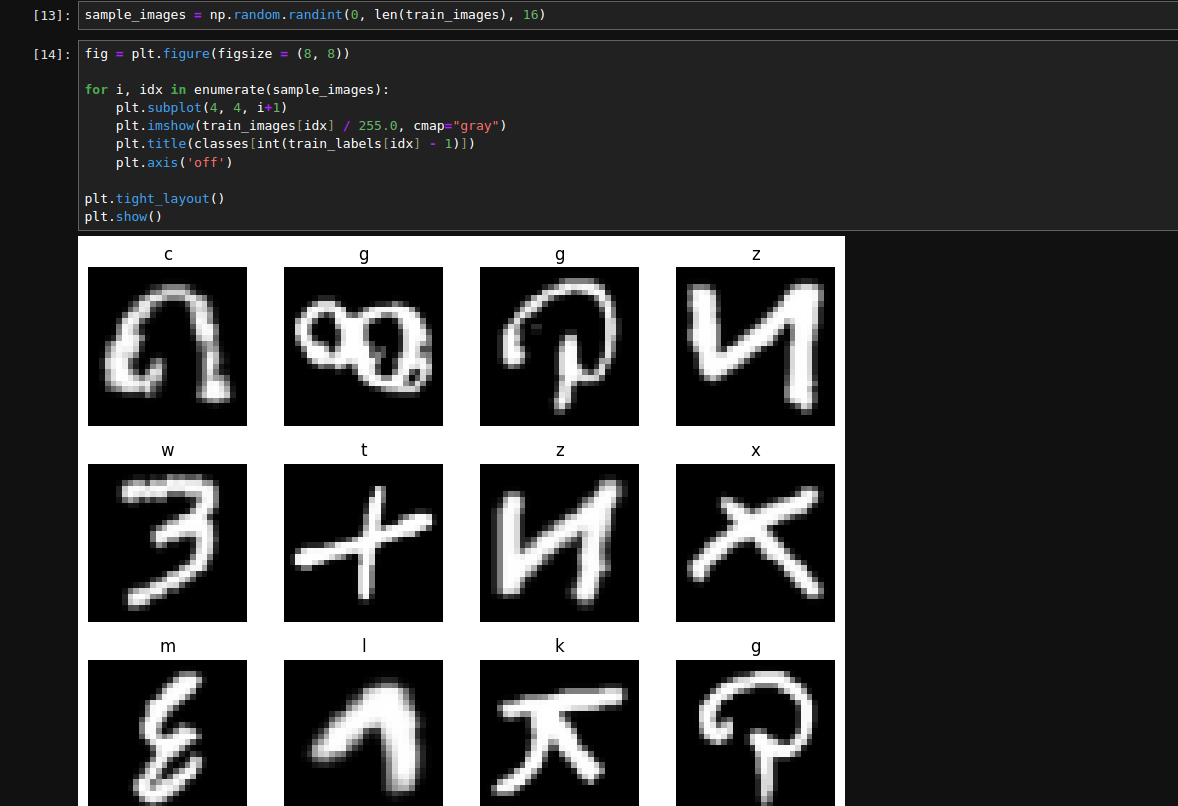
dataset_info = """
The EMNIST dataset is a set of handwritten character digits derived from the NIST Special Database 19 and converted to a 28x28 pixel image format and dataset structure that directly matches the MNIST dataset . Further information on the dataset contents and conversion process can be found in the paper available at https://arxiv.org/abs/1702.05373v1
"""
with open("dataset_info.txt", "w") as f:
f.write(dataset_info)
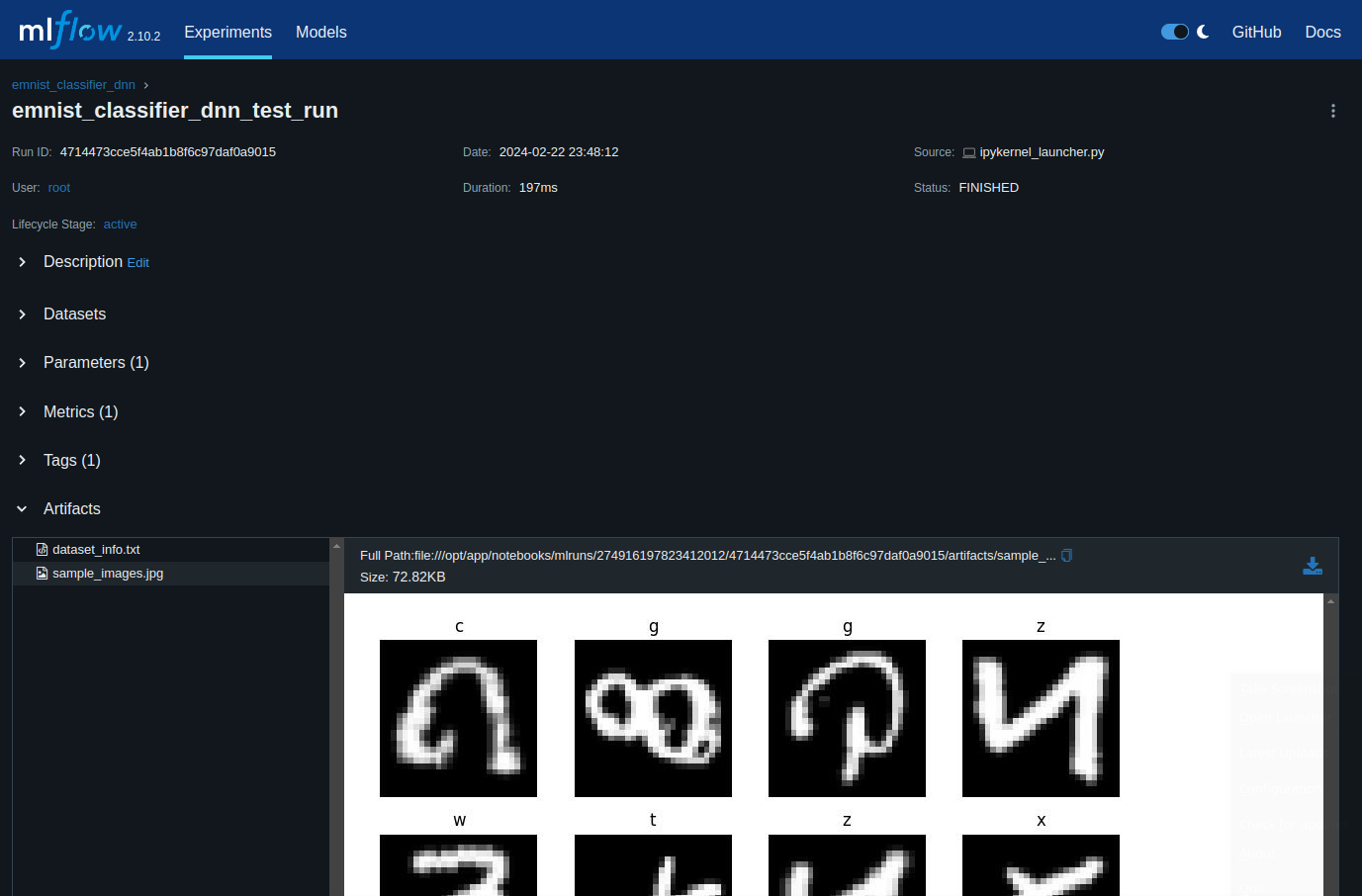
with mlflow.start_run(run_name = 'emnist_classifier_dnn_test_run') as current_run:
mlflow.log_metric('Accuracy', 0.67)
params = {
'num_nn_layers': 4
}
mlflow.log_params(params)
mlflow.log_figure(fig, 'sample_images.jpg')
mlflow.log_artifact('dataset_info.txt')
mlflow.set_tag('EMNIST', 'Character Classification')
Perform a train/test/val split and prepare the dataloaders needed for the model training:
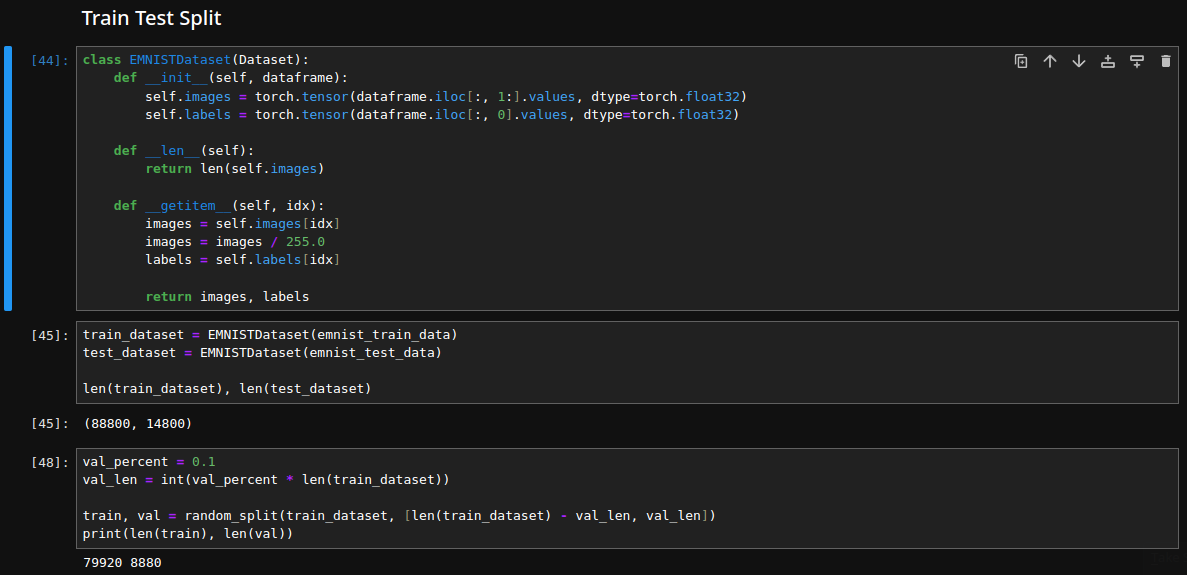
train_dl = DataLoader(train, BATCH_SIZE, shuffle=True, drop_last=True, num_workers=1)
val_dl = DataLoader(val, BATCH_SIZE, num_workers=1)
test_dl = DataLoader(test_dataset, BATCH_SIZE, num_workers=1)
dataiter = iter(train_dl)
batch_images, batch_labels = next(dataiter)
Model Training
class EmnistModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.criterion = nn.CrossEntropyLoss()
self.linear1 = nn.Linear(INPUT_SIZE, 512)
self.linear2 = nn.Linear(512, 128)
self.linear3 = nn.Linear(128, 32)
self.linear4 = nn.Linear(32, OUTPUT_SIZE)
def forward(self, xb):
out = self.linear1(xb)
out = F.relu(out)
out = self.linear2(out)
out = F.relu(out)
out = self.linear3(out)
out = F.relu(out)
out = self.linear4(out)
return out
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr = 0.0001)
def training_step(self, batch, batch_idx):
# batches consists of images and labels
x, y = batch
# labels start at 1 but the classes at 0
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim = 1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("train_loss", loss, on_epoch=True, prog_bar=True)
self.log("train_acc", acc, on_epoch=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim=1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("val_loss", loss, on_epoch=True, prog_bar=True)
self.log("val_acc", acc, on_epoch=True, prog_bar=True)
return acc
def test_step(self, batch, batch_idx):
x, y = batch
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim=1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("test_loss", loss, on_epoch=True, prog_bar=True)
self.log("test_acc", acc, on_epoch=True, prog_bar=True)
return acc
def predict_step(self, batch, batch_idx, dataloaders_idx=0):
x, y = batch
return self(x)
emnist_model = EmnistModel()
logger = CSVLogger("logs", name="emnist_classifier_dnn")
trainer = pl.Trainer(max_epochs = 10, logger=logger)
mlflow.pytorch.autolog(log_models = False)
with mlflow.start_run() as run:
trainer.fit(emnist_model, train_dl, val_dl)
trainer.test(dataloaders = test_dl)
input_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 784))])
output_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 26))])
signature = ModelSignature(inputs = input_schema, outputs = output_schema)
mlflow.pytorch.log_model(emnist_model, "emnist_classifier_dnn", signature = signature)
# ───────────────────────────────────────────────
# Test metric DataLoader 0
# ───────────────────────────────────────────────
# test_acc 0.8519594669342041
# test_loss 0.4712047874927521
# ───────────────────────────────────────────────
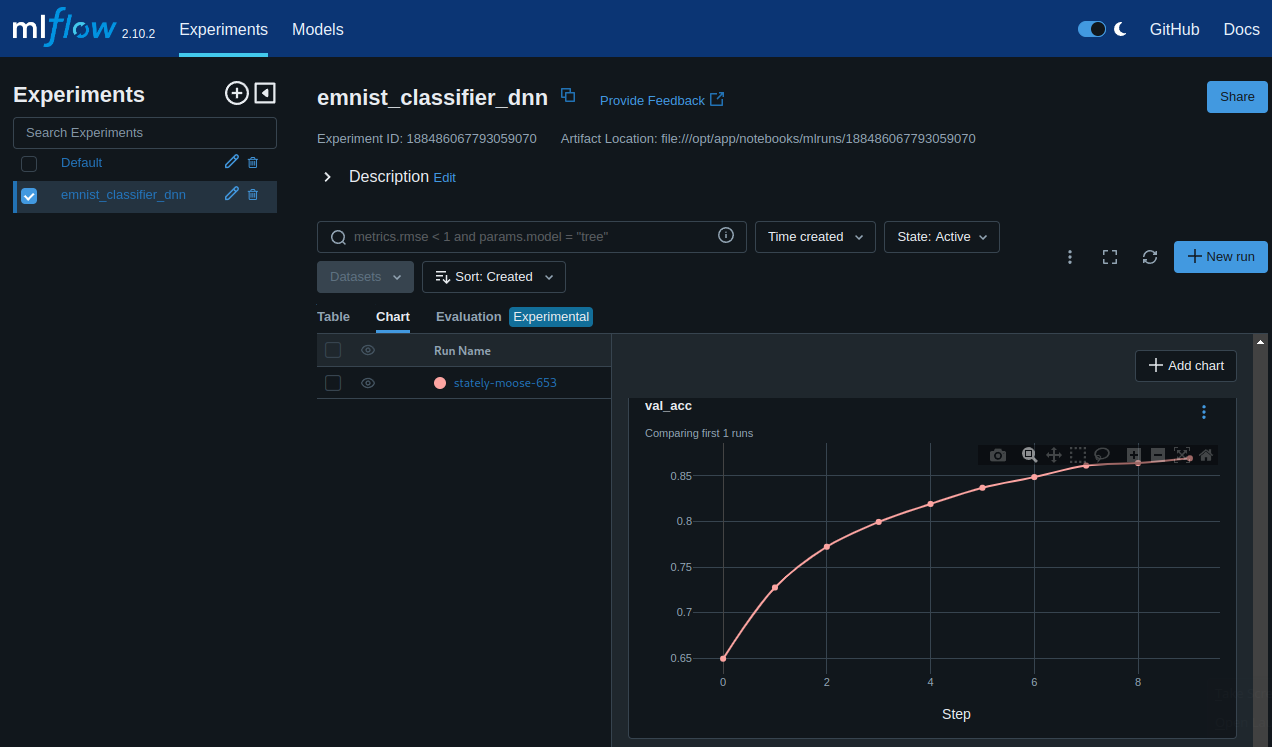
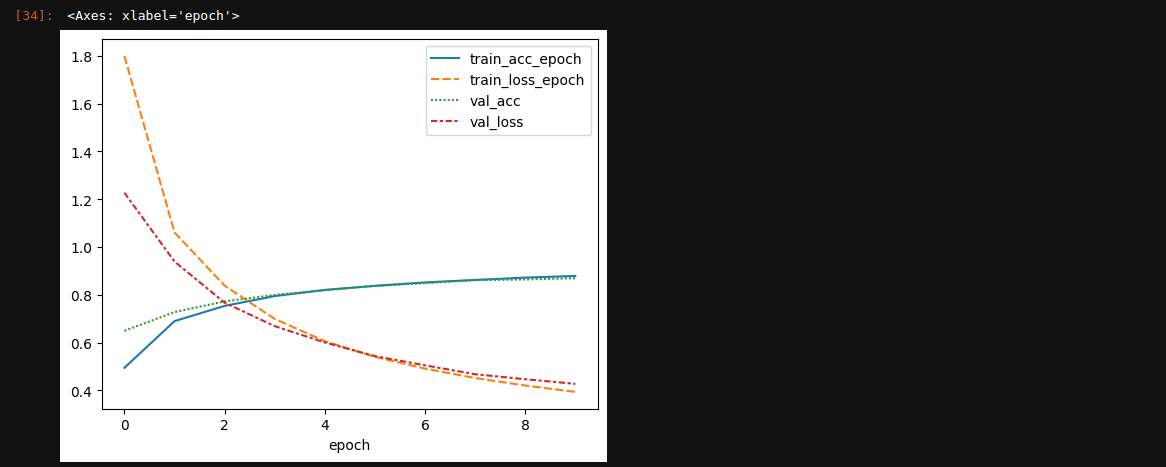
metrics = pd.read_csv(f"{trainer.logger.log_dir}/metrics.csv")
metrics.set_index("epoch", inplace=True)
metrics.drop(columns=['step', 'train_loss_step',
'train_acc_step', 'test_acc', 'test_loss'], inplace=True)
sns.lineplot(data=metrics)
Model Prediction
Get a sample set of test images:
test_dataiter = iter(test_dl)
test_images, test_labels = next(test_dataiter)
test_images.shape, test_labels.shape
Run them trough the trained model to return predictions:
model_path = f"runs:/{run_id}/emnist_classifier_dnn"
loaded_model = mlflow.pyfunc.load_model(model_path)
predictions = loaded_model.predict(test_images.numpy())
To display the prediction we first need to get the images back into shape:
# reshape image to the original 28x28 shape
test_images_reshaped = test_images.reshape(-1, 28, 28)
test_samples = np.random.randint(0, len(test_images_reshaped), 16)
Now we can plot them using Matplotlib:
fig = plt.figure(figsize = (8, 8))
for i, idx in enumerate(test_samples):
true_label = classes[int(test_labels[idx].item()) - 1]
pred_label = classes[np.argmax(predictions[idx])]
plt.subplot(4, 4, i+1)
plt.imshow(test_images[idx] / 255.0, cmap="gray")
plt.title(f"True: {true_label} || Pred: {pred_label}")
plt.axis('off')
plt.tight_layout()
plt.show()

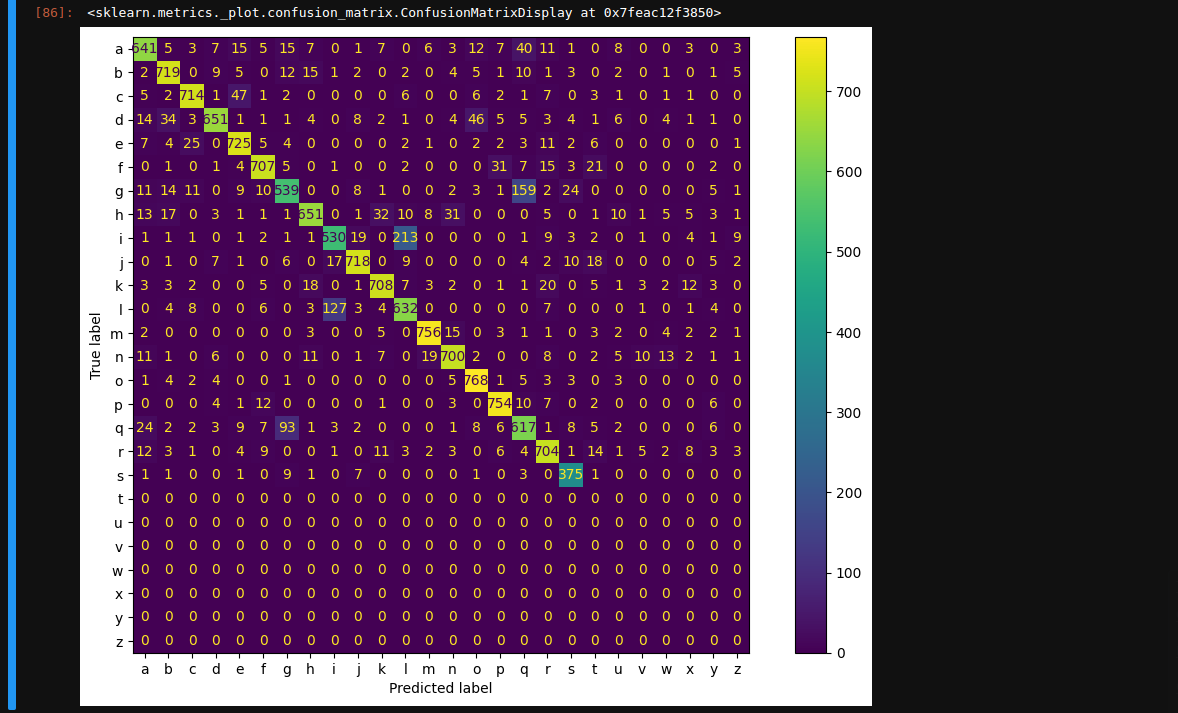
Verify the overall performance by creating a confusion matrix over all test predictions:
x_pred = []
y_true = []
for inputs, labels in test_dl:
output = loaded_model.predict(inputs.numpy())
output = np.argmax(output, axis=1).astype('float64').tolist()
y_pred.extend(output)
labels = [x-1 for x in labels.tolist()]
y_true.extend(labels)
cm = confusion_matrix(y_true, y_pred)
confusion = ConfusionMatrixDisplay(cm, display_labels=classes)
fig, ax = plt.subplots(figsize = (12,8))
confusion.plot(ax = ax)