MLflow 2.1 Introduction

MLflow is an open source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment and a central model registry. MLflow currently offers four components:
- MLflow Tracking: Record and query experiments: code, data, config, and results
- MLflow Projects: Package data science code in a format to reproduce runs on any platform
- MLflow Models: Deploy machine learning models in diverse serving environments
- Model Registry: Store, annotate, discover, and manage models in a central repository
Installing MLflow (PIP)
# Install MLflow
pip install mlflow
# Install MLflow with extra ML libraries and 3rd-party tools
pip install 'mlflow[extras]'
# Install a lightweight version of MLflow
pip install mlflow-skinny
To use certain MLflow modules and functionality (ML model persistence/inference, artifact storage options, etc), you may need to install extra libraries. For example, the mlflow.tensorflow module requires TensorFlow to be installed. See Extra Dependencies for more details.
When using MLflow skinny, you may need to install additional dependencies if you wish to use certain MLflow modules and functionalities. For example, usage of SQL-based storage for MLflow Tracking (e.g. mlflow.set_tracking_uri("sqlite:///my.db")) requires pip install mlflow-skinny sqlalchemy alembic sqlparse. If using MLflow skinny for serving, a minimally functional installation would require pip install mlflow-skinny flask`.
The MLFlow installation with extras contains the following:
Successfully installed Mako-1.2.4 PyJWT-2.6.0 PySocks-1.7.1 SecretStorage-3.3.3 adal-1.2.7 aiokafka-0.8.0 alembic-1.9.3 azure-common-1.1.28 azure-core-1.26.3 azure-graphrbac-0.61.1 azure-mgmt-authorization-3.0.0 azure-mgmt-containerregistry-10.0.0 azure-mgmt-core-1.3.2 azure-mgmt-keyvault-10.1.0 azure-mgmt-resource-21.2.1 azure-mgmt-storage-20.1.0 azureml-core-1.48.0 backports.tempfile-1.0 backports.weakref-1.0.post1 bcrypt-4.0.1 cryptography-38.0.4 databricks-cli-0.17.4 docker-6.0.1 fastapi-0.88.0 gevent-22.10.2 geventhttpclient-2.0.2 google-cloud-core-2.3.2 google-cloud-storage-2.7.0 google-crc32c-1.5.0 google-resumable-media-2.4.1 gunicorn-20.1.0 isodate-0.6.1 jeepney-0.8.0 jsonpickle-2.2.0 kafka-python-2.0.2 knack-0.10.1 kubernetes-25.3.0 llvmlite-0.39.1 mlflow-2.1.1 mlserver-1.3.0.dev2 mlserver-mlflow-1.3.0.dev2 msal-1.21.0 msal-extensions-1.0.0 msrest-0.7.1 msrestazure-0.6.4 ndg-httpsclient-0.5.1 numba-0.56.4 numpy-1.23.5 orjson-3.8.5 paramiko-2.12.0 pkginfo-1.9.6 portalocker-2.7.0 prometheus-flask-exporter-0.21.0 py-grpc-prometheus-0.7.0 pynacl-1.5.0 pyopenssl-22.1.0 pysftp-0.2.9 python-dotenv-0.21.1 python-rapidjson-1.9 querystring-parser-1.2.4 requests-auth-aws-sigv4-0.7 shap-0.41.0 slicer-0.0.7 sqlalchemy-1.4.46 sqlparse-0.4.3 starlette-exporter-0.15.1 tritonclient-2.30.0 uvloop-0.17.0 zope.event-4.6 zope.interface-5.5.2
Downloading the Quickstart
Download the quickstart code by cloning MLflow via and cd into the examples subdirectory of the repository. We’ll use this working directory for running the quickstart:
git clone https://github.com/mlflow/mlflow
cd mlflow/examples
Using the Tracking API
Viewing the Tracking UI
By default, wherever you run your program, the tracking API writes data into files into a local ./mlruns directory. You can then run MLflow’s Tracking UI on http://localhost:5000:
mlflow ui
python quickstart/mlflow_tracking.py
Running MLflow Projects
MLflow allows you to package code and its dependencies as a project that can be run in a reproducible fashion on other data. Each project includes its code and a MLproject file that defines its dependencies (for example, Python environment) as well as what commands can be run into the project and what arguments they take.
You can run existing projects with the mlflow run command, which runs a project from either a local directory:
mlflow run sklearn_elasticnet_wine -P alpha=0.5
or a GitHub URI:
mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=5.0
There’s a sample project in tutorial, including a MLproject file that specifies its dependencies. If you haven’t configured a tracking server yet, projects log their Tracking API data in the local mlruns directory so you can see these runs using mlflow ui.
If I try to run mlflow run sklearn_elasticnet_wine -P alpha=0.5 I get an error message FileNotFoundError: [Errno 2] No such file or directory: 'pyenv'. It seems that MLFlow expected to find a virtual environment with dependencies installed. The directory contains a python_env.yml file - I assume that all those dependencies would have been installed automatically if a virtEnv would have been present? Ah ok, there is the info:
By default
mlflow runinstalls all dependencies using virtualenv. To run a project without using virtualenv, you can provide the--env-manager=localoption tomlflow run. In this case, you must ensure that the necessary dependencies are already installed in your Python environment.
mlflow run --env-manager=local sklearn_elasticnet_wine -P alpha=0.5
Elasticnet model (alpha=0.500000, l1_ratio=0.100000):
RMSE: 0.7460550348172179
MAE: 0.576381895873763
R2: 0.21136606570632266
2023/02/09 13:32:42 INFO mlflow.projects: === Run (ID '886087767c9646b9824ec9315e63ac84') succeeded ===
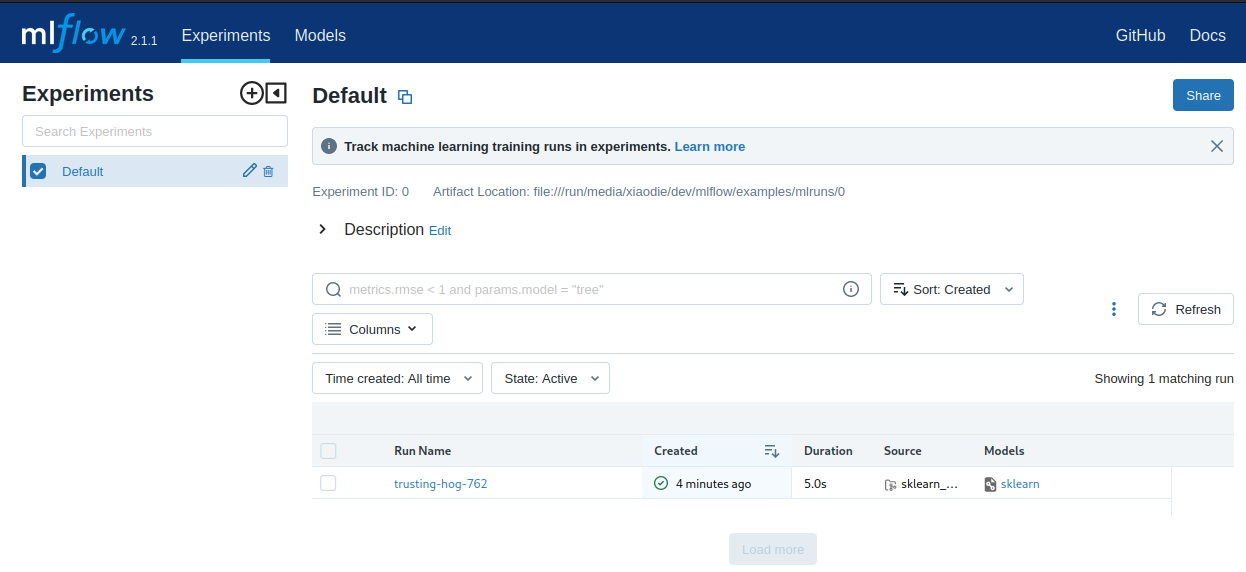
The run statistics will be stored in the mlruns dir inside the examples dir that we started this training from. So we can open the UI from here mlflow ui and should be able to see a new entry:
After the run MLFlow generated a a requirements.txt and python_env.yml file - based on my local environment:
mlruns/0/886087767c9646b9824ec9315e63ac84/artifacts/model/python_env.yaml
python: 3.10.9
build_dependencies:
- pip==22.3.1
- setuptools==66.1.1
- wheel==0.38.4
dependencies:
- -r requirements.txt
mlruns/0/886087767c9646b9824ec9315e63ac84/artifacts/model/requirements.txt
mlflow<3,>=2.1
cloudpickle==2.2.0
psutil==5.9.4
scikit-learn==1.2.0
typing-extensions==4.4.0
And also saved the pickled artifacts from our training:
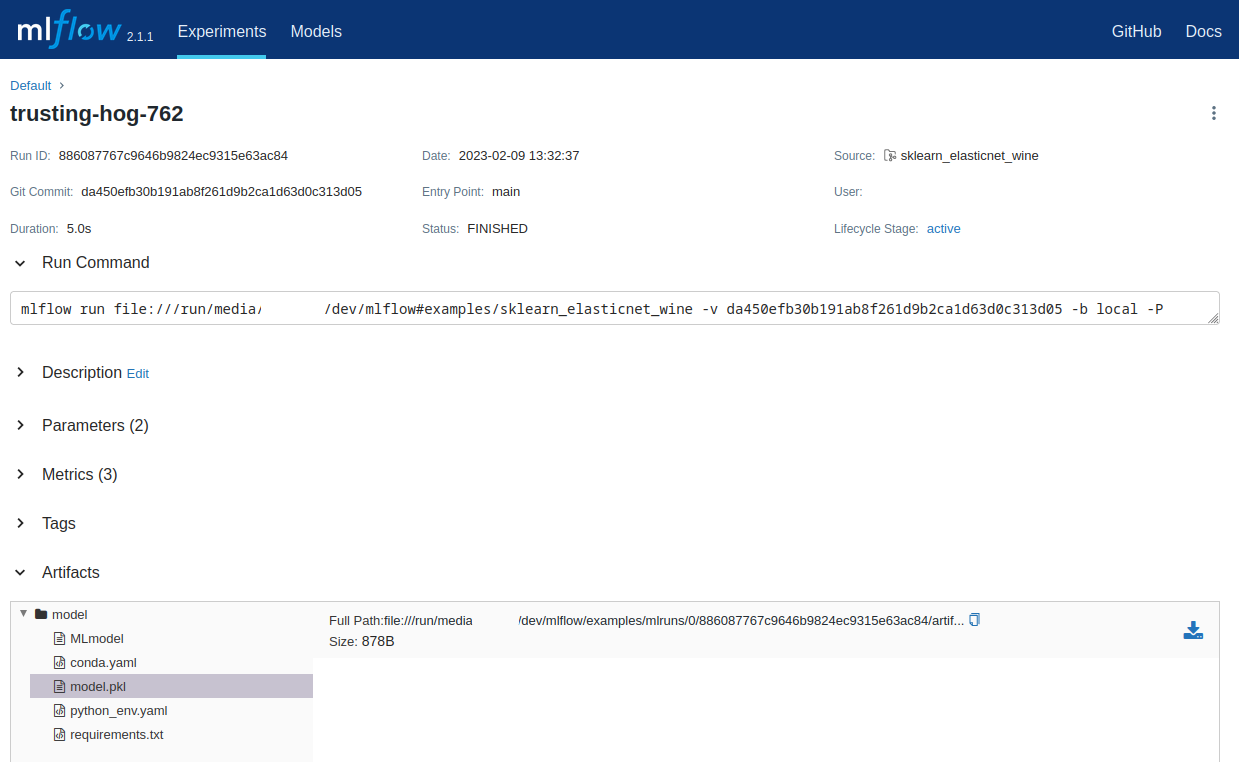
Saving and Serving Models
MLflow includes a generic MLmodel format for saving models from a variety of tools in diverse flavors. For example, many models can be served as Python functions, so an MLmodel file can declare how each model should be interpreted as a Python function in order to let various tools serve it. MLflow also includes tools for running such models locally and exporting them to Docker containers or commercial serving platforms.
To illustrate this functionality, the mlflow.sklearn package can log scikit-learn models as MLflow artifacts and then load them again for serving. There is an example training application in sklearn_logistic_regression/train.py that you can run as follows:
mlflow run --env-manager=local sklearn_logistic_regression
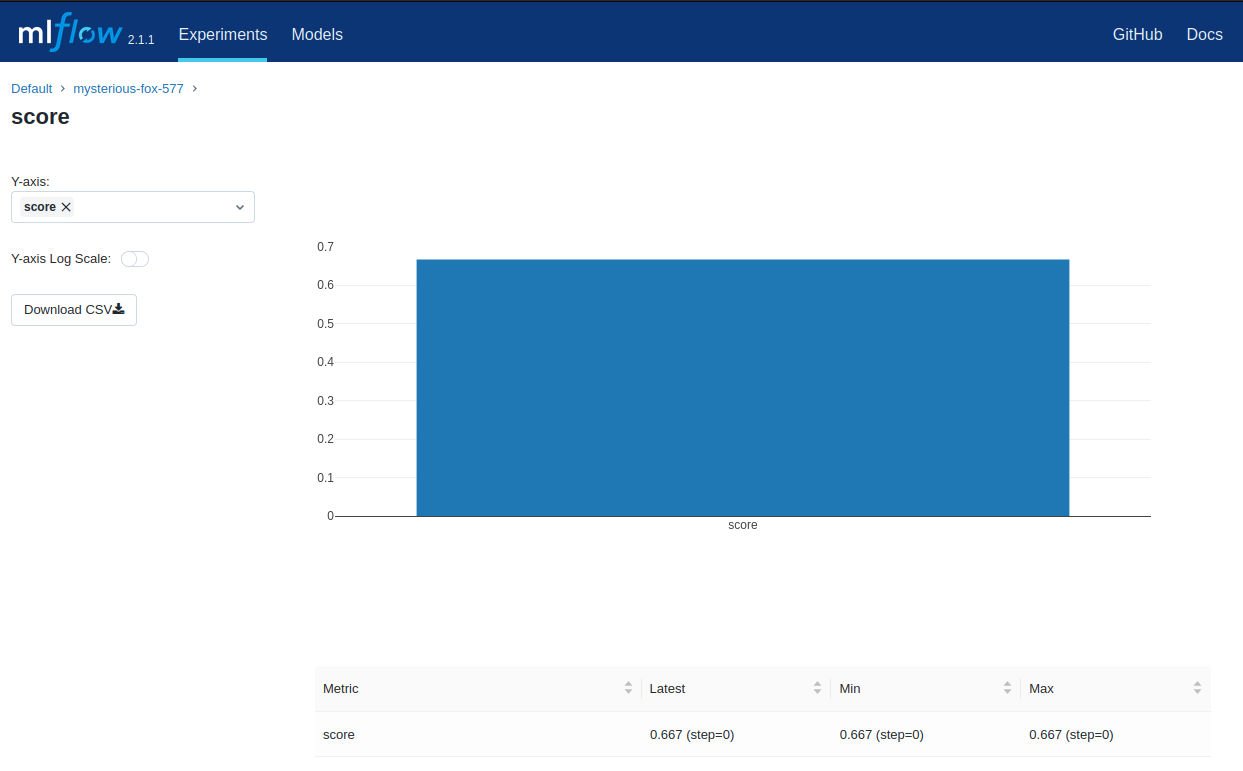
When you run the example, it outputs an MLflow run ID for that experiment. If you look at mlflow ui, you will also see that the run saved a model folder containing an MLmodel description file and a pickled scikit-learn model:
=== Running command 'python train.py' in run with ID 'ee566cd8d86b411f978c6e3db5d161cb' ===
Score: 0.6666666666666666
Model saved in run ee566cd8d86b411f978c6e3db5d161cb
=== Run (ID 'ee566cd8d86b411f978c6e3db5d161cb') succeeded ===
You can pass the run ID and the path of the model within the artifacts directory (here “model”) to various tools. For example, MLflow includes a simple REST server for python-based models - mlflow models serve -m runs:/<RUN_ID>/model:
mlflow models serve --env-manager=local -m runs:/ee566cd8d86b411f978c6e3db5d161cb/model --port 8080
The REST API defines 4 endpoints:
/ping: used for health check/health: (same as /ping)/version: used for getting the mlflow version/invocations: used for scoring
Once you have started the server, you can pass it some sample data and see the predictions:
curl -d '{"dataframe_split": {"columns": ["x"], "data": [[1], [-1]]}}' -H 'Content-Type: application/json' -X POST localhost:8080/invocations
This returns:
{"predictions": [1, 0]}