
AutoML with AutoGluon for Tabular Data
- Part 1: AutoML with AutoGluon for Tabular Data
- Part 2: AutoML with AutoGluon for Multi-Modal Data
- Part 3: AutoML with AutoGluon for Timeseries Forecasts
AutoGluon automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy machine learning and deep learning models on image, text, time series, and tabular data.
- AutoML with AutoGluon for Tabular Data
Installation
Installing AutoGluon with GPU support:
pip install -U pip
pip install -U setuptools wheel
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
pip install autogluon
# for visualizations
pip install bokeh==2.0.1"
Tabular Data Classification
# get dataset
!wget https://github.com/mpolinowski/hotel-booking-dataset/raw/master/datasets/hotel_bookings.csv -P datase
from autogluon.tabular import TabularDataset, TabularPredictor
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
SEED = 42
MODEL_PATH = 'model'
Classification Model
Data Preprocessing
data = TabularDataset('dataset/hotel_bookings.csv')
data.head(5).transpose()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| hotel | Resort Hotel | Resort Hotel | Resort Hotel | Resort Hotel | Resort Hotel |
| is_canceled | 0 | 0 | 0 | 0 | 0 |
| lead_time | 342 | 737 | 7 | 13 | 14 |
| arrival_date_year | 2015 | 2015 | 2015 | 2015 | 2015 |
| arrival_date_month | July | July | July | July | July |
| arrival_date_week_number | 27 | 27 | 27 | 27 | 27 |
| arrival_date_day_of_month | 1 | 1 | 1 | 1 | 1 |
| stays_in_weekend_nights | 0 | 0 | 0 | 0 | 0 |
| stays_in_week_nights | 0 | 0 | 1 | 1 | 2 |
| adults | 2 | 2 | 1 | 1 | 2 |
| children | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| babies | Model Testingype | No Deposit | No Deposit | No Deposit | No Deposit |
| agent | NaN | NaN | NaN | 304.0 | 240.0 |
| company | NaN | NaN | NaN | NaN | NaN |
| days_in_waiting_list | 0 | 0 | 0 | 0 | 0 |
| customer_type | Transient | Transient | Transient | Transient | Transient |
| adr | 0.0 | 0.0 | 75.0 | 75.0 | 98.0 |
| required_car_parking_spaces | 0 | 0 | 0 | 0 | 0 |
| total_of_special_requests | 0 | 0 | 0 | 0 | 1 |
| reservation_status | Check-Out | Check-Out | Check-Out | Check-Out | Check-Out |
| reservation_status_date | 01-07-15 | 01-07-15 | 02-07-15 | 02-07-15 | 03-07-15 |
# the are two columns for the label is_canceled and reservation_status
# only keep one and make it the true label
data = data.drop(['is_canceled'], axis=1)
data = data.drop(['reservation_status_date'], axis=1)
data.info()
# <class 'autogluon.core.dataset.TabularDataset'>
# RangeIndex: 119390 entries, 0 to 119389
# Data columns (total 30 columns)
# take small random sample to get started => 10%
data_sample = data.sample(frac=0.1 , random_state=SEED)
data_sample.describe()
| | lead_time | arrival_date_year | arrival_date_week_number | arrival_date_day_of_month | stays_in_weekend_nights | stays_in_week_nights | adults | children | babies | is_repeated_guest | previous_cancellations | pr_Reg | min | 0.000000 | 2015.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 9.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | | 25% | 19.000000 | 2016.000000 | 16.000000 | 8.000000 | 0.000000 | 1.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 9.000000 | 67.000000 | 0.000000 | 69.000000 | 0.000000 | 0.000000 | | 50% | 70.000000 | 2016.000000 | 27.000000 | 16.000000 | 1.000000 | 2.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 14.000000 | 178.000000 | 0.000000 | 95.000000 | 0.000000 | 0.000000 | | 75% | 162.000000 | 2017.000000 | 38.000000 | 24.000000 | 2.000000 | 3.000000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 229.000000 | 254.000000 | 0.000000 | 126.000000 | 0.000000 | 1.000000 | | max | 629.000000 | 2017.000000 | 53.000000 | 31.000000 | 12.000000 | 30.000000 | 55.000000 | 3.000000 | 9.000000 | 1.000000 | 26.000000 | 56.000000 | 14.000000 | 531.000000 | 525.000000 | 391.000000 | 451.500000 | 3.000000 | 5.000000 |
# train/test split
print(len(data_sample)*0.8)
# 9551.2
train_size = 9550
train_data = data_sample.sample(n=train_size, random_state=SEED)
test_data = data_sample.drop(train_data.index)
print(len(train_data), len(test_data))
# 9550 2389
Model Training
# train a binary classification model on booking cancellation
predictor = TabularPredictor(label='reservation_status', path=MODEL_PATH)
predictor.fit(train_data)
# AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
# 3 unique label values: ['Check-Out', 'Canceled', 'No-Show']
# AutoGluon training complete, total runtime = 56.25s ... Best model: "WeightedEnsemble_L2"
predictor.fit_summary()
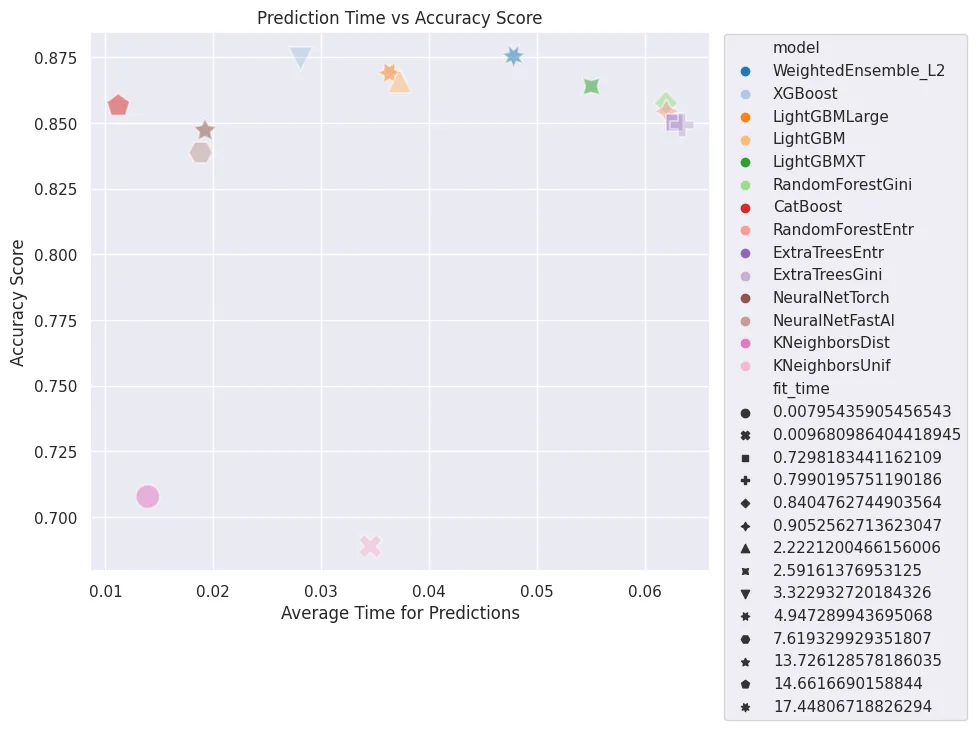
Estimated performance of each model:
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | 0.875393 | 0.047837 | 17.448067 | 0.000508 | 0.399006 | 2 | True | 14 |
| 1 | XGBoost | 0.874346 | 0.028096 | 3.322933 | 0.028096 | 3.322933 | 1 | True | 11 |
| 2 | LightGBMLarge | 0.869110 | 0.036332 | 4.947290 | 0.036332 | 4.947290 | 1 | True | 13 |
| 3 | LightGBM | 0.865969 | 0.037277 | 2.222120 | 0.037277 | 2.222120 | 1 | True | 5 |
| 4 | LightGBMXT | 0.863874 | 0.055051 | 2.591614 | 0.055051 | 2.591614 | 1 | True | 4 |
| 5 | RandomForestGini | 0.857592 | 0.061962 | 0.840476 | 0.061962 | 0.840476 | 1 | True | 6 |
| 6 | CatBoost | 0.856545 | 0.011194 | 14.661669 | 0.011194 | 14.661669 | 1 | True | 8 |
| 7 | RandomForestEntr | 0.854450 | 0.062001 | 0.905256 | 0.062001 | 0.905256 | 1 | True | 7 |
| 8 | ExtraTreesEntr | 0.850262 | 0.062787 | 0.729818 | 0.062787 | 0.729818 | 1 | True | 10 |
| 9 | ExtraTreesGini | 0.849215 | 0.063442 | 0.799020 | 0.063442 | 0.799020 | 1 | True | 9 |
| 10 | NeuralNetTorch | 0.847120 | 0.019233 | 13.726129 | 0.019233 | 13.726129 | 1 | True | 12 |
| 11 | NeuralNetFastAI | 0.838743 | 0.018830 | 7.619330 | 0.018830 | 7.619330 | 1 | True | 3 |
| 12 | KNeighborsDist | 0.707853 | 0.013923 | 0.007954 | 0.013923 | 0.007954 | 1 | True | 2 |
| 13 | KNeighborsUnif | 0.689005 | 0.034556 | 0.009681 | 0.034556 | 0.009681 | 1 | True | 1 |
Number of models trained: 14 Types of models trained:
WeightedEnsembleModelleaderboard=pd.DataFrame(predictor.leaderboard())
plt.figure(figsize=(8, 7))
sns.set(style='darkgrid')
sns.scatterplot(
x='pred_time_val',
y='score_val',
data=leaderboard,
s=300,
alpha=0.5,
hue='model',
palette='tab20',
style='fit_time'
)
plt.title('Prediction Time vs Accuracy Score')
plt.xlabel('Average Time for Predictions')
plt.ylabel('Accuracy Score')
plt.legend(bbox_to_anchor=(1.01,1.01))
plt.savefig('assets/AutoML_with_AutoGluon_01.webp', bbox_inches='tight')
Model Loading
# load best model
predictor = TabularPredictor.load("model/")
Model Testing
X_test = test_data.drop(columns=['reservation_status'] )
y_test = test_data['reservation_status']
y_pred = predictor.predict(X_test)
eval_metrics = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
array = np.array(list(eval_metrics.items()))
df = pd.DataFrame(array, columns = ['metric','value']).sort_values(by='value')
plt.figure(figsize=(12,5))
plt.bar(df['metric'], df['value'])
plt.title('Evaluation Metrics')
plt.savefig('assets/AutoML_with_AutoGluon_02.webp', bbox_inches='tight')

Feature Interpretability
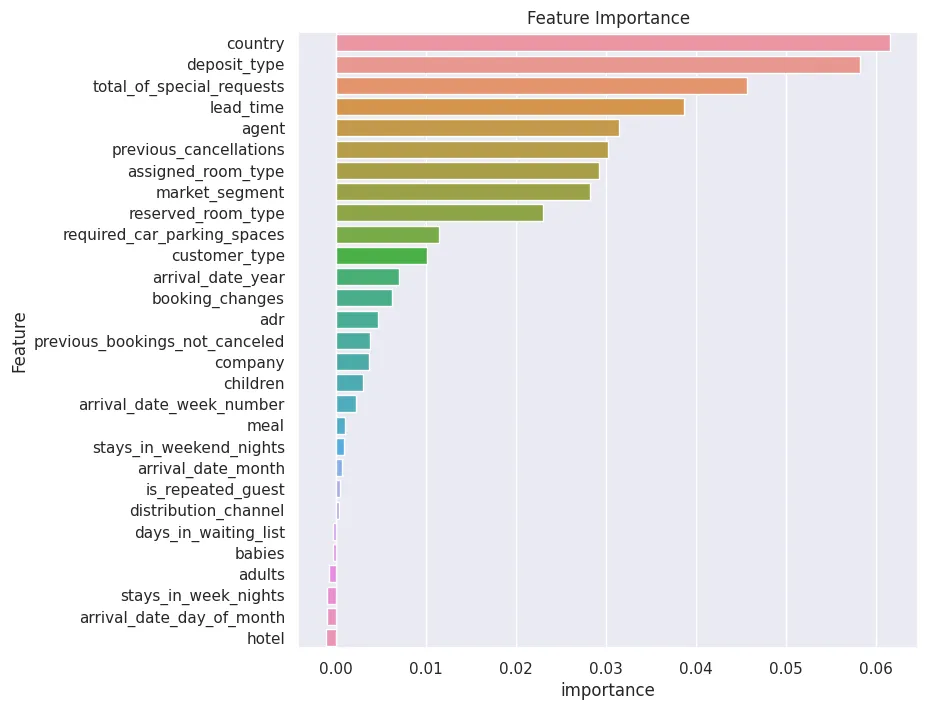
Get feature importance by conducting a Permutation-Shuffling test in AutoGluon. Shuffle one feature column, test how this effects prediction accuracy. The higher the effect the higher the features / columns importance. Negative effects show features that confuse the model, decrease the prediction accuracy and should be removed.
# add test dataset that must include the classifier (is_cancelled):
predictor.feature_importance(test_data)
| importance | stddev | p_value | n | p99_high | p99_low | |
|---|---|---|---|---|---|---|
| country | 0.061532 | 0.003076 | 7.468850e-07 | 5 | 0.067865 | 0.055199 |
| deposit_type | 0.058183 | 0.008815 | 6.133847e-05 | 5 | 0.076334 | 0.040033 |
| total_of_special_requests | 0.045626 | 0.006532 | 4.905663e-05 | 5 | 0.059075 | 0.032177 |
| lead_time | 0.038677 | 0.007045 | 1.264772e-04 | 5 | 0.053184 | 0.024171 |
| agent | 0.031394 | 0.003362 | 1.553978e-05 | 5 | 0.038316 | 0.024472 |
| previous_cancellations | 0.030222 | 0.002891 | 9.926338e-06 | 5 | 0.036174 | 0.024269 |
| assigned_room_type | 0.029217 | 0.003010 | 1.332357e-05 | 5 | 0.035414 | 0.023020 |
| market_segment | 0.028213 | 0.005106 | 1.233146e-04 | 5 | 0.038726 | 0.017699 |
| reserved_room_type | 0.023022 | 0.002529 | 1.719338e-05 | 5 | 0.028229 | 0.017815 |
| required_car_parking_spaces | 0.011469 | 0.001909 | 8.880361e-05 | 5 | 0.015400 | 0.007538 |
| customer_type | 0.010130 | 0.003593 | 1.619134e-03 | 5 | 0.017529 | 0.002731 |
| arrival_date_year | 0.007032 | 0.002703 | 2.173517e-03 | 5 | 0.012598 | 0.001467 |
| booking_changes | 0.006195 | 0.001711 | 6.319167e-04 | 5 | 0.009717 | 0.002673 |
| adr | 0.004604 | 0.002476 | 7.086297e-03 | 5 | 0.009703 | -0.000494 |
| previous_bookings_not_canceled | 0.003767 | 0.001751 | 4.290459e-03 | 5 | 0.007373 | 0.000162 |
| company | 0.003684 | 0.001761 | 4.733895e-03 | 5 | 0.007310 | 0.000058 |
| children | 0.003014 | 0.000546 | 1.235932e-04 | 5 | 0.004138 | 0.001890 |
| arrival_date_week_number | 0.002260 | 0.002706 | 6.760071e-02 | 5 | 0.007833 | -0.003312 |
| meal | 0.001005 | 0.001008 | 4.488794e-02 | 5 | 0.003080 | -0.001071 |
| stays_in_weekend_nights | 0.000921 | 0.001659 | 1.411190e-01 | 5 | 0.004336 | -0.002494 |
| arrival_date_month | 0.000670 | 0.001555 | 1.950213e-01 | 5 | 0.003871 | -0.002532 |
| is_repeated_guest | 0.000419 | 0.001184 | 2.367137e-01 | 5 | 0.002856 | -0.002019 |
| distribution_channel | 0.000335 | 0.001042 | 2.561126e-01 | 5 | 0.002481 | -0.001811 |
| days_in_waiting_list | -0.000335 | 0.000350 | 9.503497e-01 | 5 | 0.000386 | -0.001056 |
| babies | -0.000335 | 0.000459 | 9.110961e-01 | 5 | 0.000609 | -0.001279 |
| adults | -0.000753 | 0.002163 | 7.602366e-01 | 5 | 0.003700 | -0.005207 |
| stays_in_week_nights | -0.001005 | 0.002939 | 7.563611e-01 | 5 | 0.005047 | -0.007056 |
| arrival_date_day_of_month | -0.001005 | 0.002397 | 7.991062e-01 | 5 | 0.003931 | -0.005941 |
| hotel | -0.001088 | 0.002147 | 8.398613e-01 | 5 | 0.003332 | -0.005508 |
importance_df = predictor.feature_importance(test_data).reset_index()
plt.figure(figsize=(8,8))
plt.title('Feature Importance')
sns.set(style='darkgrid')
sns.barplot(
data=importance_df,
y='index',
x='importance',
orient='horizontal'
).set_ylabel('Feature')
plt.savefig('assets/AutoML_with_AutoGluon_03.webp', bbox_inches='tight')
Running Predictions
test_booking = {
"hotel": "City Hotel",
"is_canceled": 0,
"lead_time": 214,
"arrival_date_year": 2017,
"arrival_date_month": "June",
"arrival_date_week_number": 23,
"arrival_date_day_of_month": 9,
"stays_in_weekend_nights": 1,
"stays_in_week_nights": 2,
"adults": 2,
"children": 0,
"babies": 0,
"meal": "BB",
"country": "GBR",
"market_segment": "Groups",
"distribution_channel": "Direct",
"is_repeated_guest": 0,
"previous_cancellations": 0,
"previous_bookings_not_canceled": 0,
"reserved_room_type": "D",
"assigned_room_type": "D",
"booking_changes": 1,
"deposit_type": "No Deposit",
"agent": 28,
"company": 153,
"days_in_waiting_list": 0,
"customer_type": "Transient",
"adr": 118.13,
"required_car_parking_spaces": 0,
"total_of_special_requests": 0,
"reservation_status": "Check-Out",
"reservation_status_date": "12-06-17"
}
# load booking into dataset
test_booking_df = TabularDataset.from_dict([test_booking])
test_booking_from_csv_df = TabularDataset('dataset/test_booking.csv')
predictor.predict(test_booking_df)
# 0 Check-Out <- not cancelled
# Name: is_canceled, dtype: int64
predictor.predict(test_booking_from_csv_df)
# 0 Check-Out <- not cancelled
# Name: is_canceled, dtype: int64
Tabular Data Regression
# get dataset
! wget https://raw.githubusercontent.com/mgrafals/Uber-Data-Engineering-Project/main/uber_data.csv -P dataset
from autogluon.tabular import TabularDataset, TabularPredictor
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
SEED = 42
MODEL_PATH = 'model'
Data Preprocessing
data = TabularDataset('dataset/uber_data.csv')
data.head().transpose()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| VendorID | 1 | 1 | 2 | 2 | 2 |
| tpep_pickup_datetime | 2016-03-01 00:00:00 | 2016-03-01 00:00:00 | 2016-03-01 00:00:00 | 2016-03-01 00:00:00 | 2016-03-01 00:00:00 |
| tpep_dropoff_datetime | 2016-03-01 00:07:55 | 2016-03-01 00:11:06 | 2016-03-01 00:31:06 | 2016-03-01 00:00:00 | 2016-03-01 00:00:00 |
| passenger_count | 1 | 1 | 2 | 3 | 5 |
| trip_distance | 2.5 | 2.9 | 19.98 | 10.78 | 30.43 |
| pickup_longitude | -73.976746 | -73.983482 | -73.782021 | -73.863419 | -73.971741 |
| pickup_latitude | 40.765152 | 40.767925 | 40.64481 | 40.769814 | 40.792183 |
| RatecodeID | 1 | 1 | 1 | 1 | 3 |
| store_and_fwd_flag | N | N | N | N | N |
| dropoff_longitude | -74.004265 | -74.005943 | -73.974541 | -73.96965 | -74.17717 |
| dropoff_latitude | 40.746128 | 40.733166 | 40.67577 | 40.757767 | 40.695053 |
| payment_type | 1 | 1 | 1 | 1 | 1 |
| fare_amount | 9.0 | 11.0 | 54.5 | 31.5 | 98.0 |
| extra | 0.5 | 0.5 | 0.5 | 0.0 | 0.0 |
| mta_tax | 0.5 | 0.5 | 0.5 | 0.5 | 0.0 |
| tip_amount | 2.05 | 3.05 | 8.0 | 3.78 | 0.0 |
| tolls_amount | 0.0 | 0.0 | 0.0 | 5.54 | 15.5 |
| improvement_surcharge | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 |
| total_amount | 12.35 | 15.35 | 63.8 | 41.62 | 113.8 |
# there are two values that directly scale with the label
# of of passenger fare: fare_amount and total_amount -> drop the latter
data = data.drop('total_amount', axis=1)
data.info()
# RangeIndex: 100000 entries, 0 to 99999
# Data columns (total 18 columns):
data_sample = data.sample(frac=0.5 , random_state=SEED)
data_sample.describe()
| VendorID | passenger_count | trip_distance | pickup_longitude | pickup_latitude | RatecodeID | dropoff_longitude | dropoff_latitude | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 |
| mean | 1.883160 | 1.926360 | 3.039138 | -73.252772 | 40.355400 | 1.040780 | -73.274211 | 40.367544 | 1.337420 | 13.287511 | 0.101730 | 0.496980 | 1.881304 | 0.367985 | 0.299484 | 16.434978 |
| std | 0.321233 | 1.586212 | 3.851644 | 7.268226 | 4.002437 | 0.284462 | 7.156534 | 3.940944 | 0.482423 | 12.104265 | 0.202674 | 0.042906 | 2.582070 | 1.521707 | 0.016749 | 14.779261 |
| min | 1.000000 | 0.000000 | 0.000000 | -121.933151 | 0.000000 | 1.000000 | -121.933327 | 0.000000 | 1.000000 | -7.000000 | -0.500000 | -0.500000 | -2.700000 | 0.000000 | -0.300000 | -10.140000 |
| 25% | 2.000000 | 1.000000 | 1.000000 | -73.990921 | 40.738933 | 1.000000 | -73.990410 | 40.738776 | 1.000000 | 6.500000 | 0.000000 | 0.500000 | 0.000000 | 0.000000 | 0.300000 | 8.300000 |
| 50% | 2.000000 | 1.000000 | 1.670000 | -73.980164 | 40.755428 | 1.000000 | -73.978409 | 40.755249 | 1.000000 | 9.500000 | 0.000000 | 0.500000 | 1.360000 | 0.000000 | 0.300000 | 11.800000 |
| 75% | 2.000000 | 2.000000 | 3.200000 | -73.964142 | 40.769090 | 1.000000 | -73.962097 | 40.768002 | 2.000000 | 15.000000 | 0.000000 | 0.500000 | 2.460000 | 0.000000 | 0.300000 | 18.300000 |
| max | 2.000000 | 6.000000 | 160.800000 | 0.000000 | 41.204548 | 6.000000 | 0.000000 | 42.666893 | 4.000000 | 819.500000 | 4.500000 | 0.500000 | 47.560000 | 22.040000 | 0.300000 | 832.800000 |
# 80:20 train test split
train_data = data_sample.sample(n=40000, random_state=SEED)
test_data = data_sample.drop(train_data.index)
Model Training
predictor = TabularPredictor(label='fare_amount', path=MODEL_PATH)
predictor.fit(train_data)
# AutoGluon infers your prediction problem is: 'regression' (because dtype of label-column == float and label-values can't be converted to int).
# Label info (max, min, mean, stddev): (819.5, -7.0, 13.23572, 11.96267)
# AutoGluon training complete, total runtime = 89.72s ... Best model: "WeightedEnsemble_L2"
leaderboard=pd.DataFrame(predictor.leaderboard())
plt.figure(figsize=(8, 7))
sns.set(style='darkgrid')
sns.scatterplot(
x='pred_time_val',
y='score_val',
data=leaderboard,
s=300,
alpha=0.5,
hue='model',
palette='tab20',
style='fit_time'
)
plt.title('Prediction Time vs Accuracy Score')
plt.xlabel('Average Time for Predictions')
plt.ylabel('Validation Score (-RMSE)')
plt.legend(bbox_to_anchor=(1.01,1.01))
plt.savefig('assets/AutoML_with_AutoGluon_01.webp', bbox_inches='tight')
Model Loading
# load best model
predictor = TabularPredictor.load("model/")
Model Testing Model Testing
X_test = test_data.drop(columns=['fare_amount'] )
y_test = test_data['fare_amount']
y_pred = predictor.predict(X_test)
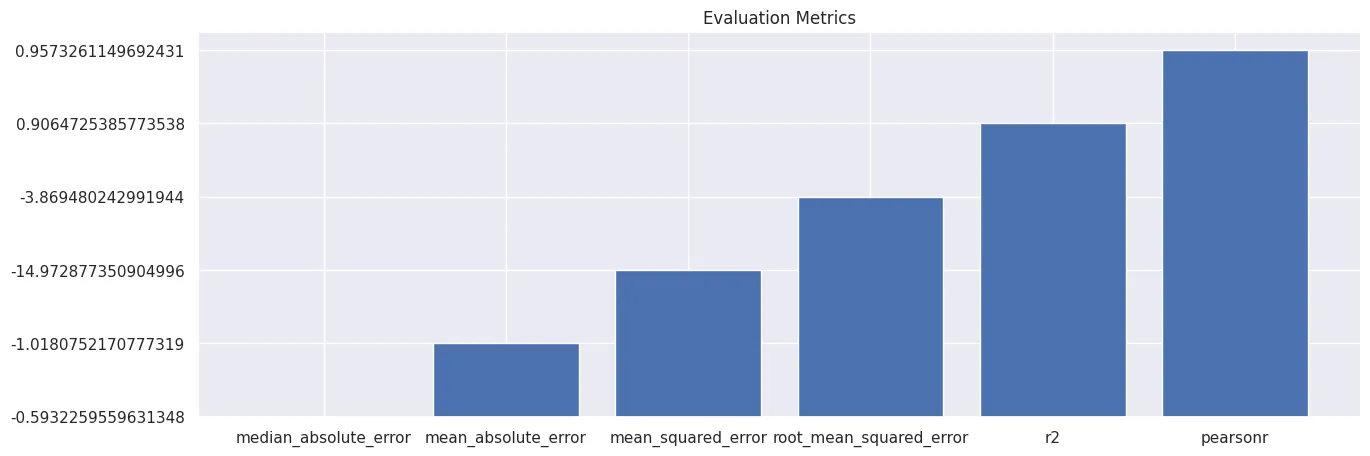
eval_metrics = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
array = np.array(list(eval_metrics.items()))
df = pd.DataFrame(array, columns = ['metric','value']).sort_values(by='value')
plt.figure(figsize=(15,5))
plt.bar(df['metric'], df['value'])
plt.title('Evaluation Metrics')
plt.savefig('assets/AutoML_with_AutoGluon_02.webp', bbox_inches='tight')
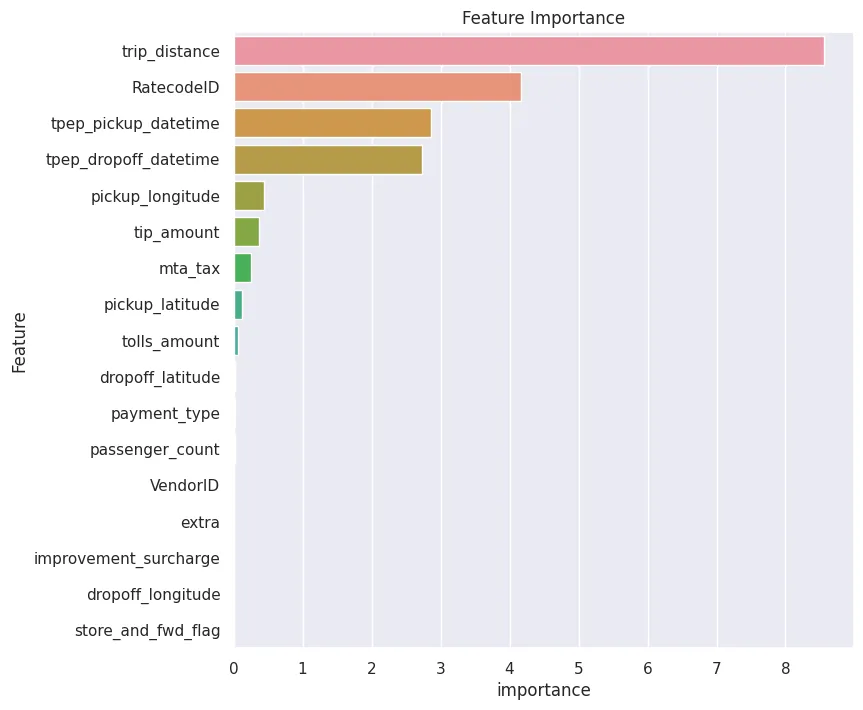
Feature Interpretability
# add test dataset that must include the classifier (fare_amount):
importance_df = predictor.feature_importance(test_data).reset_index()
plt.figure(figsize=(8,8))
plt.title('Feature Importance')
sns.set(style='darkgrid')
sns.barplot(
data=importance_df,
y='index',
x='importance',
orient='horizontal'
).set_ylabel('Feature')
plt.savefig('assets/AutoML_with_AutoGluon_03.webp', bbox_inches='tight')
Running Predictions
test_drive = {
"VendorID": 2,
"tpep_pickup_datetime": "2016-03-01 01:12:39",
"tpep_dropoff_datetime": "2016-03-01 01:16:48",
"passenger_count": 5,
"trip_distance": 1.28,
"pickup_longitude": -73.97952270507811,
"pickup_latitude": 40.76089096069336,
"RatecodeID": 1,
"store_and_fwd_flag": "N",
"dropoff_longitude": -73.99040985107422,
"dropoff_latitude": 40.77185821533203,
"payment_type": 1,
"fare_amount": 5.5,
"extra": 0.5,
"mta_tax": 0.5,
"tip_amount": 0.0,
"tolls_amount": 0.0,
"improvement_surcharge": 0.3,
"total_amount": 6.8
}
# load booking into dataset
test_drive_df = TabularDataset.from_dict([test_drive])
test_drive_from_csv_df = TabularDataset('dataset/test_data.csv')
predictor.predict(test_drive_df)
# 0 6.403378
# Name: fare_amount, dtype: float32
predictor.predict(test_drive_from_csv_df)
# 0 20.392935
# Name: fare_amount, dtype: float32
Customizations
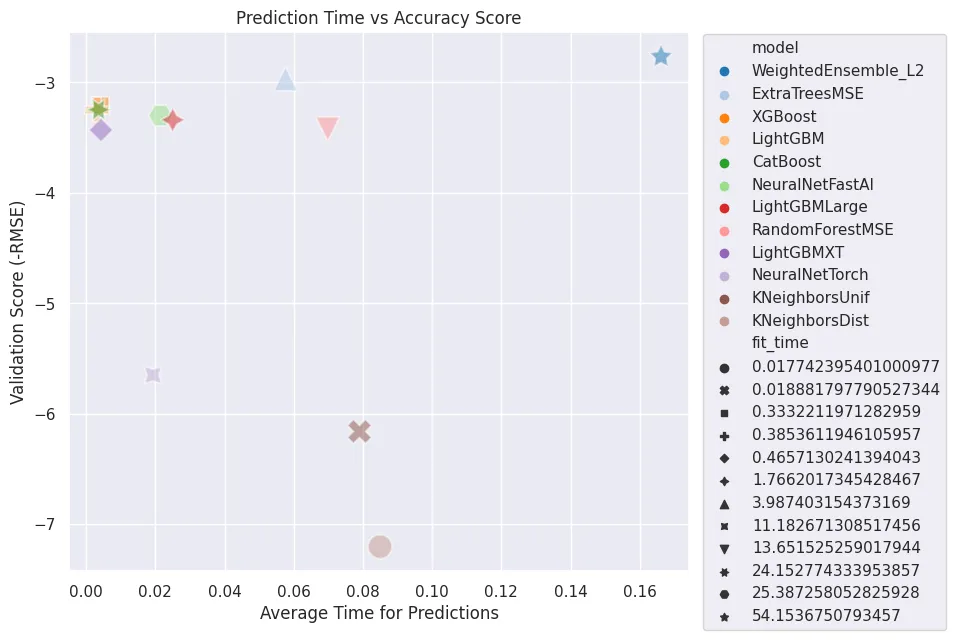
leaderboard_results = predictor.leaderboard(test_data)
results_df = leaderboard_results[['model', 'score_test', 'score_val', 'pred_time_test', 'fit_time']]
results_df
| model | score_test | score_val | pred_time_test | fit_time | |
|---|---|---|---|---|---|
| 0 | ExtraTreesMSE | -3.424482 | -2.967295 | 0.336113 | 4.152885 |
| 1 | RandomForestMSE | -3.496445 | -3.421289 | 0.635791 | 14.147954 |
| 2 | LightGBMLarge | -3.711858 | -3.338691 | 0.114917 | 1.717049 |
| 3 | WeightedEnsemble_L2 | -3.869480 | -2.766400 | 0.870554 | 56.528128 |
| 4 | CatBoost | -3.875734 | -3.246665 | 0.012133 | 26.307805 |
| 5 | XGBoost | -4.003582 | -3.211102 | 0.026592 | 0.405672 |
| 6 | LightGBM | -4.547570 | -3.245028 | 0.013185 | 0.341916 |
| 7 | NeuralNetFastAI | -4.767402 | -3.300341 | 0.160983 | 25.395540 |
| 8 | LightGBMXT | -5.297554 | -3.430323 | 0.016557 | 0.359552 |
| 9 | NeuralNetTorch | -7.383115 | -5.649417 | 0.050529 | 10.426494 |
| 10 | KNeighborsUnif | -7.793495 | -6.159739 | 0.330812 | 0.019789 |
| 11 | KNeighborsDist | -8.238958 | -7.202982 | 0.276046 | 0.018064 |
Inference Constraints
The WeightedEnsemble_L2 model - which is an ensemble of different models used by AutoGluon - has the highest test accuracy but also takes by far the longest to return predictions. The 'non-ensembled' model ExtraTreesMSE is not that far off when it comes to accuracy but more than twice as fast with predictions. We can set a restraint how much time is acceptable to remove 'slow' models from the created weighted ensemble model.
fast_predictor = TabularPredictor(label='fare_amount', path='model_fast')
fast_predictor.fit(train_data, time_limit=30, infer_limit=0.000004, infer_limit_batch_size=10000)
# Removing 5/6 base models to satisfy inference constraint (constraint=1.651μs) ...
# 0.092ms -> 0.058ms (KNeighborsUnif)
# 0.058ms -> 0.022ms (KNeighborsDist)
# 0.022ms -> 3.321μs (RandomForestMSE)
# 3.321μs -> 1.871μs (LightGBMXT)
# 1.871μs -> 1.177μs (CatBoost)
eval_metrics_fast = fast_predictor.fit_summary()
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | LightGBM | -3.245028 | 0.003834 | 0.588395 | 0.003834 | 0.588395 | 1 | True | 4 |
| 1 | WeightedEnsemble_L2 | -3.245028 | 0.004205 | 0.594806 | 0.000371 | 0.006411 | 2 | True | 7 |
| 2 | CatBoost | -3.266919 | 0.003005 | 8.212242 | 0.003005 | 8.212242 | 1 | True | 6 |
| 3 | RandomForestMSE | -3.421289 | 0.073429 | 15.412317 | 0.073429 | 15.412317 | 1 | True | 5 |
| 4 | LightGBMXT | -3.430323 | 0.004597 | 0.667201 | 0.004597 | 0.667201 | 1 | True | 3 |
| 5 | KNeighborsUnif | -6.159739 | 0.134967 | 0.365208 | 0.134967 | 0.365208 | 1 | True | 1 |
| 6 | KNeighborsDist | -7.202982 | 0.120473 | 0.394391 | 0.120473 | 0.394391 | 1 | True | 2 |
Number of models trained: 7 Types of models trained:
CatBoostModeleval_metrics = predictor.fit_summary()
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -2.766400 | 0.244695 | 56.528128 | 0.000308 | 0.246437 | 2 | True | 12 |
| 1 | ExtraTreesMSE | -2.967295 | 0.060220 | 4.152885 | 0.060220 | 4.152885 | 1 | True | 7 |
| 2 | XGBoost | -3.211102 | 0.005235 | 0.405672 | 0.005235 | 0.405672 | 1 | True | 9 |
| 3 | LightGBM | -3.245028 | 0.003292 | 0.341916 | 0.003292 | 0.341916 | 1 | True | 4 |
| 4 | CatBoost | -3.246665 | 0.004185 | 26.307805 | 0.004185 | 26.307805 | 1 | True | 6 |
| 5 | NeuralNetFastAI | -3.300341 | 0.031887 | 25.395540 | 0.031887 | 25.395540 | 1 | True | 8 |
| 6 | LightGBMLarge | -3.338691 | 0.024750 | 1.717049 | 0.024750 | 1.717049 | 1 | True | 11 |
| 7 | RandomForestMSE | -3.421289 | 0.059909 | 14.147954 | 0.059909 | 14.147954 | 1 | True | 5 |
| 8 | LightGBMXT | -3.430323 | 0.003857 | 0.359552 | 0.003857 | 0.359552 | 1 | True | 3 |
| 9 | NeuralNetTorch | -5.649417 | 0.020283 | 10.426494 | 0.020283 | 10.426494 | 1 | True | 10 |
| 10 | KNeighborsUnif | -6.159739 | 0.142860 | 0.019789 | 0.142860 | 0.019789 | 1 | True | 1 |
| 11 | KNeighborsDist | -7.202982 | 0.113172 | 0.018064 | 0.113172 | 0.018064 | 1 | True | 2 |
Number of models trained: 12 Types of models trained:
TabularNeuralNetTorchModelResult: Much faster but less accurate
- WeightedEnsemble_L2:
- score_val:
-2.766400->-3.245028 - pred_time_val:
0.244695s->0.004205s - fit_time:
56.528128s->0.594806s
- score_val:
Hyperparameter Tuning
hyperparameters_NN_Torch = {"num_epochs": 1, "learning_rate": 0.5}
hyperparameters_XGB = {} # use XGBoost with default values
hyperparameters = {"NN_TORCH": hyperparameters_NN_Torch, "XGB": hyperparameters_XGB}
tuned_predictor = TabularPredictor(label='fare_amount', path='model_tuned')
tuned_predictor.fit(
train_data=train_data,
hyperparameters=hyperparameters
)
tuned_predictor.fit_summary()
# AutoGluon only trained the two configured model for one epoch
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | XGBoost | -3.211102 | 0.003993 | 0.363999 | 0.003993 | 0.363999 | 1 | True | 1 |
| 1 | WeightedEnsemble_L2 | -3.211102 | 0.004304 | 0.434471 | 0.000311 | 0.070472 | 2 | True | 3 |
| 2 | NeuralNetTorch | -23.769987 | 0.019870 | 0.935391 | 0.019870 | 0.935391 | 1 | True | 2 |
AutoGluon Presets
Available Presets: [
best_quality,high_quality,good_quality,medium_quality,optimize_for_deployment,interpretable,ignore_text]
presets = ['medium_quality'] # accept lower accuracy for speed
preset_predictor = TabularPredictor(label='fare_amount', path='preset_model')
preset_predictor.fit(
train_data=train_data,
presets=presets,
included_model_types=['GBM', 'FASTAI', 'NN_TORCH'], # only use those models
# excluded_model_types=['KNN', 'NN', 'XT', 'RF', 'FASTAI'] # use all but those models
)
preset_predictor.fit_summary()
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble_L2 | -3.054243 | 0.083915 | 42.906133 | 0.000301 | 0.133571 | 2 | True | 6 |
| 1 | LightGBM | -3.245028 | 0.003262 | 0.507183 | 0.003262 | 0.507183 | 1 | True | 2 |
| 2 | NeuralNetFastAI | -3.300341 | 0.027946 | 26.112154 | 0.027946 | 26.112154 | 1 | True | 3 |
| 3 | LightGBMLarge | -3.338691 | 0.026010 | 1.953629 | 0.026010 | 1.953629 | 1 | True | 5 |
| 4 | LightGBMXT | -3.430323 | 0.004276 | 0.458992 | 0.004276 | 0.458992 | 1 | True | 1 |
| 5 | NeuralNetTorch | -5.649417 | 0.022120 | 13.740605 | 0.022120 | 13.740605 | 1 | True | 4 |
Model Deployment
predictor = TabularPredictor.load("model/")
# retain model on train + validation dataset
predictor.refit_full()
# strip all models not part of the `WeightedEnsemble_L2_FULL`
predictor.clone_for_deployment('production_model')
# Clone: Keeping minimum set of models required to predict with best model 'WeightedEnsemble_L2_FULL'...
# To load the cloned predictor: predictor_clone = TabularPredictor.load(path="production_model")
predictor_clone = TabularPredictor.load(path="production_model")
test_data = TabularDataset('dataset/test_data.csv')
predictor_clone.predict(test_data)
# 0 20.425285
# Name: fare_amount, dtype: float32