Deploying Prediction APIs
Using Flask to deploy your ML Model as a Web Application.
Building an ML Model for Deployment
import joblib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer, MinMaxScaler
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential, load_model
SEED = 42
EPOCHS = 888
MODEL_PATH="./model/full_iris_model.h5"
SCALER_PATH="./model/iris_data_norm.pkl"
IRIS Dataset
wget https://gist.githubusercontent.com/Thanatoz-1/9e7fdfb8189f0cdf5d73a494e4a6392a/raw/aaecbd14aeaa468cd749528f291aa8a30c2ea09e/iris_dataset.csv
iris_dataset = pd.read_csv("./data/iris_dataset.csv")
iris_dataset.head()
# separate features from labels
X = iris_dataset.drop('target', axis=1)
X.head()
y = iris_dataset['target']
y.unique()
# 1-hot encoding labels
encoder = LabelBinarizer()
y = encoder.fit_transform(y)
y[0]
# create training / testing datasets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=SEED)
# normalize training data
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_norm = scaler.transform(X_train)
X_test_norm = scaler.transform(X_test)
Building the Model
iris_model = Sequential([
Dense(units=4, activation='relu', input_shape=[4,]),
Dense(units=3, activation='softmax')
])
iris_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# fitting the model
early_stop = EarlyStopping(
monitor='val_loss',
min_delta=0.0001,
patience=10,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=True,
start_from_epoch=0)
Fitting the Model
history_iris_model = iris_model.fit(x=X_train_norm,
y=y_train,
epochs=EPOCHS,
validation_data=(X_test_norm, y_test),
callbacks=[early_stop])
# evaluate the model
iris_model.evaluate(X_test_norm, y_test, verbose=0)
# [0.334958016872406, 0.8999999761581421]
# plot the validation accuracy
def plot_accuracy_curves(history, title):
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
epochs = range(len(history.history['accuracy']))
# Plot accuracy
plt.figure(figsize=(12, 6))
plt.plot(epochs, accuracy, label='training_accuracy')
plt.plot(epochs, val_accuracy, label='val_accuracy')
plt.title(title)
plt.xlabel('Epochs')
plt.legend();
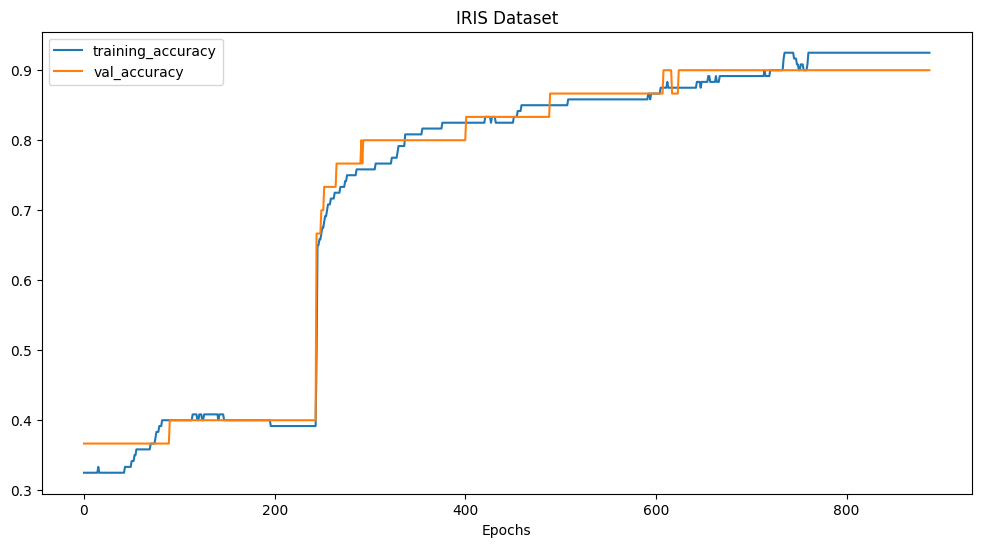
plot_accuracy_curves(history_iris_model, "IRIS Dataset :: Accuracy Curve")
# plot the training loss
def plot_loss_curves(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(history.history['loss']))
# Plot accuracy
plt.figure(figsize=(12, 6))
plt.plot(epochs, loss, label='training_loss')
plt.plot(epochs, val_loss, label='val_loss')
plt.title(title)
plt.xlabel('Epochs')
plt.legend();
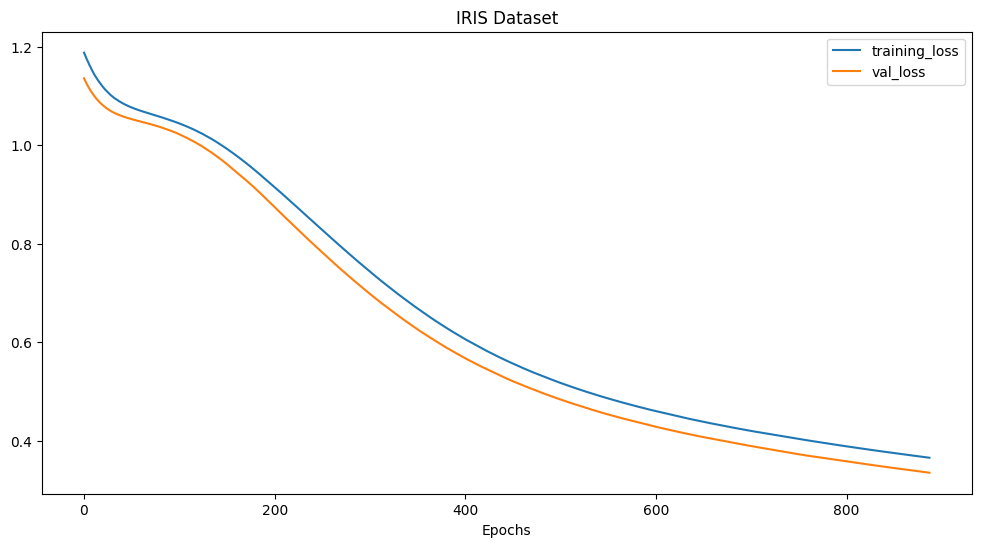
plot_loss_curves(history_iris_model, "IRIS Dataset :: Loss Curve")
Fit all Data
After reaching a approx. 90% accuracy we can now add the testing data to our model training to increase the dataset variety the model was trained on.
X_norm =scaler.fit_transform(X)
iris_model_full = Sequential([
Dense(units=4, activation='relu', input_shape=[4,]),
Dense(units=3, activation='softmax')
])
iris_model_full.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
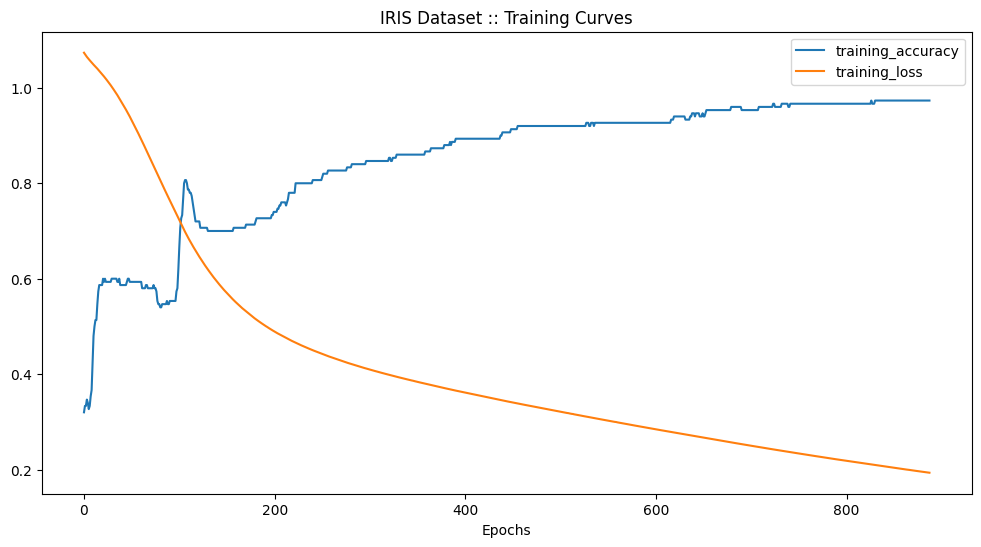
history_iris_model_full = iris_model_full.fit(X_norm, y, epochs=EPOCHS)
# evaluate the model
iris_model_full.evaluate(X_norm, y, verbose=0)
# [0.1931973546743393, 0.9733333587646484]
# plot the validation and training loss
def plot_training_curves(history, title):
accuracy = history.history['accuracy']
loss = history.history['loss']
epochs = range(len(history.history['loss']))
# Plot accuracy
plt.figure(figsize=(12, 6))
plt.plot(epochs, accuracy, label='training_accuracy')
plt.plot(epochs, loss, label='training_loss')
plt.title(title)
plt.xlabel('Epochs')
plt.legend();
# plot accuracy and loss curves
plt.figure(figsize=(12, 6))
plot_training_curves(history_iris_model_full, "IRIS Dataset :: Training Curves")
Save the Trained Model
# save the full model with training weights
iris_model_full.save(MODEL_PATH)
# save data preprocessing
joblib.dump(scaler, SCALER_PATH)
Run Predictions
# load the saved model
loaded_iris_model = load_model(MODEL_PATH)
loaded_scaler = joblib.load(SCALER_PATH)
# verify predictions are the same
loaded_iris_model.evaluate(X_norm, y, verbose=0)
Prediction API
# simulate JSON API call
flower_example = {"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)":1.4,
"petal width (cm)": 0.2}
# API function (return class index with highest probability)
def return_prediction(model, scaler, json_request):
s_len = json_request["sepal length (cm)"]
s_wi = json_request["sepal width (cm)"]
p_len = json_request["petal length (cm)"]
p_w = json_request["petal width (cm)"]
measures =[[s_len, s_wi, p_len, p_w]]
measures_norm = scaler.transform(measures)
flower_class_probabilities = model.predict(measures_norm)
flower_class_index=np.argmax(flower_class_probabilities,axis=1)
return flower_class_index
return_prediction(loaded_iris_model, loaded_scaler, flower_example)
# probabilities array([[9.987895e-01, 7.723020e-04, 4.383073e-04]], dtype=float32)
# index array([0])
# API function (return class name)
def return_prediction(model, scaler, json_request):
s_len = json_request["sepal length (cm)"]
s_wi = json_request["sepal width (cm)"]
p_len = json_request["petal length (cm)"]
p_w = json_request["petal width (cm)"]
classes = np.array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
measures =[[s_len, s_wi, p_len, p_w]]
measures_norm = scaler.transform(measures)
flower_class_probabilities = model.predict(measures_norm)
flower_class_index=np.argmax(flower_class_probabilities,axis=1)
return classes[flower_class_index]
return_prediction(loaded_iris_model, loaded_scaler, flower_example)
# array(['Iris-setosa'], dtype='<U15')
We can combine this into a small Python script that we can deploy together with the exported trained model and scaler:
Run_Predictions.py
import joblib
import numpy as np
from tensorflow.keras.models import load_model
MODEL_PATH="./model/full_iris_model.h5"
SCALER_PATH="./model/iris_data_norm.pkl"
# load the saved model
loaded_iris_model = load_model(MODEL_PATH)
loaded_scaler = joblib.load(SCALER_PATH)
# API function (return class name)
def return_prediction(model, scaler, json_request):
s_len = json_request["sepal length (cm)"]
s_wi = json_request["sepal width (cm)"]
p_len = json_request["petal length (cm)"]
p_w = json_request["petal width (cm)"]
classes = np.array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
measures =[[s_len, s_wi, p_len, p_w]]
measures_norm = scaler.transform(measures)
flower_class_probabilities = model.predict(measures_norm)
flower_class_index=np.argmax(flower_class_probabilities,axis=1)
return classes[flower_class_index]
Model Serving
To serve the model we can use Flask as our application web server. For this we need to split up the prediction code slightly:
Flask_Server.py
import joblib
from flask import Flask, request, jsonify
from tensorflow.keras.models import load_model
from Run_Predictions import return_prediction
from Config import MODEL_PATH, SCALER_PATH
# load the saved model
loaded_iris_model = load_model(MODEL_PATH)
loaded_scaler = joblib.load(SCALER_PATH)
app = Flask(__name__)
# optional home route
@app.route('/')
def index():
return '<h1>IRIS Classifier</h1>'
# expect JSON POST to forward to prediction model
@app.route('/api/iris', methods=['POST'])
def iris_class_prediction():
content = request.json
results = return_prediction(loaded_iris_model, loaded_scaler, content)
return jsonify(results[0])
if __name__ == '__main__':
app.run()
This file imports the API calling function from:
Run_Predictions.py
import numpy as np
# API function (return class name)
def return_prediction(model, scaler, json_request):
s_len = json_request["sepal length (cm)"]
s_wi = json_request["sepal width (cm)"]
p_len = json_request["petal length (cm)"]
p_w = json_request["petal width (cm)"]
classes = np.array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
measures =[[s_len, s_wi, p_len, p_w]]
measures_norm = scaler.transform(measures)
flower_class_probabilities = model.predict(measures_norm)
flower_class_index=np.argmax(flower_class_probabilities,axis=1)
return classes[flower_class_index]
Use a tool like Postman to test the API:
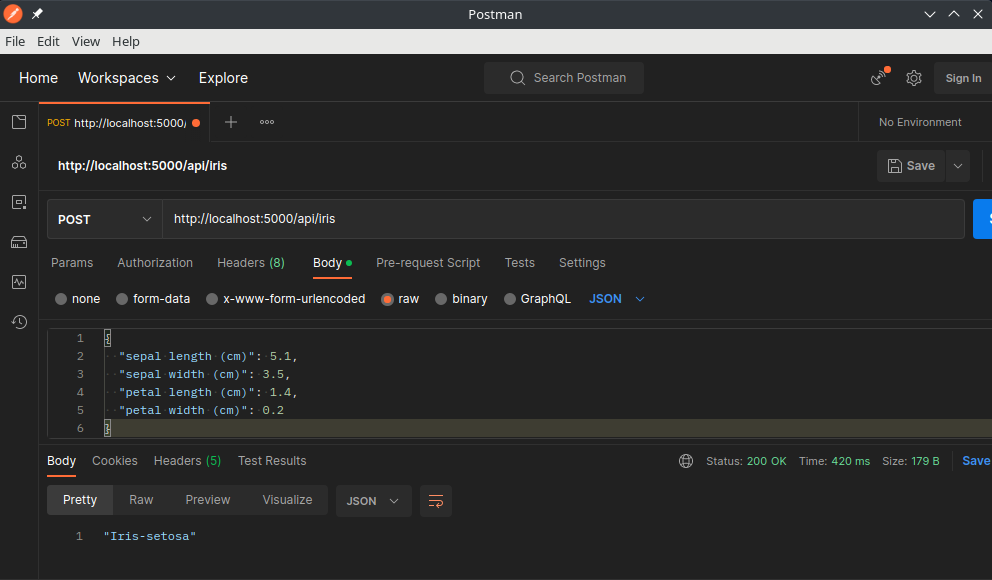
Or run a Python script to simulate a request:
sample_request.py
import requests
sample_request = {
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
}
result = requests.post('http://127.0.0.1:5000/api/iris', json=sample_request)
print(result.status_code, result.text)
Executing this script should return the same result:
python sample_request.py
200 "Iris-setosa"
Prediction Frontend
Start the Flask server from the Github repository:
python Flask_Server.py