Apache Airflow Data Pipelines

Setup
I am going to use the image I build earlier. But to be able to write and use my own data pipelines I need to mount a volume into the container so that the Python files on my host system become available to Airflow inside the running container. I can also create a default Airflow configuration file and mount it into place to be used by my container. So start by preparing those directories on my host:
sudo mkdir -p /opt/airflow/dags
sudo chown -R myuser /opt/airflow
To get the latest configuration file I will first start the container without the configuration mount and have the file generated inside the container. Then I can copy it to my host system and modify it if needed:
docker cp airflow:/opt/airflow/airflow.cfg /opt/airflow/airflow.cfg
Now I can start the container with all mounts in place:
docker run --rm -d -p 8080:8080 \
--mount type=bind,source=/opt/airflow/airflow.cfg,target=/opt/airflow/airflow.cfg \
--mount type=bind,source=/opt/airflow/dags,target=/opt/airflow/dags \
--name airflow airflow-postgres
Now every file I drop into /opt/airflow/dags will be available inside the container.
Model Training Pipeline (DAG)
This is an example of a trainings pipeline. We have a group of models that might perform well in the given task. We choose the model that gives us the highest accuracy and then perform a follow-up task based on whether or not the accuracy is acceptable:
Model A Accuracy above Threshold
Model B -> Best Model ->
Model C Accuracy below Threshold
Start by creating a example_dag.py inside the dags directory - Note that it will take some time (defined by min_file_process_interval and dag_dir_list_interval) before your DAG shows up in the Airflow UI, By default the dags directory is scanned every 5min and the webUI refreshes every 30s - so worst case scenario five and a half minutes:
from airflow import DAG
from airflow.operators.python import PythonOperator, BranchPythonOperator
from airflow.operators.bash import BashOperator
from datetime import datetime
from random import randint
# define functions to be run by airflow
## simulate training accuracy metric
def _taining_model():
return randint(1,10)
## evaluate accuracies and trigger follow-ups
def _best_model(ti):
### get results from training runs
accuracies = ti.xcom_pull(task_ids=[
'training_model_A',
'training_model_B',
'training_model_C'
])
### find best accuracy
best_accuracy = max(accuracies)
### trigger next step based on value
if (best_accuracy > 7):
return 'acc_passed'
return 'acc_failed'
with DAG("example_dag", start_date=datetime(2023,2,5), schedule="@daily", catchup=False, description="Training ML models A-C", tags=["modelA", "modelB", "modelC", "training"]) as dag:
training_model_A = PythonOperator(
task_id="training_model_A",
python_callable=_taining_model
)
training_model_B = PythonOperator(
task_id="training_model_B",
python_callable=_taining_model
)
training_model_C = PythonOperator(
task_id="training_model_C",
python_callable=_taining_model
)
choose_best_model = BranchPythonOperator(
task_id="choose_best_model",
python_callable=_best_model
)
acc_passed = BashOperator(
task_id="acc_passed",
bash_command="echo 'INFO :: Accuracy assessment PASSED minimum requirements'"
)
acc_failed = BashOperator(
task_id="acc_failed",
bash_command="echo 'WARNING :: Accuracy assessment FAILED minimum requirements'"
)
## define task flow
[training_model_A, training_model_B, training_model_C] >> choose_best_model >> [acc_passed, acc_failed]
Airflow UI
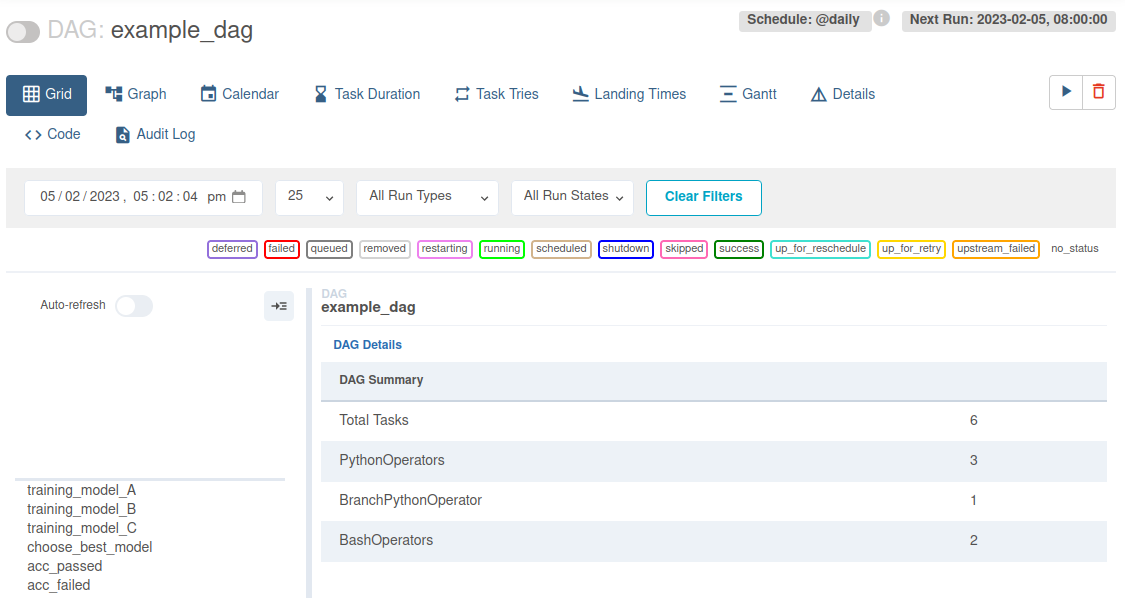
After a few minutes the flow finally shows up in my DAG list:

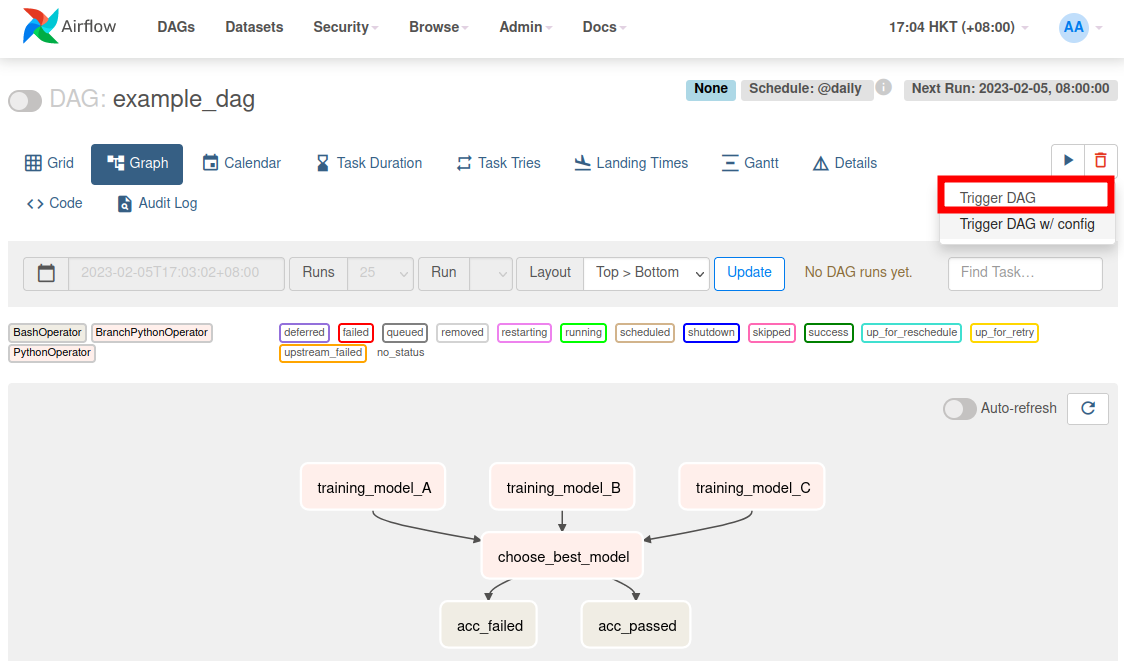
And I can test-run it using the UI:
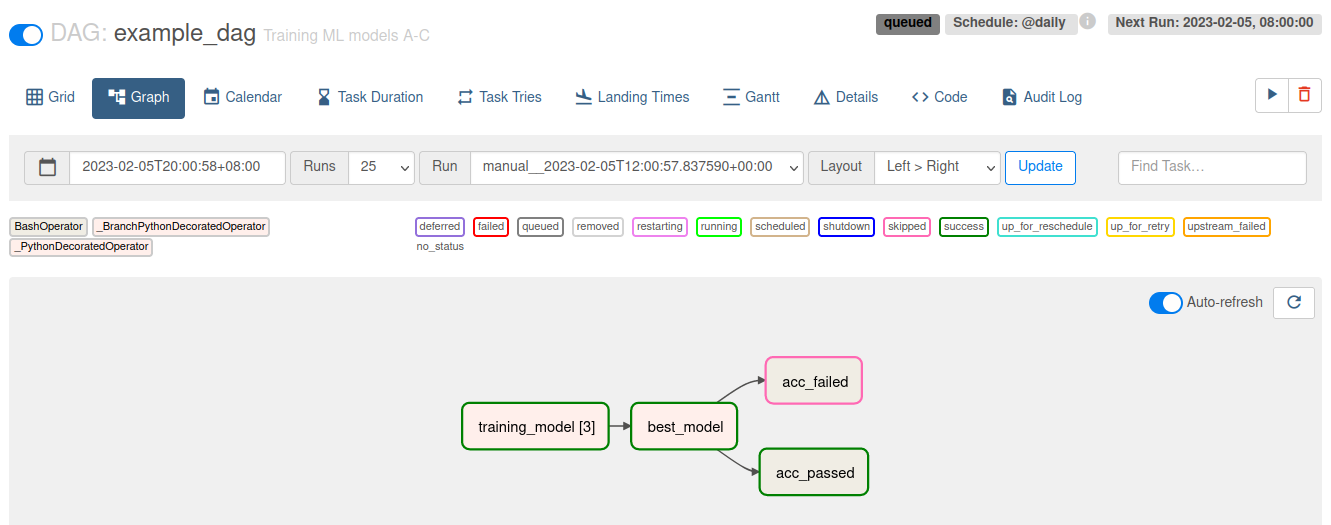
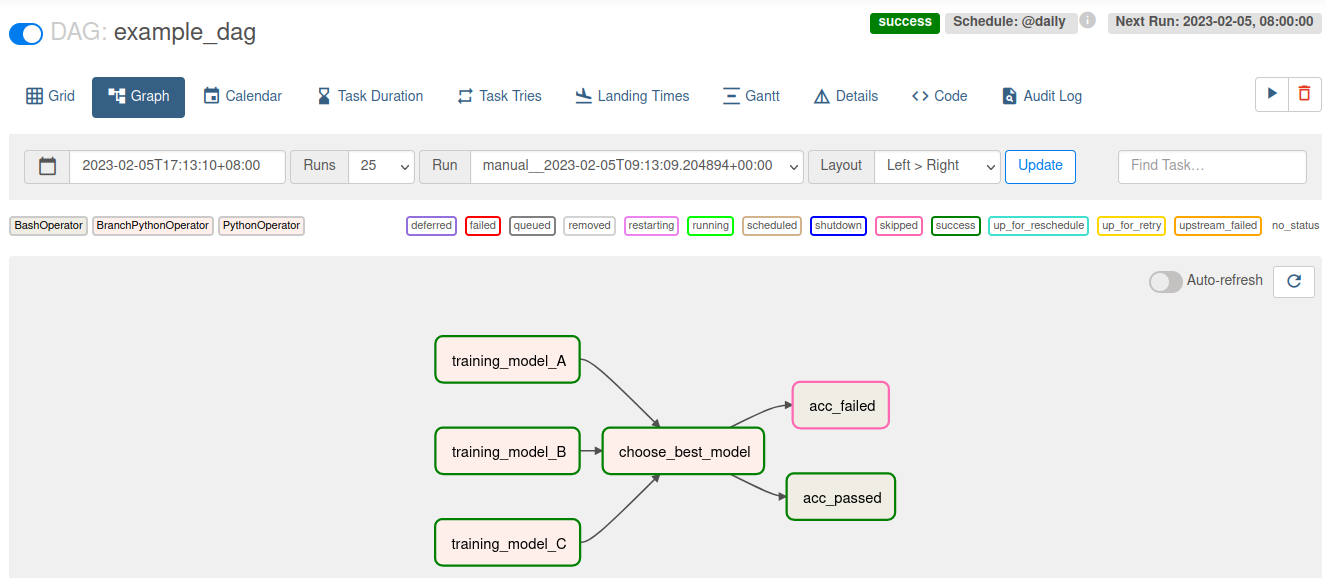
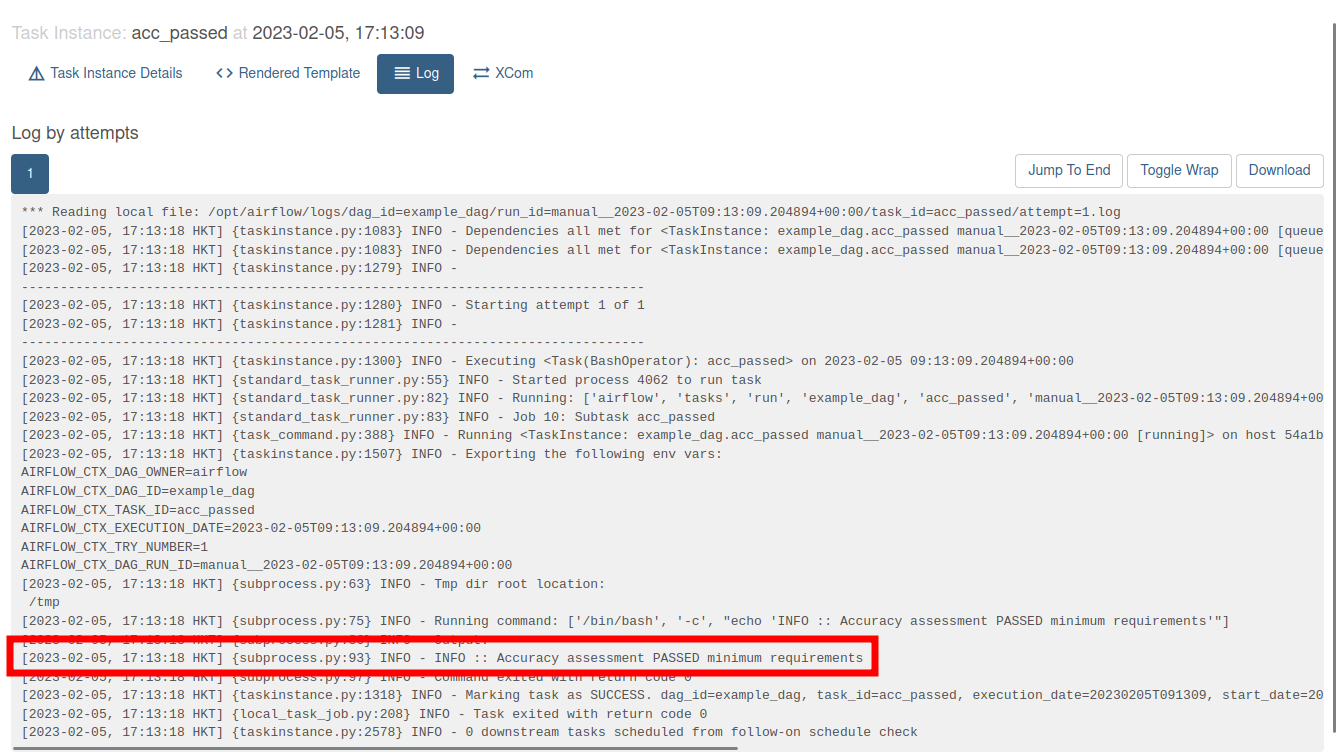
The colour-coding allows you to follow the execution of your flow in realtime in the case in the case below the models were evaluated and the best one passed the accuracy threshold:
Taskflow API
If you write most of your DAGs using plain Python code rather than Operators, then the TaskFlow API will make it much easier to author clean DAGs without extra boilerplate, all using the @task decorator.
TaskFlow takes care of moving inputs and outputs between your Tasks using XComs for you, as well as automatically calculating dependencies - when you call a TaskFlow function in your DAG file, rather than executing it, you will get an object representing the XCom for the result (an XComArg), that you can then use as inputs to downstream tasks or operators:
from airflow import DAG
from airflow.decorators import task
from airflow.operators.python import PythonOperator, BranchPythonOperator
from airflow.operators.bash import BashOperator
from datetime import datetime
from random import randint
with DAG("example_dag", start_date=datetime(2023,2,5), schedule="@daily", catchup=False, description="Training ML models A-C", tags=["modelA", "modelB", "modelC", "training"]):
@task
## simulate training accuracy metric
def training_model():
return randint(1,10)
@task.branch
## evaluate accuracies and trigger follow-ups
def best_model(accuracies):
### find best accuracy
best_accuracy = max(accuracies)
### trigger next step based on value
if (best_accuracy > 7):
return 'acc_passed'
return 'acc_failed'
acc_passed = BashOperator(
task_id="acc_passed",
bash_command="echo 'INFO :: Accuracy assessment PASSED minimum requirements'"
)
acc_failed = BashOperator(
task_id="acc_failed",
bash_command="echo 'WARNING :: Accuracy assessment FAILED minimum requirements'"
)
best_model(training_model())
Dynamic Task Mappings
Now we simplified our pipeline code. But we are now missing our three models A, B and C. They can be added back in using Dynamic Task Mapping. Dynamic Task Mapping allows a way for a workflow to create a number of tasks at runtime based upon current data, rather than the DAG author having to know in advance how many tasks would be needed.
Instead of defining model training function as before (simulated by randint(1,10)) we can no pass the accuracy results from an unspecified amount of models in and start the evaluation from there:
with DAG("example_dag", start_date=datetime(2023,2,5), schedule="@daily", catchup=False, description="Training ML models A-C", tags=["training"]):
@task
## simulate training accuracy metric
def training_model(accuracy):
return accuracy
@task.branch
## evaluate accuracies and trigger follow-ups
def best_model(accuracies):
### find best accuracy
best_accuracy = max(accuracies)
### trigger next step based on value
if (best_accuracy > 7):
return 'acc_passed'
return 'acc_failed'
acc_passed = BashOperator(
task_id="acc_passed",
bash_command="echo 'INFO :: Accuracy assessment PASSED minimum requirements'"
)
acc_failed = BashOperator(
task_id="acc_failed",
bash_command="echo 'WARNING :: Accuracy assessment FAILED minimum requirements'"
)
best_model(training_model.expand(accuracy=[3, 7, 9])) >> [acc_passed, acc_failed]
We now no longer specify the amount of models we evaluate and made our pipeline much more flexible.