Apache Airflow DAG Scheduling

Basic Scheduling
As we have seen before every pipeline we build is defined with a start_date and a scheduled interval in which the pipeline should be run. The catchup parameter tells the DAG if it should try to run all the non-triggered DAG-runs since the start. Another, optional parameter is end_date:
with DAG("example_dag", start_date=datetime(2023,2,5), schedule="@daily", catchup=False):
Use Dataset Updates as Worflow Trigger
You can use Dataset Scheduler e.g. when you are working with multiple Airflow DAGs that depend on the results from the previous pipeline. So that pipeline 2 is automatically triggered once pipeline 1 finished updating a dataset.
So we first write a DAG that pre-processes our dataset - simulated by adding some text to a simple text file:
from airflow import DAG, Dataset
from airflow.decorators import task
from datetime import datetime
dataset = Dataset('/tmp/preprocessed_data.txt')
start_date = datetime(2023,2,5)
description = "Data pre-processing"
tags = ['scheduler', 'producer']
dag_id = 'producer'
schedule = '@daily'
with DAG(
dag_id=dag_id,
start_date=start_date,
schedule=schedule,
catchup=False,
description=description,
tags=tags
):
## decorator with outlet so updates
## to dataset can be used as trigger
@task(outlets=[dataset])
## preprocess data and write to file
def preprocess_dataset():
with open(dataset.uri, 'a+') as file:
file.write('preprocessed data ready for consumption')
preprocess_dataset()
The @task decorator now has an outlet that tells Airflow that once this task ran the dataset dataset was updated and can use this event to trigger the following DAG:
from airflow import DAG, Dataset
from airflow.decorators import task
from datetime import datetime
dataset = Dataset('/tmp/preprocessed_data.txt')
start_date = datetime(2023,2,5)
description = "Start this pipeline when new data arrives"
tags = ['scheduler', 'consumer']
dag_id = 'consumer'
with DAG(
start_date=start_date,
dag_id=dag_id,
schedule=[dataset],
catchup=False,
description=description,
tags=tags
):
@task
## process prepared data and write to file
def process_dataset():
with open(dataset.uri, 'r') as file:
print(file.read())
process_dataset()
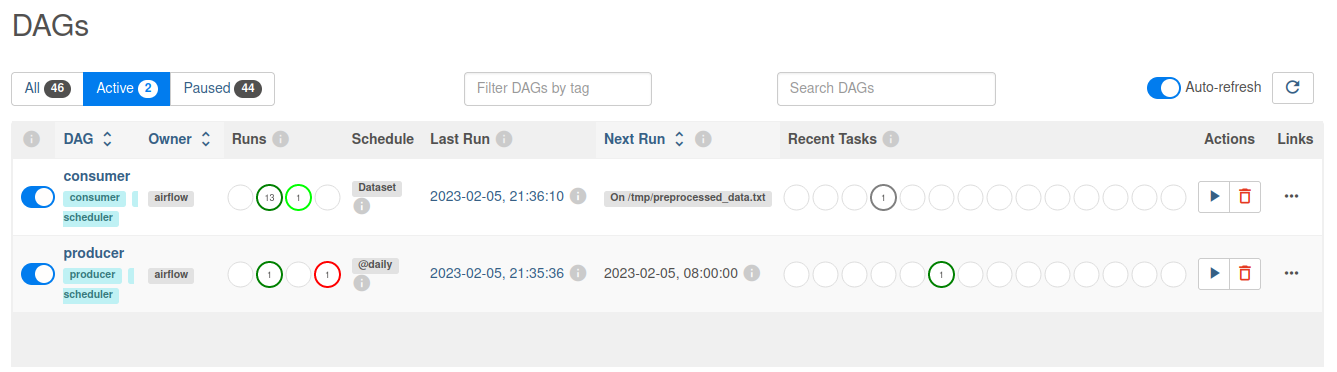
Now as soon as we trigger the Producer DAG the dataset in form of the text file will be updated which in turn triggers the Consumer DAG:
Debugging DAGs
I am certain that I was able to find the execution logs in the Airflow UI before... hmm not sure where they are hiding now. But you can enter the Airflow container and get the task log from there:
docker exec -ti airflow /bin/bash
airflow info
Apache Airflow
version | 2.5.1
executor | SequentialExecutor
task_logging_handler | airflow.utils.log.file_task_handler.FileTaskHandler
sql_alchemy_conn | sqlite:////opt/airflow/airflow.db
dags_folder | /opt/airflow/dags
plugins_folder | /opt/airflow/plugins
base_log_folder | /opt/airflow/logs
...
I was able to find the log file in:
/opt/airflow/logs/dag_id=producer/run_id=manual__2023-02-05T13:10:07.002907+00:00/task_id=preprocess_dataset
And catch the Python error that was crashing my flow.
Importing Datasets
In the example above we needed to define the dataset in both DAGs. A cleaner solution is to have a dataset definition file instead:
mkdir /opt/airflow/dags/include
nano /opt/airflow/dags/include/datasets.py
from airflow import Dataset
DATASET_01 = Dataset('/tmp/preprocessed_data.txt')
Now we can import the dataset where ever we need it:
from airflow import DAG
from airflow.decorators import task
from datetime import datetime
from include.datasets import DATASET_01
start_date = datetime(2023,2,5)
description = "Data pre-processing"
tags = ['scheduler', 'producer']
dag_id = 'producer'
schedule = '@daily'
with DAG(
dag_id=dag_id,
start_date=start_date,
schedule=schedule,
catchup=False,
description=description,
tags=tags
):
## decorator with outlet so updates
## to dataset can be used as trigger
@task(outlets=[DATASET_01])
## preprocess data and write to file
def preprocess_dataset():
with open(DATASET_01.uri, 'a+') as file:
file.write('preprocessed data ready for consumption')
preprocess_dataset()
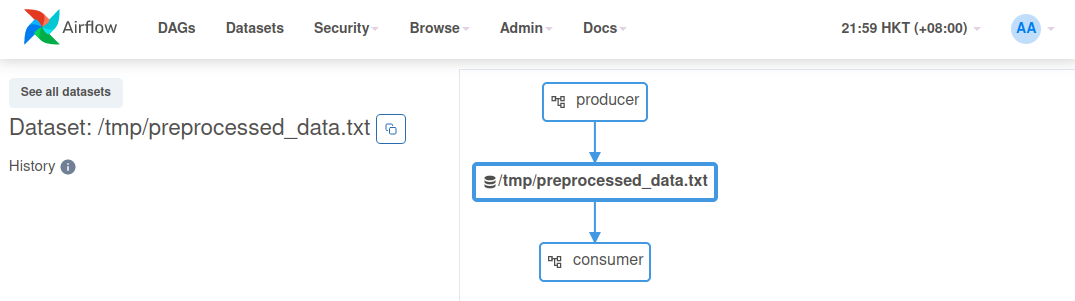
All your datasets and DAGs that depend on it can be monitored under the Datasets tab:
Airflow Sensors
With Dataset Schedulers Airflow monitors the successful completion of a task to trigger the next DAG. If we want to be able to react to other programs updating datasets we need to use Airflow Sensors instead. Sensors are a special type of Operator that are designed to do exactly one thing - wait for something to occur. It can be time-based, or waiting for a file, or an external event, but all they do is wait until something happens, and then succeed so their downstream tasks can run.
In the following example we receive data from 3 actors, have to pre-process it and after all data is collected process the prepared data:
Data Producer A -> Pre-Processing ->
Data Producer B -> Pre-Processing -> Processing
Data Producer C -> Pre-Processing ->
from airflow.models import DAG
from airflow.sensors.filesystem import FileSensor
from datetime import datetime
start_date = datetime(2023,2,5)
description = "Data pre-processing"
tags = ['sensor']
schedule = '@daily'
with DAG('dag_sensor',
schedule=schedule,
start_date=start_date,
description=description,
tags=tags
catchup=False
):
sensor_task = FileSensor(
task_id='waiting_for_change',
poke_interval=30,
# kill sensor if data does
# not arrive
timeout= 60 * 5,
# 'reschedule' or 'poke'
# the first releases the
# worker slot in between pokes
mode='reschedule',
# skip sensor after timeout
soft_fail=True,
filepath= '/tmp/input_data.txt'
)
...