MLFlow Docker
Part 2 of MLFlow in Docker.
Hyperopt
Distributed Asynchronous Hyper-parameter Optimization:
pip install hyperopt
from hyperopt import fmin, tpe, hp, Trials
Define the parameter you want to tune:
search_space = {
"lr": hp.loguniform("lr", -10, -8),
"l1": hp.choice("l1", [32, 64, 128]),
"l2": hp.choice("l2", [64, 128, 256])
}
And replace all parameters inside the lightning model accordingly:
class EmnistModel(pl.LightningModule):
def __init__(self, hparams):
super().__init__()
self.save_hyperparameters(hparams)
self.criterion = nn.CrossEntropyLoss()
self.network = nn.Sequential(
nn.Conv2d(1,32,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(32,64,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(2,2), # 64*14*14
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(2,2), # 256*7*7
nn.Flatten(),
nn.Linear(256*7*7, self.hparams["l1"]),
nn.ReLU(),
nn.Linear(self.hparams["l1"], self.hparams["l2"]),
nn.ReLU(),
nn.Linear(self.hparams["l2"], 26)
)
def forward(self, xb):
return self.network(xb.reshape(-1,1,28,28))
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr = self.hparams["lr"])
def training_step(self, batch, batch_idx):
# batches consists of images and labels
x, y = batch
# labels start at 1 but the classes at 0
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim = 1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("train_loss", loss, on_epoch=True, prog_bar=True)
self.log("train_acc", acc, on_epoch=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim=1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("val_loss", loss, on_epoch=True, prog_bar=True)
self.log("val_acc", acc, on_epoch=True, prog_bar=True)
return acc
def test_step(self, batch, batch_idx):
x, y = batch
y -= 1
y_hat = self(x)
loss = self.criterion(y_hat, y.long())
pred = y_hat.argmax(dim=1)
acc = accuracy(pred, y, task="multiclass", num_classes=26)
self.log("test_loss", loss, on_epoch=True, prog_bar=True)
self.log("test_acc", acc, on_epoch=True, prog_bar=True)
return acc
def predict_step(self, batch, batch_idx, dataloaders_idx=0):
x, y = batch
return self(x)
MLFlow
The model can now be executed with MLFlow:
def train_emnist(params):
# create a group of mlflow runs that nests all experiments
with mlflow.start_run(nested=True):
model = EmnistModel(params)
trainer = pl.Trainer(max_epochs=10, accelerator="gpu")
trainer.fit(model, train_dataloaders=train_dl, val_dataloaders=val_dl)
train_loss = trainer.callback_metrics["train_loss"].item()
train_acc = trainer.callback_metrics["train_acc"].item()
valid_loss = trainer.callback_metrics["val_loss"].item()
valid_acc = trainer.callback_metrics["val_acc"].item()
mlflow.log_params(params)
mlflow.log_metrics({
"train_loss_avg": train_loss, "train_acc_avg": train_acc,
"val_loss_avg": valid_loss, "val_loss_avg": valid_acc
})
input_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 1, 28, 28))])
output_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 26))])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
mlflow.pytorch.log_model(model, "emnist_classifier_hyper__cnn", signature=signature)
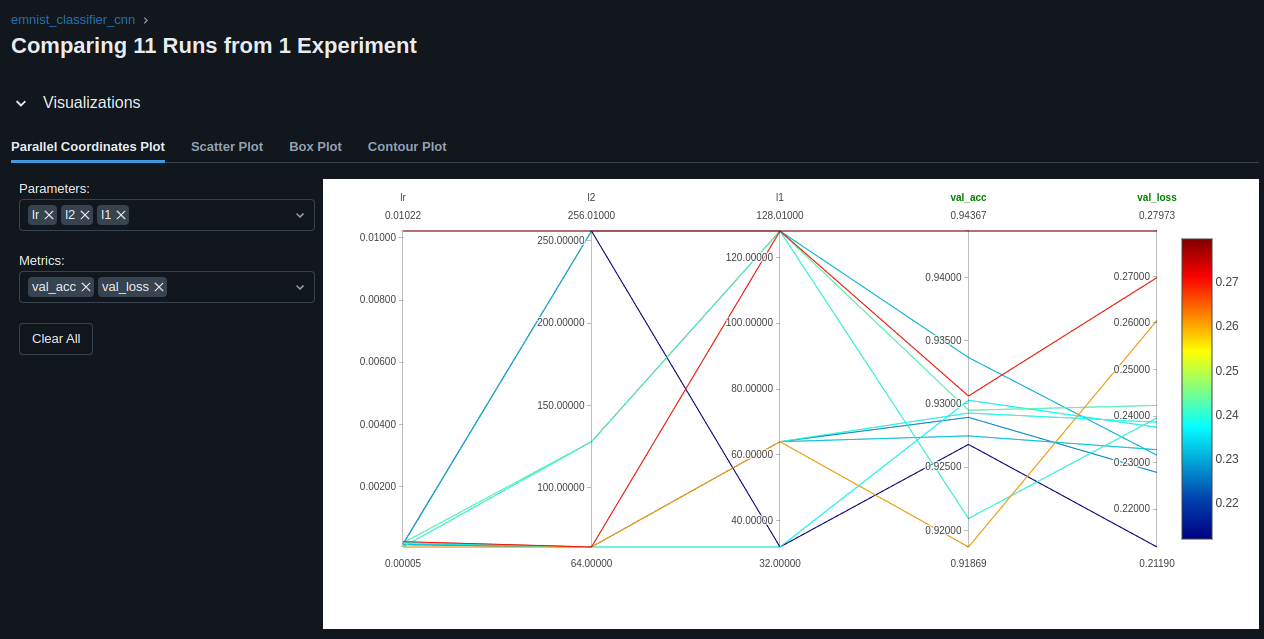
return -valid_acc # run optimization to minimize negative validation accuracy
with mlflow.start_run():
best_result = fmin(
fn=train_emnist,
space=search_space,
algo=tpe.suggest,
max_evals=10
)
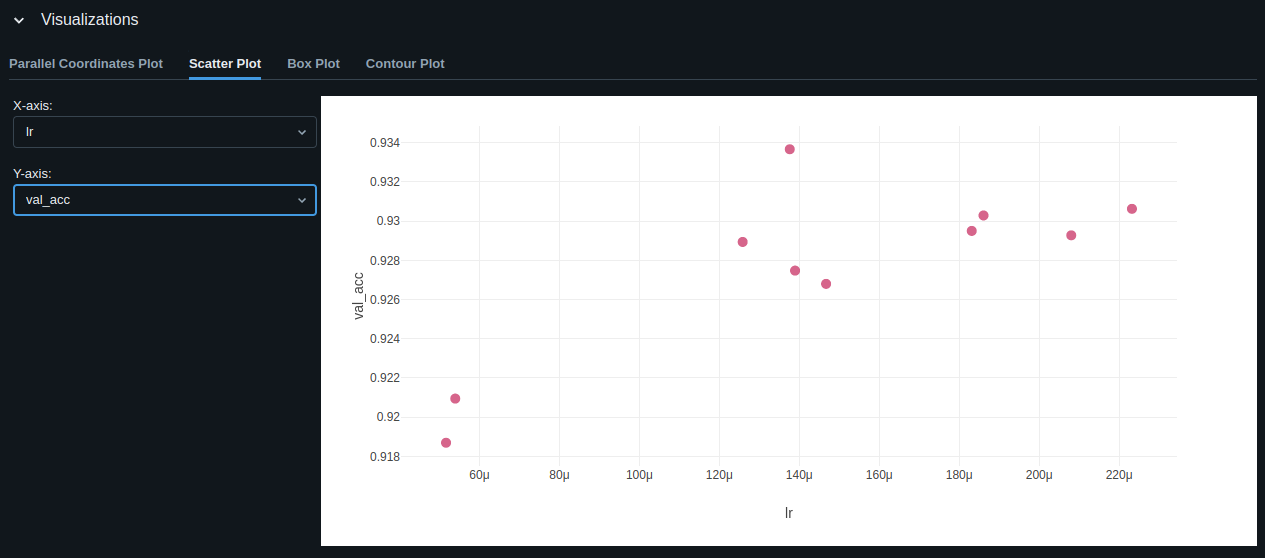
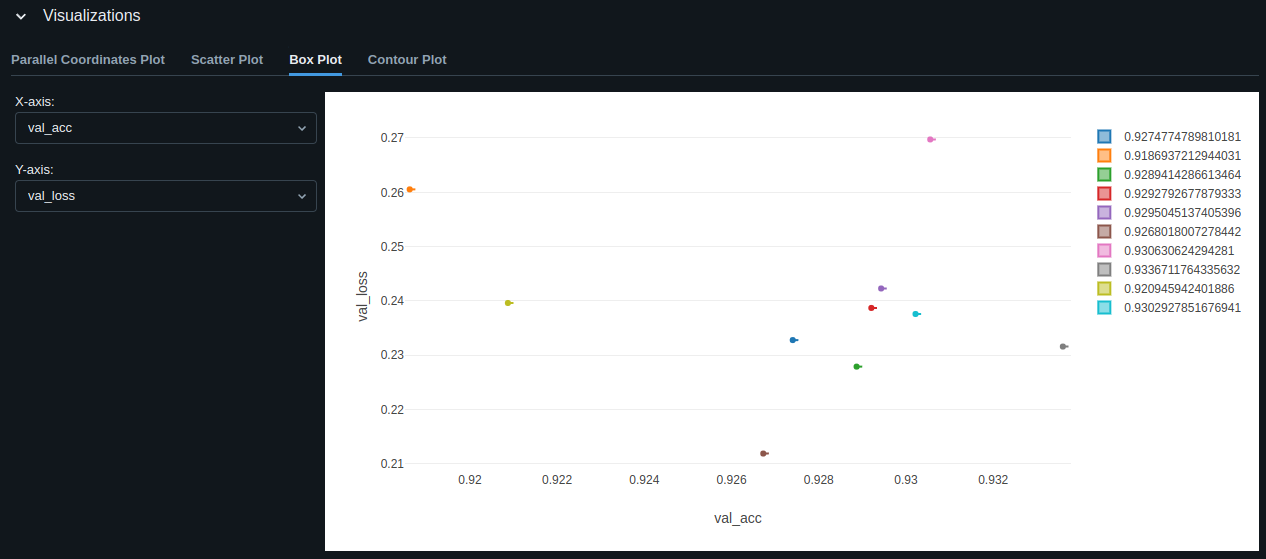
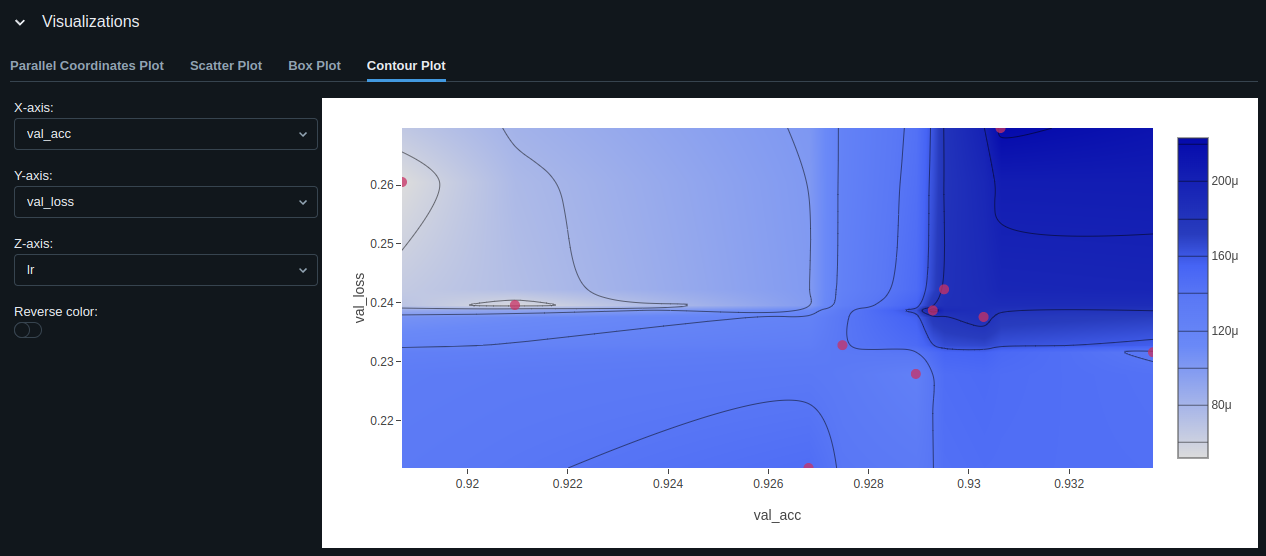
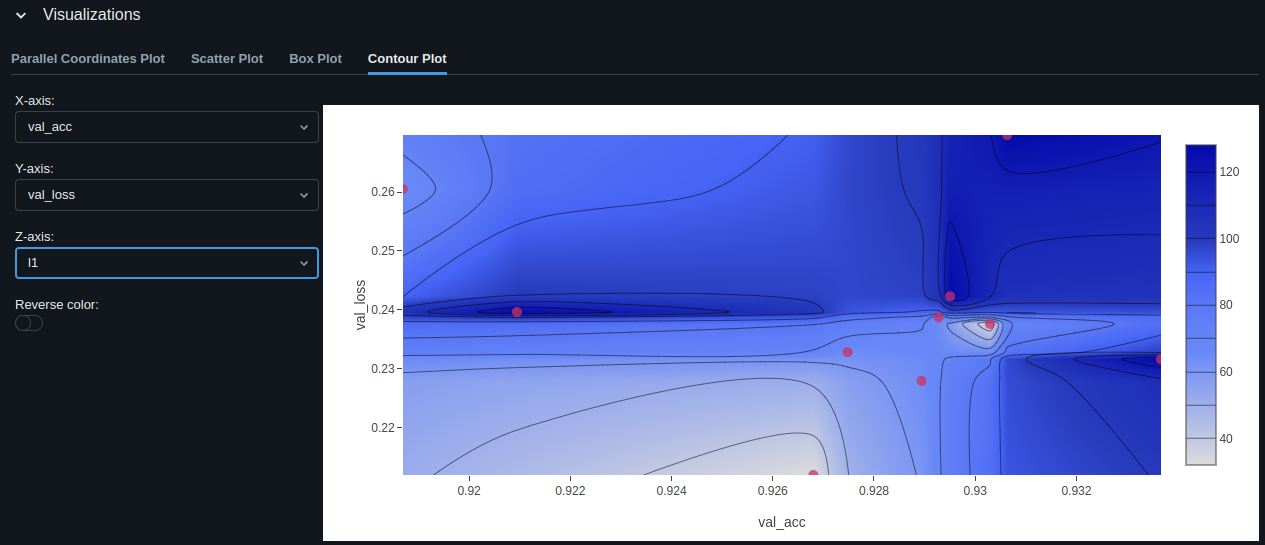
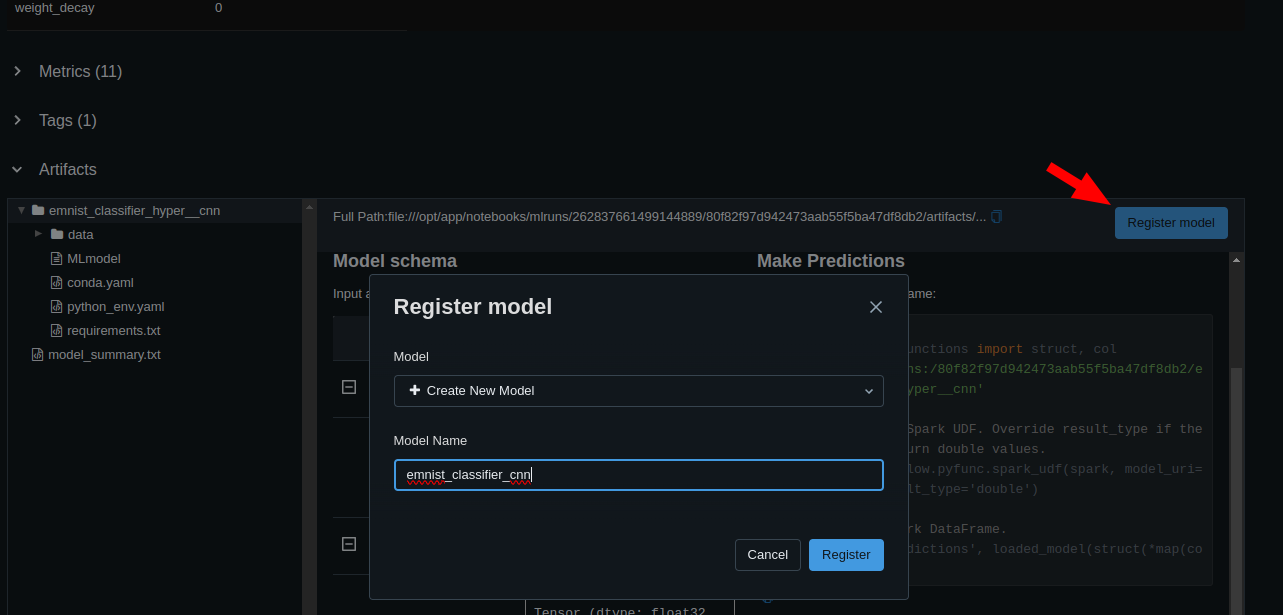
Best Model Evaluation
The model with the best validation accuracy is:
print(hyperopt.space_eval(search_space, best_result))
# {'l1': 128, 'l2': 256, 'lr': 0.00013761616014749492}
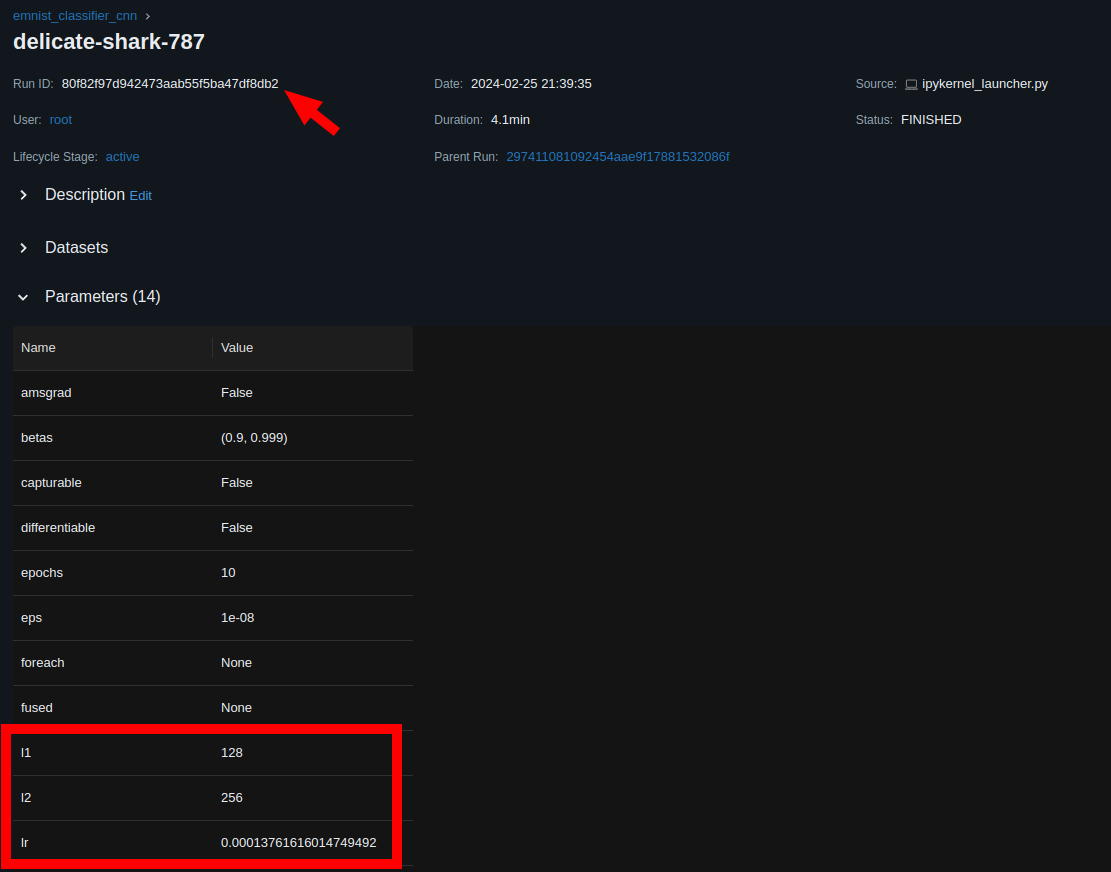
# get run ID for the above model from the MLFlow dashboard
logged_model = 'runs:/80f82f97d942473aab55f5ba47df8db2/emnist_classifier_hyper__cnn'
# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model)
predictions = loaded_model.predict(test_images.numpy().reshape(-1,1,28,28))
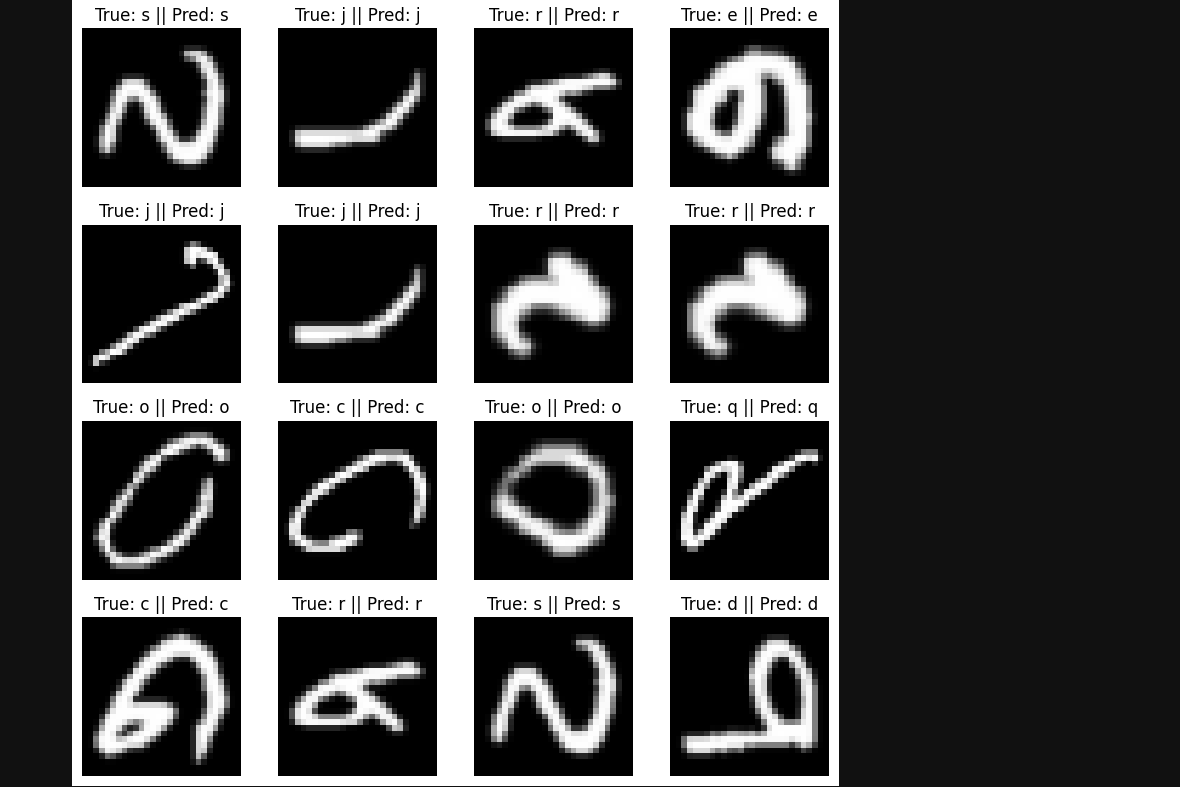
print("Predicted Class:", classes[np.argmax(predictions[0])])
test_samples = np.random.randint(0, len(test_images), 16)
fig = plt.figure(figsize = (8, 8))
for i, idx in enumerate(test_samples):
true_label = classes[int(test_labels[idx].item()) - 1]
pred_label = classes[np.argmax(predictions[idx])]
plt.subplot(4, 4, i+1)
plt.imshow(test_images[idx].numpy().reshape(-1,1,28,28).squeeze() / 255.0, cmap="gray")
plt.title(f"True: {true_label} || Pred: {pred_label}")
plt.axis('off')
plt.tight_layout()
plt.show()
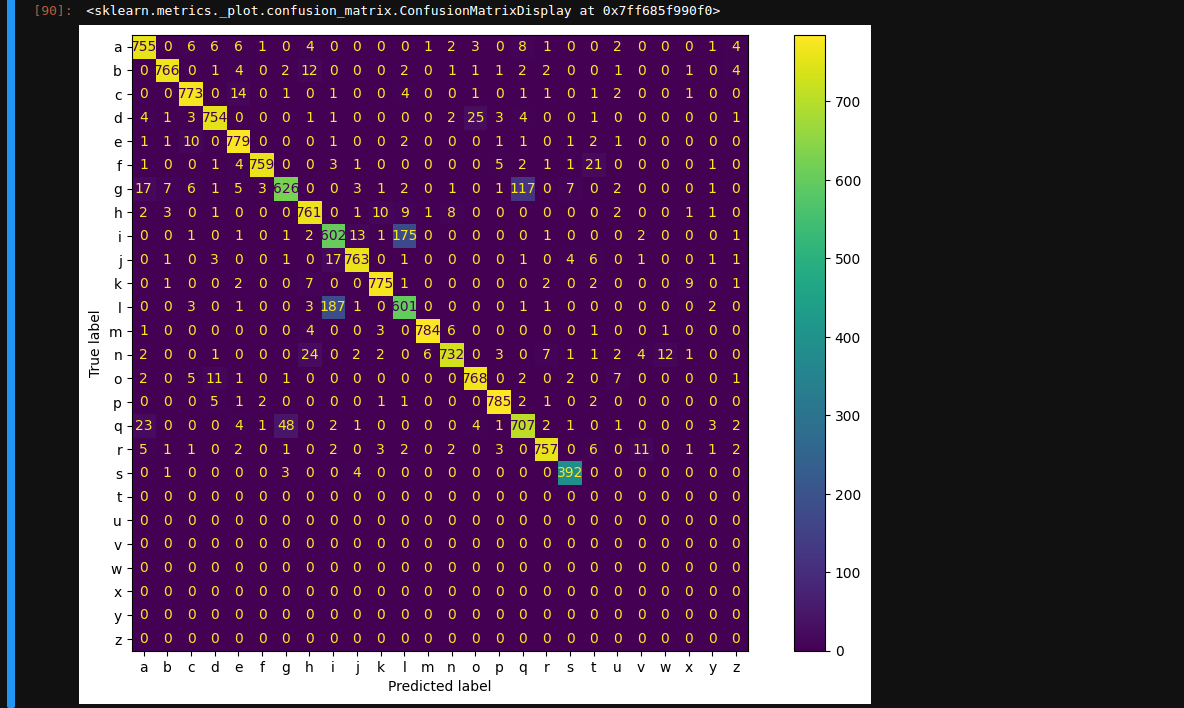
y_pred = []
y_true = []
for inputs, labels in test_dl:
output = loaded_model.predict(inputs.numpy().reshape(-1,1,28,28))
output = np.argmax(output, axis=1).astype('float64').tolist()
y_pred.extend(output)
labels = [x-1 for x in labels.tolist()]
y_true.extend(labels)
cm = confusion_matrix(y_true, y_pred)
confusion = ConfusionMatrixDisplay(cm, display_labels=classes)
fig, ax = plt.subplots(figsize = (12,8))
confusion.plot(ax = ax)
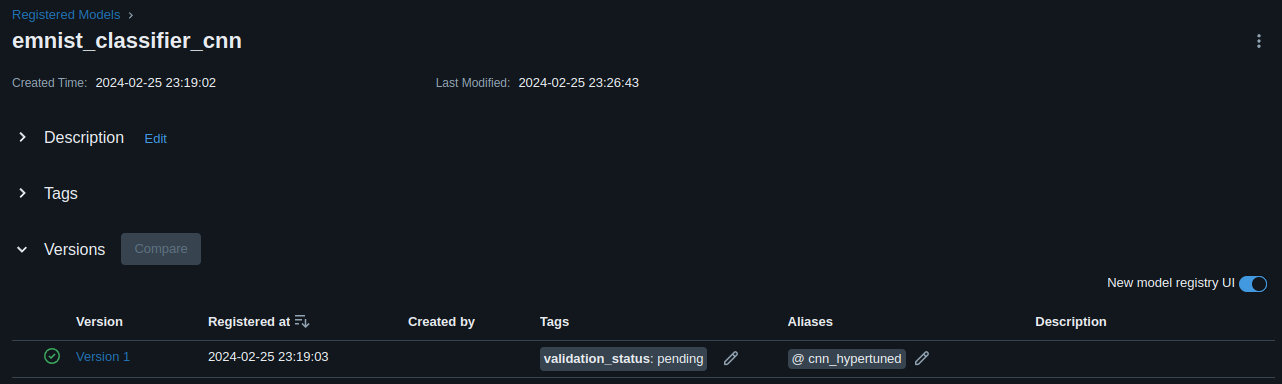
Model Registry
Once you picked a model to be the best model for your task you can register it in the MLFlow model registry: