
Serving your SciKit Learn Model as a Prediction API
- Serving your SciKit Learn Model as a Prediction API
Image Data Preprocessing
import collections
from glob import glob
import matplotlib.pyplot as plt
from matplotlib import patches
import numpy as np
import os
import pandas as pd
import pickle
import re
from scipy import ndimage
from skimage import (
io,
color,
exposure,
transform,
feature
)
import seaborn as sns
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay)
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler
SEED = 42
Image Dataset Preparation
Get Image Dataset from Local Directory
# get list of images https://paperswithcode.com/dataset/food-101
data_dir = os.listdir('dataset/animals')
print(data_dir)
# ['bear', 'cat', 'chicken', 'cow', 'deer', 'dog', 'duck', 'eagle', 'elephant', 'human', 'lion', 'monkey', 'mouse', 'panda', 'pigeon', 'rabbit', 'sheep', 'tiger', 'wolf']
glob('./dataset/animals/{}/*.jpg'.format('wolf'))
# ['./dataset/animals/wolf/wolffrontal0001.jpg',
# './dataset/animals/wolf/wolffrontal0002.jpg',
# './dataset/animals/wolf/wolffrontal0003.jpg',
# ...
all_files = []
for subfolder in data_dir:
all_files += glob('./dataset/animals/{}/*.jpg'.format(subfolder))
len(all_files)
# 2015
data_collection = io.ImageCollection(all_files)
data_collection.files
# ['./dataset/animals/bear/bearfrontal0001.jpg',
# './dataset/animals/bear/bearfrontal0002.jpg',
# './dataset/animals/bear/bearfrontal0003.jpg',
# './dataset/animals/bear/bearfrontal0004.jpg',
#...
Get Image Labels from Folder Structure
# use regular expression to extract folder name as label - example:
re.search(
r'./dataset/animals/(.*?)/',
'./dataset/animals/bear/bearfrontal0001.jpg'
).group(1)
# label extracted: 'bear'
def extract_labels(location):
label = re.search(
r'./dataset/animals/(.*?)/', location
).group(1)
return label
labels = list(map(extract_labels, data_collection.files))
list(set(labels))
# ['human',
# 'cat',
# 'lion',
# 'sheep',
# 'cow',
# 'mouse',
# 'pigeon',
# 'tiger',
# 'rabbit',
# 'elephant',
# 'deer',
# 'eagle',
# 'dog',
# 'wolf',
# 'panda',
# 'monkey',
# 'duck',
# 'chicken',
# 'bear']
Dataset Export
def buffer(item):
return item
# dataset_arrs = np.array(list(map(buffer,dataset)))
dataset_list = list(map(buffer, data_collection))
dataset_array = np.asarray(dataset_list)
dataset_array.shape
# (2015, 80, 80, 3)
data_dict = dict()
data_dict['description'] = '2015 80x80 RGB images of 19 classes.'
data_dict['data'] = dataset_array
data_dict['target'] = labels
data_dict['labels'] = set(labels)
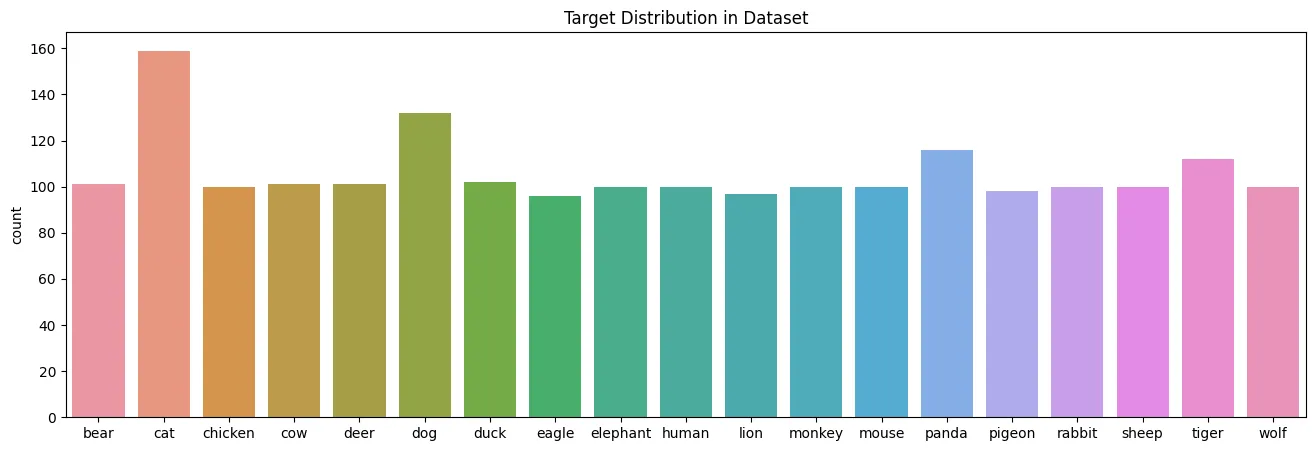
label_distribution = collections.Counter(data_dict['target'])
plt.figure(figsize=(16, 5))
plt.title('Target Distribution in Dataset')
sns.countplot(
data=data_dict,
x='target'
)
plt.savefig('assets/Scikit_Image_Model_Deployment_01.webp', bbox_inches='tight')
# plot multiple random images with labels
ran_gen = np.random.default_rng()
plt.figure(figsize=(12, 12))
for i in range(12):
ax = plt.subplot(4, 4, i+1)
random_index = ran_gen.integers(low=0, high=2015, size=1)
plt.imshow(data_dict['data'][random_index[0]])
plt.title(data_dict['target'][random_index[0]])
plt.axis(False)
plt.savefig('assets/Scikit_Image_Model_Deployment_02.webp', bbox_inches='tight')

# save the dateset
output = open('dataset/animals.pkl', 'wb')
pickle.dump(data_dict, output)
Data Preprocessing
# load dataset pickle
dataset = pickle.load(open('dataset/animals.pkl', 'rb'))
dataset['description']
X = dataset['data']
y = dataset['target']
# train-test-split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=SEED
)
print(X_train.shape, X_test.shape)
# (1612, 80, 80, 3) (403, 80, 80, 3)
Feature Extraction
Histogram of Oriented Gradients (HOG)
testimg = io.imread('assets/lion.jpg')
# hog feature descriptor
feature_vector, hog_image = feature.hog(testimg, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True, channel_axis=-1)
# Rescale histogram for better display
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 5))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5), sharex=True, sharey=True)
ax1.axis('off')
ax1.imshow(testimg, cmap=plt.cm.gray)
ax1.set_title('Input image')
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap=plt.cm.gray)
ax2.set_title('Histogram of Oriented Gradients')
plt.show()

class hog_transformer(BaseEstimator, TransformerMixin):
def __init__(
self,
orientations=9,
pixels_per_cell=(8, 8),
cells_per_block=(3, 3)
):
self.orientations = orientations
self.pixels_per_cell = pixels_per_cell
self.cells_per_block = cells_per_block
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
def local_hog(img):
feature_vector = feature.hog(
img,
orientations=self.orientations,
pixels_per_cell = self.pixels_per_cell,
cells_per_block = self.cells_per_block,
channel_axis=-1
)
return feature_vector
return [local_hog(x) for x in X]
Model Training
SGD Classifier Training Pipeline
- Feature Extraction
- Normalization
- Model Fitting
feature_extractor = hog_transformer()
scaler = StandardScaler()
model_sgd = SGDClassifier(loss='hinge', learning_rate='adaptive', eta0=0.1, early_stopping=True)
X_train_fv = feature_extractor.fit_transform(X_train)
X_test_fv = feature_extractor.transform(X_test)
X_train_fv_scaled = scaler.fit_transform(X_train_fv)
X_test_fv_scaled = scaler.transform(X_test_fv)
model_sgd.fit(X_train_fv_scaled, y_train)
Model Evaluation
y_pred = model_sgd.predict(X_test_fv_scaled)
# plot predictions
ran_gen = np.random.default_rng()
plt.figure(figsize=(12, 12))
for i in range(12):
ax = plt.subplot(4, 4, i+1)
random_index = ran_gen.integers(low=0, high=403, size=1)
plt.imshow(X_test[random_index[0]])
plt.title(y_pred[random_index[0]])
plt.axis(False)
plt.savefig('assets/Scikit_Image_Model_Deployment_04.webp', bbox_inches='tight')

conf_mtx = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(y_test, y_pred.tolist()),
display_labels=[False]
)
conf_mtx.plot(cmap='plasma')
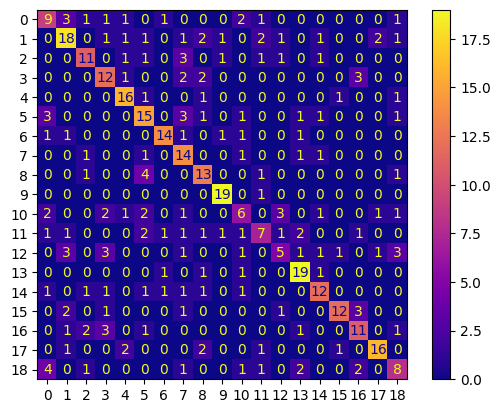
eval_report = classification_report(y_test, y_pred, output_dict=True)
eval_df = pd.DataFrame(eval_report)
eval_df.transpose()
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| bear | 0.428571 | 0.450000 | 0.439024 | 20.000000 |
| cat | 0.600000 | 0.562500 | 0.580645 | 32.000000 |
| chicken | 0.611111 | 0.550000 | 0.578947 | 20.000000 |
| cow | 0.500000 | 0.600000 | 0.545455 | 20.000000 |
| deer | 0.695652 | 0.800000 | 0.744186 | 20.000000 |
| dog | 0.517241 | 0.576923 | 0.545455 | 26.000000 |
| duck | 0.777778 | 0.700000 | 0.736842 | 20.000000 |
| eagle | 0.466667 | 0.736842 | 0.571429 | 19.000000 |
| elephant | 0.541667 | 0.650000 | 0.590909 | 20.000000 |
| human | 0.826087 | 0.950000 | 0.883721 | 20.000000 |
| lion | 0.375000 | 0.300000 | 0.333333 | 20.000000 |
| monkey | 0.466667 | 0.350000 | 0.400000 | 20.000000 |
| mouse | 0.416667 | 0.250000 | 0.312500 | 20.000000 |
| panda | 0.678571 | 0.826087 | 0.745098 | 23.000000 |
| pigeon | 0.631579 | 0.600000 | 0.615385 | 20.000000 |
| rabbit | 0.800000 | 0.600000 | 0.685714 | 20.000000 |
| sheep | 0.550000 | 0.550000 | 0.550000 | 20.000000 |
| tiger | 0.800000 | 0.695652 | 0.744186 | 23.000000 |
| wolf | 0.444444 | 0.400000 | 0.421053 | 20.000000 |
| accuracy | 0.588089 | 0.588089 | 0.588089 | 0.588089 |
| macro avg | 0.585669 | 0.586737 | 0.580204 | 403.000000 |
| weighted avg | 0.587659 | 0.588089 | 0.582170 | 403.000000 |
Hyperparameter Tuning
Training Pipeline
train_pipeline = Pipeline([
('feature_extraction', hog_transformer(
orientations=9,
pixels_per_cell=(8, 8),
cells_per_block=(3, 3))
),
('normalization', StandardScaler()),
('model_training', SGDClassifier(
loss='hinge', eta0=0.1,
learning_rate='adaptive',
early_stopping=True)
)
])
train_pipeline.fit(X_train, y_train)
y_pred_pipe = train_pipeline.predict(X_test)
eval_report = classification_report(y_test, y_pred_pipe, output_dict=True)
eval_df = pd.DataFrame(eval_report)
eval_df.transpose()
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| bear | 0.368421 | 0.350000 | 0.358974 | 20.000000 |
| cat | 0.607143 | 0.531250 | 0.566667 | 32.000000 |
| chicken | 0.571429 | 0.600000 | 0.585366 | 20.000000 |
| cow | 0.681818 | 0.750000 | 0.714286 | 20.000000 |
| deer | 0.772727 | 0.850000 | 0.809524 | 20.000000 |
| dog | 0.354839 | 0.423077 | 0.385965 | 26.000000 |
| duck | 0.500000 | 0.550000 | 0.523810 | 20.000000 |
| eagle | 0.473684 | 0.473684 | 0.473684 | 19.000000 |
| elephant | 0.444444 | 0.600000 | 0.510638 | 20.000000 |
| human | 0.680000 | 0.850000 | 0.755556 | 20.000000 |
| lion | 0.500000 | 0.350000 | 0.411765 | 20.000000 |
| monkey | 0.500000 | 0.400000 | 0.444444 | 20.000000 |
| mouse | 0.307692 | 0.200000 | 0.242424 | 20.000000 |
| panda | 0.772727 | 0.739130 | 0.755556 | 23.000000 |
| pigeon | 0.608696 | 0.700000 | 0.651163 | 20.000000 |
| rabbit | 0.600000 | 0.600000 | 0.600000 | 20.000000 |
| sheep | 0.500000 | 0.550000 | 0.523810 | 20.000000 |
| tiger | 0.722222 | 0.565217 | 0.634146 | 23.000000 |
| wolf | 0.789474 | 0.750000 | 0.769231 | 20.000000 |
| accuracy | 0.568238 | 0.568238 | 0.568238 | 0.568238 |
| macro avg | 0.566069 | 0.570124 | 0.564053 | 403.000000 |
| weighted avg | 0.567078 | 0.568238 | 0.563651 | 403.000000 |
GridSearch
estimator = Pipeline([
('feature_extraction', hog_transformer()),
('normalization', StandardScaler()),
('model_training', SGDClassifier())
])
param_grid = [
{
'feature_extraction__orientations': [7, 8, 9, 10, 11],
'feature_extraction__pixels_per_cell': [(7, 7), (8, 8), (9, 9)],
'feature_extraction__cells_per_block': [(2, 2), (3, 3), (4, 4)],
'model_training__loss': ['hinge', 'squared_hinge', 'perceptron'],
'model_training__eta0': [0.001, 0.1, 1],
'model_training__learning_rate': ['optimal', 'adaptive']
}
]
model_grid = GridSearchCV(
estimator,
param_grid,
scoring='accuracy',
cv=3,
n_jobs=-1,
verbose=2
)
model_grid.fit(X_train, y_train)
# Fitting 3 folds for each of 810 candidates, totalling 2430 fits
# time for a coffee break :)
Best Model Evaluation
model_grid.best_params_
model_grid.best_score_
model_best = model_grid.best_estimator_
y_pred_best = model_best.predict(X_test)
eval_report_best = classification_report(y_test, y_pred_best, output_dict=True)
eval_best_df = pd.DataFrame(eval_report_best)
eval_best_df.transpose()
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| bear | 0.680000 | 0.850000 | 0.755556 | 20.000000 |
| cat | 0.750000 | 0.656250 | 0.700000 | 32.000000 |
| chicken | 0.809524 | 0.850000 | 0.829268 | 20.000000 |
| cow | 0.809524 | 0.850000 | 0.829268 | 20.000000 |
| deer | 0.869565 | 1.000000 | 0.930233 | 20.000000 |
| dog | 0.607143 | 0.653846 | 0.629630 | 26.000000 |
| duck | 0.789474 | 0.750000 | 0.769231 | 20.000000 |
| eagle | 0.647059 | 0.578947 | 0.611111 | 19.000000 |
| elephant | 0.782609 | 0.900000 | 0.837209 | 20.000000 |
| human | 1.000000 | 0.900000 | 0.947368 | 20.000000 |
| lion | 0.692308 | 0.450000 | 0.545455 | 20.000000 |
| monkey | 0.631579 | 0.600000 | 0.615385 | 20.000000 |
| mouse | 0.684211 | 0.650000 | 0.666667 | 20.000000 |
| panda | 0.916667 | 0.956522 | 0.936170 | 23.000000 |
| pigeon | 0.666667 | 0.800000 | 0.727273 | 20.000000 |
| rabbit | 0.866667 | 0.650000 | 0.742857 | 20.000000 |
| sheep | 0.750000 | 0.750000 | 0.750000 | 20.000000 |
| tiger | 0.800000 | 0.869565 | 0.833333 | 23.000000 |
| wolf | 0.809524 | 0.850000 | 0.829268 | 20.000000 |
| accuracy | 0.764268 | 0.764268 | 0.764268 | 0.764268 |
| macro avg | 0.766448 | 0.766586 | 0.762383 | 403.000000 |
| weighted avg | 0.765251 | 0.764268 | 0.760746 | 403.000000 |
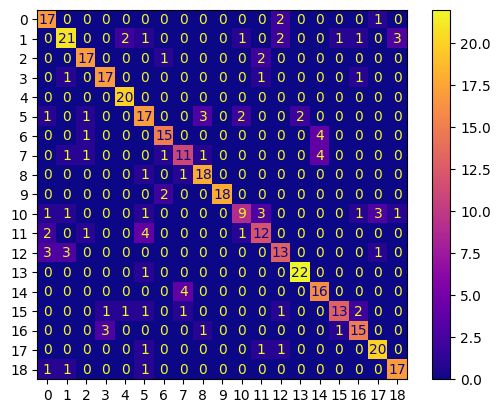
conf_mtx_best = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(y_test, y_pred_best.tolist()),
display_labels=[False]
)
conf_mtx_best.plot(cmap='plasma')
# plot predictions
ran_gen = np.random.default_rng()
plt.figure(figsize=(12, 12))
for i in range(12):
ax = plt.subplot(4, 4, i+1)
random_index = ran_gen.integers(low=0, high=403, size=1)
plt.imshow(X_test[random_index[0]])
plt.title(y_pred_best[random_index[0]])
plt.axis(False)
plt.savefig('assets/Scikit_Image_Model_Deployment_07.webp', bbox_inches='tight')

Trained Model Export
# save the model
output = open('model/animal_model_best.pkl', 'wb')
pickle.dump(model_best, output)
Deployment Model
Model Training
best_params = {'feature_extraction__cells_per_block': (2, 2),
'feature_extraction__orientations': 11,
'feature_extraction__pixels_per_cell': (8, 8),
'model_training__eta0': 0.1,
'model_training__learning_rate': 'optimal',
'model_training__loss': 'perceptron'}
feature_extractor_pipe = make_pipeline(
hog_transformer(
orientations=11,
pixels_per_cell=(8, 8),
cells_per_block=(2, 2))
)
feature_vectors = feature_extractor_pipe.fit_transform(X_train)
normalizer = StandardScaler()
feature_normed = normalizer.fit_transform(feature_vectors)
classifier = SGDClassifier(
loss='perceptron', eta0=0.1,
learning_rate='optimal',
early_stopping=True
)
classifier.fit(feature_normed, y_train)
Model Evaluation
feature_vectors_test = feature_extractor_pipe.transform(X_test)
feature_normed_test = normalizer.transform(feature_vectors_test)
y_pred_deploy = classifier.predict(feature_normed_test)
eval_report_best = classification_report(y_test, y_pred_deploy, output_dict=True)
eval_best_df = pd.DataFrame(eval_report_best)
eval_best_df.transpose()
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| bear | 0.700000 | 0.700000 | 0.700000 | 20.00000 |
| cat | 0.862069 | 0.781250 | 0.819672 | 32.00000 |
| chicken | 0.937500 | 0.750000 | 0.833333 | 20.00000 |
| cow | 0.625000 | 0.750000 | 0.681818 | 20.00000 |
| deer | 0.809524 | 0.850000 | 0.829268 | 20.00000 |
| dog | 0.588235 | 0.769231 | 0.666667 | 26.00000 |
| duck | 0.750000 | 0.750000 | 0.750000 | 20.00000 |
| eagle | 0.590909 | 0.684211 | 0.634146 | 19.00000 |
| elephant | 0.761905 | 0.800000 | 0.780488 | 20.00000 |
| human | 1.000000 | 0.950000 | 0.974359 | 20.00000 |
| lion | 0.647059 | 0.550000 | 0.594595 | 20.00000 |
| monkey | 0.875000 | 0.700000 | 0.777778 | 20.00000 |
| mouse | 0.647059 | 0.550000 | 0.594595 | 20.00000 |
| panda | 0.956522 | 0.956522 | 0.956522 | 23.00000 |
| pigeon | 0.666667 | 0.800000 | 0.727273 | 20.00000 |
| rabbit | 0.769231 | 0.500000 | 0.606061 | 20.00000 |
| sheep | 0.619048 | 0.650000 | 0.634146 | 20.00000 |
| tiger | 0.800000 | 0.869565 | 0.833333 | 23.00000 |
| wolf | 0.761905 | 0.800000 | 0.780488 | 20.00000 |
| accuracy | 0.749380 | 0.749380 | 0.749380 | 0.74938 |
| macro avg | 0.756191 | 0.745304 | 0.746028 | 403.00000 |
| weighted avg | 0.759071 | 0.749380 | 0.749534 | 403.00000 |
Model Export
# save the model
output = open('model/animal_model_deployment.pkl', 'wb')
pickle.dump(classifier, output)
# save fitted normalizer
output = open('model/animal_model_deployment_scaler.pkl', 'wb')
pickle.dump(normalizer, output)