
Serving your SciKit Learn Model as a Prediction API
Preparing the ML Model
Data Preprocessing
Advertisement Dataset: Use the advertising dataset given in ISLR and analyse the relationship between advertisement channels and sales.
import joblib
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.model_selection import train_test_split
SEED = 42
adv_df = pd.read_csv('dataset/advertising.csv')
adv_df.head(5)
| TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|
| 0 | 230.1 | 37.8 | 69.2 | 22.1 |
| 1 | 44.5 | 39.3 | 45.1 | 10.4 |
| 2 | 17.2 | 45.9 | 69.3 | 9.3 |
| 3 | 151.5 | 41.3 | 58.5 | 18.5 |
| 4 | 180.8 | 10.8 | 58.4 | 12.9 |
adv_df.describe()
| TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|
| count | 200.000000 | 200.000000 | 200.000000 | 200.000000 |
| mean | 147.042500 | 23.264000 | 30.554000 | 14.022500 |
| std | 85.854236 | 14.846809 | 21.778621 | 5.217457 |
| min | 0.700000 | 0.000000 | 0.300000 | 1.600000 |
| 25% | 74.375000 | 9.975000 | 12.750000 | 10.375000 |
| 50% | 149.750000 | 22.900000 | 25.750000 | 12.900000 |
| 75% | 218.825000 | 36.525000 | 45.100000 | 17.400000 |
| max | 296.400000 | 49.600000 | 114.000000 | 27.000000 |
# features / labels split
X = adv_df.drop('Sales', axis=1)
y = adv_df['Sales']
# train, validation and test split
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.3, random_state=SEED
)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=SEED
)
print(len(X), len(X_train), len(X_val), len(X_test))
# 200 140 30 30
Model Training
model = RandomForestRegressor(
n_estimators=3,
random_state=SEED
)
model.fit(X_train, y_train)
Model Validation
# validate model performance and tune hyper parameter
val_preds = model.predict(X_val)
print(mean_absolute_error(y_val, val_preds))
print(mean_squared_error(y_val, val_preds)**0.5)
# 0.7566666666666663 MAE should be small compared to MEAN 14.022500
# 0.9330753611738063 RMSE should be small compared to STD 5.217457
adv_df.describe()['Sales']
| count | 200.000000 |
| mean | 14.022500 |
| std | 5.217457 |
| min | 1.600000 |
| 25% | 10.375000 |
| 50% | 12.900000 |
| 75% | 17.400000 |
| max | 27.000000 |
| Name: Sales, dtype: float64 |
# try to improve the model by adding estimators
model2 = RandomForestRegressor(
n_estimators=30,
random_state=SEED
)
model2.fit(X_train, y_train)
val_preds2 = model2.predict(X_val)
print(mean_absolute_error(y_val, val_preds2))
print(mean_squared_error(y_val, val_preds2)**0.5)
# 0.483111111111111 MAE should be small compared to MEAN 14.022500
# 0.6177971619660723 RMSE should be small compared to STD 5.217457
Model Testing
# retest the optimized model on unseen data
test_preds = model2.predict(X_test)
print(mean_absolute_error(y_test, test_preds))
print(mean_squared_error(y_test, test_preds)**0.5)
# 0.5649999999999998 MAE should be small compared to MEAN 14.022500
# 0.6758333675845999 RMSE should be small compared to STD 5.217457
Model Saving
production_model = RandomForestRegressor(
n_estimators=30,
random_state= SEED
)
# fit production model to entire dataset
production_model.fit(X, y)
# save model for deployment
joblib.dump(production_model, 'models/production_model.pkl')
list(X.columns)
# ['TV', 'Radio', 'Newspaper']
joblib.dump(list(X.columns), 'models/production_model_column_names.pkl')
Model Loading
column_names = joblib.load('models/production_model_column_names.pkl')
column_names
# ['TV', 'Radio', 'Newspaper']
loaded_model = joblib.load('models/production_model.pkl')
print(loaded_model.predict([X.iloc[42]]))
print(loaded_model.predict([[180.8, 10.8, 58.4]]))
# [20.68666667] TRUE 20.7
#[13.28] TRUE 12.9
Preparing the Model API
Install Flask:
pip install flask
And prepare the prediction API route:
Prediction_API.py
from flask import Flask, request, jsonify
import joblib
import pandas as pd
model = joblib.load('models/production_model.pkl')
col_names = joblib.load('models/production_model_column_names.pkl')
app = Flask(__name__)
# wait for json post request and return prediction
@app.route('/api', methods=['POST'])
def predict():
req_data = request.json
df = pd.DataFrame(req_data).reindex(columns=col_names)
prediction = list(model.predict(df))
return jsonify({'prediction': str(prediction)})
# load the model and start web api
if __name__ == 'main':
app.run()
Start the application by running:
export FLASK_ENV=development
export FLASK_APP=Prediction_API
flask run

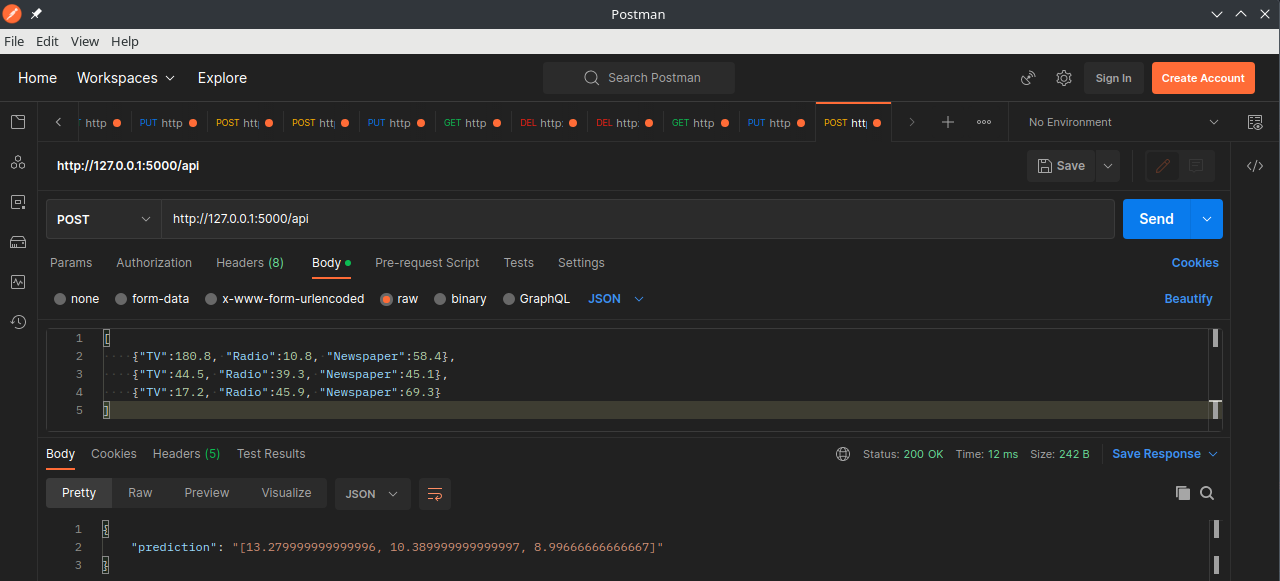
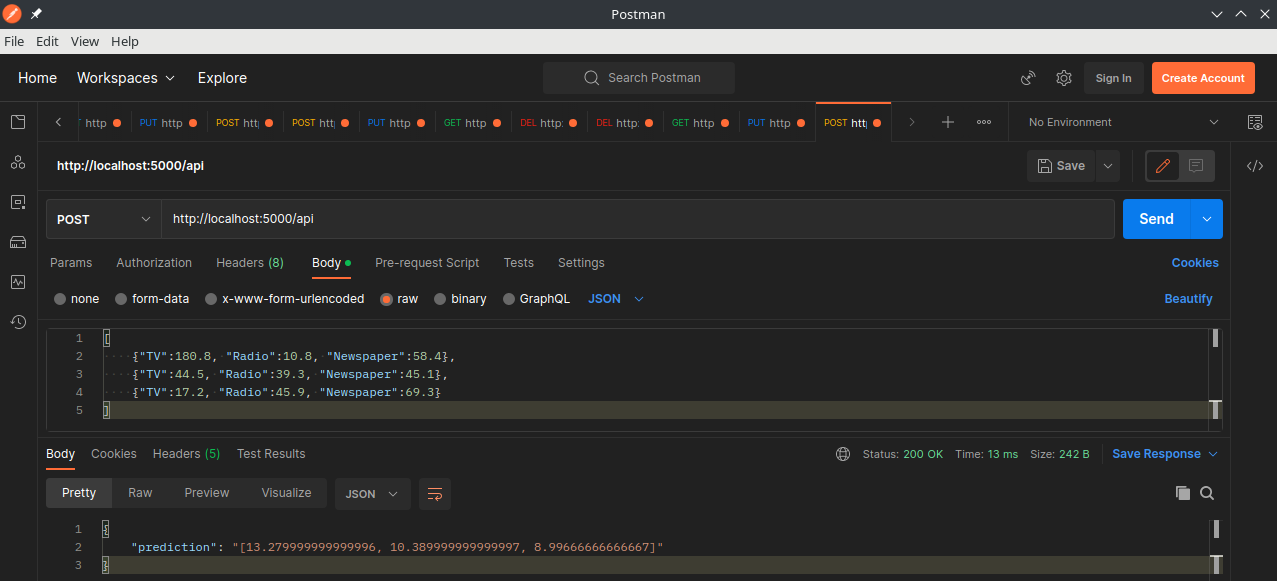
We can now use Postman to POST 3 datapoints from our dataset to the API endpoint:
[
{"TV":180.8, "Radio":10.8, "Newspaper":58.4},
{"TV":44.5, "Radio":39.3, "Newspaper":45.1},
{"TV":17.2, "Radio":45.9, "Newspaper":69.3}
]
As they are from our labelled dataset we know that the prediction response should be around 12.9, 10.4 and 9.3 for those 3 datapoints:
{
"prediction": "[13.279999999999996, 10.389999999999997, 8.99666666666667]"
}
Containerizing the Application
Preparations
Prepare the necessary files:
.
├── Dockerfile
├── app.py
├── models
│ ├── production_model_column_names.pkl
│ └── production_model.pkl
└── requirements.txt
Take the latest pickle files from your model training and copy the Flask app into app.py:
from flask import Flask, request, jsonify
import joblib
import pandas as pd
model = joblib.load('models/production_model.pkl')
col_names = joblib.load('models/production_model_column_names.pkl')
app = Flask(__name__)
# wait for json post request and return prediction
@app.route('/api', methods=['POST'])
def predict():
req_data = request.json
df = pd.DataFrame(req_data).reindex(columns=col_names)
prediction = list(model.predict(df))
return jsonify({'prediction': str(prediction)})
# load the model and start web api
if __name__ == 'main':
app.run()
Define all the Python dependencies that need to be installed inside the container for the app to work in requirements.txt:
blinker==1.6.2
click==8.1.3
joblib==1.2.0
Flask==2.3.2
itsdangerous==2.1.2
Jinja2==3.1.2
MarkupSafe==2.1.2
numpy==1.25.0
pandas==2.0.2
scikit-learn==1.2.2
Werkzeug==2.3.6
And the Dockerfile to build the container with:
# base image to use
FROM python:3.10-slim-bookworm
# dir name inside the container used for your app
WORKDIR /opt/python_app
# copy all files into the work dir
COPY . .
# install python dependencies
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
# execute the app when container starts
EXPOSE 5000/tcp
CMD [ "python", "-m" , "flask", "--app", "app", "run", "--host=0.0.0.0"]
Building the Docker Image
You can simply run docker build --tag flask-app . to build the container using Docker. But I started getting deprecation warnings on the build command and that it is going to be replaced by buildx and the installation guide for this still feels a bit flaky...
But I wanted to use Podman Desktop for a while. So let's give that a try then :)
Install the package from Flathub:
flatpak install flathub io.podman_desktop.PodmanDesktop
And run the application using:
flatpak run io.podman_desktop.PodmanDesktop
After clicking on Create Container and selecting from Dockerfile:
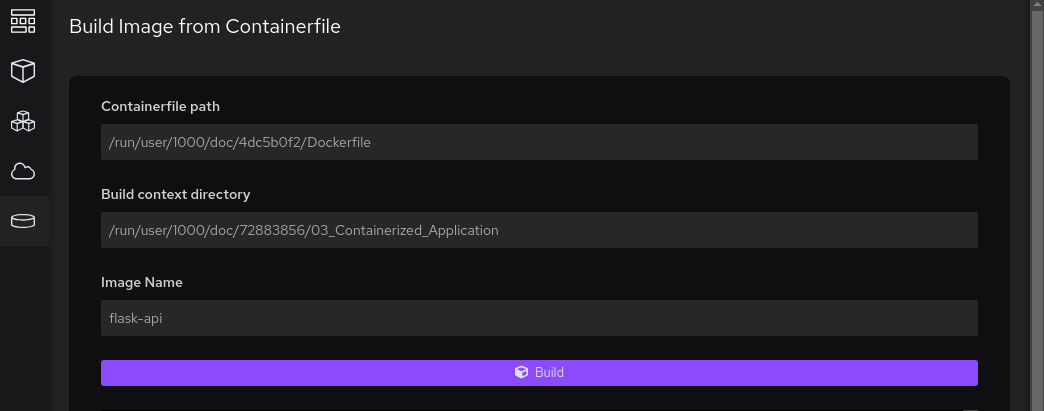
I ran into my first issue - which, I am sure, is actually a Flatpack issue. You have to point the builder to your Dockerfile. But since the file is then copied into a temp directory that the Flatpack app is allowed to access you then also have to point to the Build Context Directory to the containing folder. This will copy everything inside this folder into a different temp folder. Otherwise the build will fail because it cannot find the requirements.txt file:
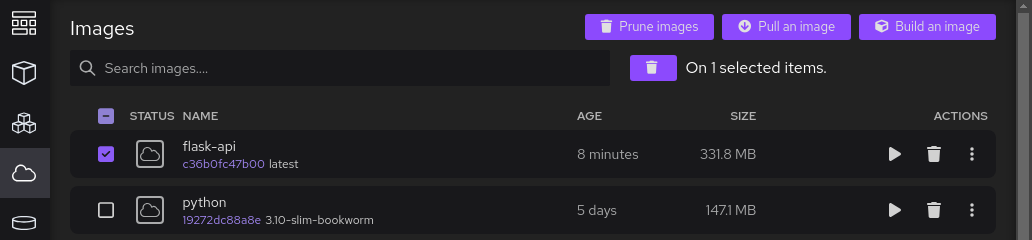
Click on Build and wait for the process to finish:
Running the Docker Container
To run the container in Docker we just need to make sure that the API port is exposed. In the code above By default Flask uses port 5000 and the Dockerfile above exposed this port when building the Docker image. So all I need to do is to run:
docker run -P flask-api
This exposes the REST API to a random outer port 32773 - which is what you want in a cloud-native environment:

To get more control you can override the default port by - e.g. setting the outer port to 8080:
docker run -d --rm -p 8080:5000 flask-api
![]()
Or going back to Podman Desktop:
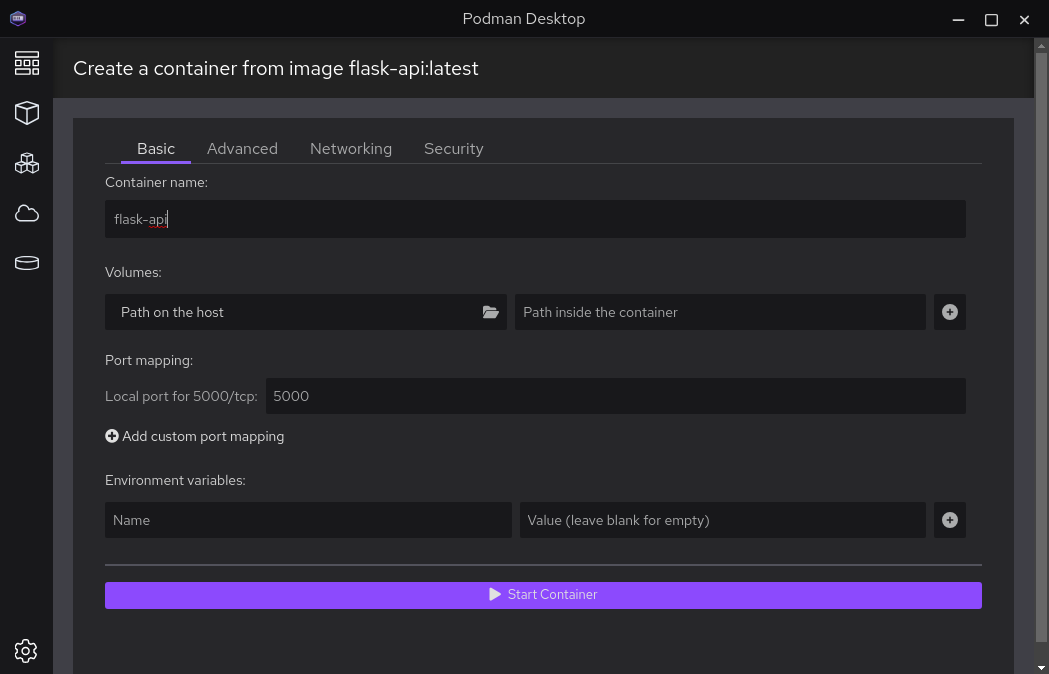

With those settings the API is now exposed on it's native port 5000 and can be tested using Postman:
React.js Frontend
Using Vite to scaffold a basic React frontend:
npm create vite@latest
cd into/directory
npm install
npm run dev
Add a component that fetches the prediction from your backend API and import it to your page:
import React, { useState } from 'react';
const apiUrl = 'http://localhost:5000/api'
const method = 'POST'
const mode = 'cors'
const headers = {
'content-type': 'application/json'
}
const jsonData = [ {"TV":17.2, "Radio":45.9, "Newspaper":69.3} ]
const makeRequest = async (data) => {
const res = await fetch(apiUrl, {
method: method,
mode: mode,
cache: "no-cache",
credentials: "same-origin",
headers: headers,
body: JSON.stringify(data)
});
const response = await res.json();
return response;
};
export default function App() {
const [answer, setAnswer] = useState();
const submit = async () => {
const res = await makeRequest(jsonData);
setAnswer(parseFloat(res.prediction.replace("[", "").replace("]", "")));
};
return (
<>
<button onClick={submit}>Send</button>
<div><p>Sales: {JSON.stringify(answer)}</p></div>
</>
);
}
The frontend takes the hard coded values [{"TV":17.2, "Radio":45.9, "Newspaper":69.3}] and requests a prediction on them when the button is pressed.
Now we are only missing an input field that allows the user to send a custom request:
import React, { useId, useState } from 'react';
// prepare request
const apiUrl = 'http://localhost:5000/api'
const method = 'POST'
const mode = 'cors'
const cache = "no-cache"
const credentials = "same-origin"
const headers = {
'content-type': 'application/json'
}
// default request data
const jsonData = [{"TV":17.2,"Radio":45.9,"Newspaper":69.3}]
const stringData = JSON.stringify(jsonData)
// make request when submit button is pressed
const makeRequest = async (data) => {
const res = await fetch(apiUrl, {
method: method,
mode: mode,
cache: cache,
credentials: credentials,
headers: headers,
body: JSON.stringify(data)
});
const response = await res.json();
return response;
};
export default function App(props) {
// get input field value
const id = useId();
const [input, setInput] = useState(props?.value ?? '');
// store api response
const [answer, setAnswer] = useState();
// handle submit button press
const submit = async () => {
const res = await makeRequest(JSON.parse(input) || jsonData);
setAnswer(parseFloat(res.prediction.replace("[", "").replace("]", "")));
console.log(JSON.parse(input))
};
return (
<>
<h1>Sales Predictions</h1>
<form>
<fieldset>
<label>
<h3>Expenditures for Adverts</h3>
<p>Please specify the advertisement budget for <strong>TV</strong>, <strong>Radio</strong> and <strong>Newspaper</strong> adverts:</p>
<label htmlFor={id}><strong>Input JSON Data:</strong> </label>
<input
id={id}
value={input}
placeholder=' [{"TV":17.2,"Radio":45.9,"Newspaper":69.3}]'
className="form-control"
type="json"
size="32"
onInput={e => setInput(e.target.value)}
/><br/>
<em>Example: <code>{stringData}</code></em>
</label>
</fieldset>
</form>
<div>
<button type='submit' onClick={submit}>Send</button>
<h5>Revenue Prediction:</h5>
<p>{JSON.stringify(answer)}</p>
</div>
</>
);
}

Adding the Frontend
Starting the backend separately from the frontend is a bit inconvenient. Instead we can pre-render the frontend and add it into the backend container. Run a Vite.js build to generate the static frontend with the following command:
npm run build
The static files will be generated in ./dist. Copy them into the index.html file into a folder named templates in your Flask app root and rename to sales.html. Static JS, CSS and image files need to go into the static folder:
.
├── app.py
├── Dockerfile
├── models
│ ├── production_model_column_names.pkl
│ └── production_model.pkl
├── requirements.txt
├── static
│ ├── assets
│ │ ├── index-bf239c1f.js
│ │ └── index-d526a0c5.css
│ └── favicon.ico
└── templates
└── sales.html
Unfortunately, we need to edit the links for those static files in sales.html by adding the /static/ prefix:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/static/favicon.ico" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Sales Prediction API</title>
<script type="module" crossorigin src="/static/assets/index-bf239c1f.js"></script>
<link rel="stylesheet" href="/static/assets/index-d526a0c5.css">
</head>
<body>
<div id="root"></div>
</body>
</html>
Now add the static route to app.py that will serve this page for us on /sales/:
from flask import Flask, request, jsonify, render_template
import joblib
import pandas as pd
model = joblib.load('models/production_model.pkl')
col_names = joblib.load('models/production_model_column_names.pkl')
app = Flask(__name__, static_folder='static')
# serve html frontend
@app.route('/sales/')
@app.route('/sales/<name>')
def sales(name=None):
return render_template('sales.html', name=name)
# wait for json post request and return prediction
@app.route('/api', methods=['POST'])
def predict():
req_data = request.json
df = pd.DataFrame(req_data).reindex(columns=col_names)
prediction = list(model.predict(df))
return jsonify({'prediction': str(prediction)})
# load the model and start web api
if __name__ == 'main':
app.run()
Rebuild the Docker image and restart the container. It should now serve the frontend on /sales/ connecting to the backend on /api/:
http://localhost:5000/sales/http://localhost:5000/api/