Hashicorp Nomad to run periodic backups

Preparation -> see Resistance is futile - Borg with Docker.
From Docker to Nomad
I want to use Nomad to execute the following Docker command for me periodically to create daily backups of selected files:
docker run \
--rm \
-e BORG_REPO=/opt/borg \
-e BORG_PASSPHRASE=mypassword \
-e BACKUP_DIRS=/data \
-e ARCHIVE=osticket-db-$(date +%Y-%m-%d) \
-e COMPRESSION=lz4 \
-e PRUNE=1 \
-e KEEP_DAILY=1 \
-e KEEP_WEEKLY=0 \
-e KEEP_MONTHLY=0 \
-v /opt/borg/config:/root \
-v /opt/borg/repo:/opt/borg \
-v /opt/temp1:/data/temp1:ro \
-v /opt/temp2:/data/temp2:ro \
--security-opt label:disable \
--name borg-backup \
pschiffe/borg
The server I deploy this container to must have the directory /opt/borg/config that contains the Borg configuration (this will be auto-generated on the first run and then recycled). And the dir /opt/borg/repo (this is most likely going to change to a mounted network storage later on) that will contain the password protected backup.
The BACKUP_DIRS variable is set to /data - this is the directory inside the Docker container that will be backed-up. Every directory that I want to be backed up from my host system needs to be mounted in that location - this can be several locations from all over the host system, e.g. -v /opt/temp1:/data/temp1:ro \. These directories will be mounted as read-only to make sure that the source data is not going to be altered in any way.
This backup is a backup on a backup - the server itself is constantly mirrored in itself. This service is only meant to provide a quick way to revert changes made to a database without having to role back the entire server. So I activated Pruning and I only want to keep 1 backup - but I am not sure yet if setting monthly and weekly to 0 actually works. This is just a test-run.
Preparing the Nomad Client
The Client is a server running OSTicket and MariaDB + a NGINX Ingress. Since all of them are provisioned using Nomad I already have the volume mount for the directory I want to backup - the MariaDB data dir. All I need to add now is the Borg configuration and repo path to my Nomad Client:
/etc/nomad.d/client.hcl
client {
enabled = true
servers = ["myserver:port"]
host_volume "letsencrypt" {
path = "/etc/letsencrypt"
read_only = false
}
host_volume "osticket_db" {
path = "/opt/osticket/db"
read_only = false
}
host_volume "borg_config" {
path = "/opt/borg/config"
read_only = false
}
host_volume "borg_repo" {
path = "/opt/borg/repo"
read_only = false
}
}
# Docker Configuration
plugin "docker" {
volumes {
enabled = true
selinuxlabel = "z"
}
allow_privileged = false
allow_caps = ["chown", "net_raw"]
}
Periodic Runs
I am going to use the periodic stanza to run the Nomad job at fixed times, dates, or intervals. The easiest way to think about the periodic scheduler is "Nomad cron" or "distributed cron":
job "docs" {
periodic {
cron = "*/15 * * * * *"
time_zone = "Europe/Berlin"
prohibit_overlap = true
enabled = true
}
}
To get started I will just use cron = "@daily" to execute the job once a day. But we first have to specify the Scheduler. Nomad has four scheduler types that can be used when creating your job: service, batch, system and sysbatch:
Error during plan: Unexpected response code: 500 (1 error occurred:
- Periodic can only be used with "batch" or "sysbatch" scheduler)
Batch
Batch jobs are much less sensitive to short term performance fluctuations and are short lived, finishing in a few minutes to a few days. Although the batch scheduler is very similar to the service scheduler, it makes certain optimizations for the batch workload.
Batch jobs are intended to run until they exit successfully. Batch tasks that exit with an error are handled according to the job's restart and reschedule stanzas.
System Batch
The sysbatch scheduler is used to register jobs that should be run to completion on all clients that meet the job's constraints. The sysbatch scheduler will schedule jobs similarly to the system scheduler, but like a batch job once a task exits successfully it is not restarted on that client.
This scheduler type is useful for issuing "one off" commands to be run on every node in the cluster. Sysbatch jobs can also be created as periodic and parameterized jobs. Since these tasks are managed by Nomad, they can take advantage of job updating, service discovery, monitoring, and more.
The sysbatch scheduler will preempt lower priority tasks running on a node if there is not enough capacity to place the job. See preemption details on how tasks that get preempted are chosen.
Sysbatch jobs are intended to run until successful completion, explicitly stopped by an operator, or evicted through preemption. Sysbatch tasks that exit with an error are handled according to the job's restart stanza.
So since I will only be running the service on one node and I do not want to the service to be re-scheduled in case that it fails:
job "osticket_backup" {
periodic {
cron = "@daily"
}
type = "batch"
reschedule {
attempts = 0
unlimited = false
}
Complete Nomad Job File
job "osticket_backup" {
type = "batch"
periodic {
cron = "@daily"
}
reschedule {
attempts = 0
unlimited = false
}
datacenters = ["MyDatacenter"]
group "osticket-backup" {
volume "osticket_db" {
type = "host"
read_only = false
source = "osticket_db"
}
volume "borg_config" {
type = "host"
read_only = false
source = "borg_config"
}
volume "borg_repo" {
type = "host"
read_only = false
source = "borg_repo"
}
task "osticket-backup-db" {
driver = "docker"
user = "root"
config {
image = "pschiffe/borg"
force_pull = false
}
volume_mount {
volume = "osticket_db"
destination = "/data" #<-- in the container
read_only = false
}
volume_mount {
volume = "borg_config"
destination = "/root" #<-- in the container
read_only = false
}
volume_mount {
volume = "borg_repo"
destination = "/opt/borg" #<-- in the container
read_only = false
}
env {
BORG_REPO="/opt/borg"
BORG_PASSPHRASE="mypassword"
BACKUP_DIRS="/data"
ARCHIVE="${NOMAD_SHORT_ALLOC_ID}"
COMPRESSION="lz4"
PRUNE=1
KEEP_DAILY=7
KEEP_WEEKLY=1
KEEP_MONTHLY=1
}
}
}
}
Pruning: Keep 7 end of the day, 1 end of the week and 1 end of the month backup.
Running the Job
nomad plan osticket_backup.tf
+ Job: "osticket_backup"
+ Task Group: "osticket_backup" (1 create)
+ Task: "osticket_backup-db" (forces create)
Scheduler dry-run:
- All tasks successfully allocated.
- If submitted now, next periodic launch would be at 2022-11-13T00:00:00Z (12h29m2s from now).
Job Modify Index: 0
nomad job run -check-index 0 osticket_backup.tf
Job registration successful
Approximate next launch time: 2022-11-13T00:00:00Z (12h27m45s from now)
So the job was registered and is supposed to run at midnight.
ERROR:
Exit Code: 2, Exit Message: "Docker container exited with non-zero exit code: 2"
The Job only ever executed successful once. After deleting the repo content it worked again. The reason for it is already corrected in the job file above. I used osticket-db-$(date +%Y-%m-%d) as the repo name. The timestamp variable in there was not being used - so the archive name remained identical with each run and the back-up process exited unsuccessful:
Archive already exists
terminating with error status, rc 2
I since replaced the variable with ${NOMAD_SHORT_ALLOC_ID} and the job is now working as expected:
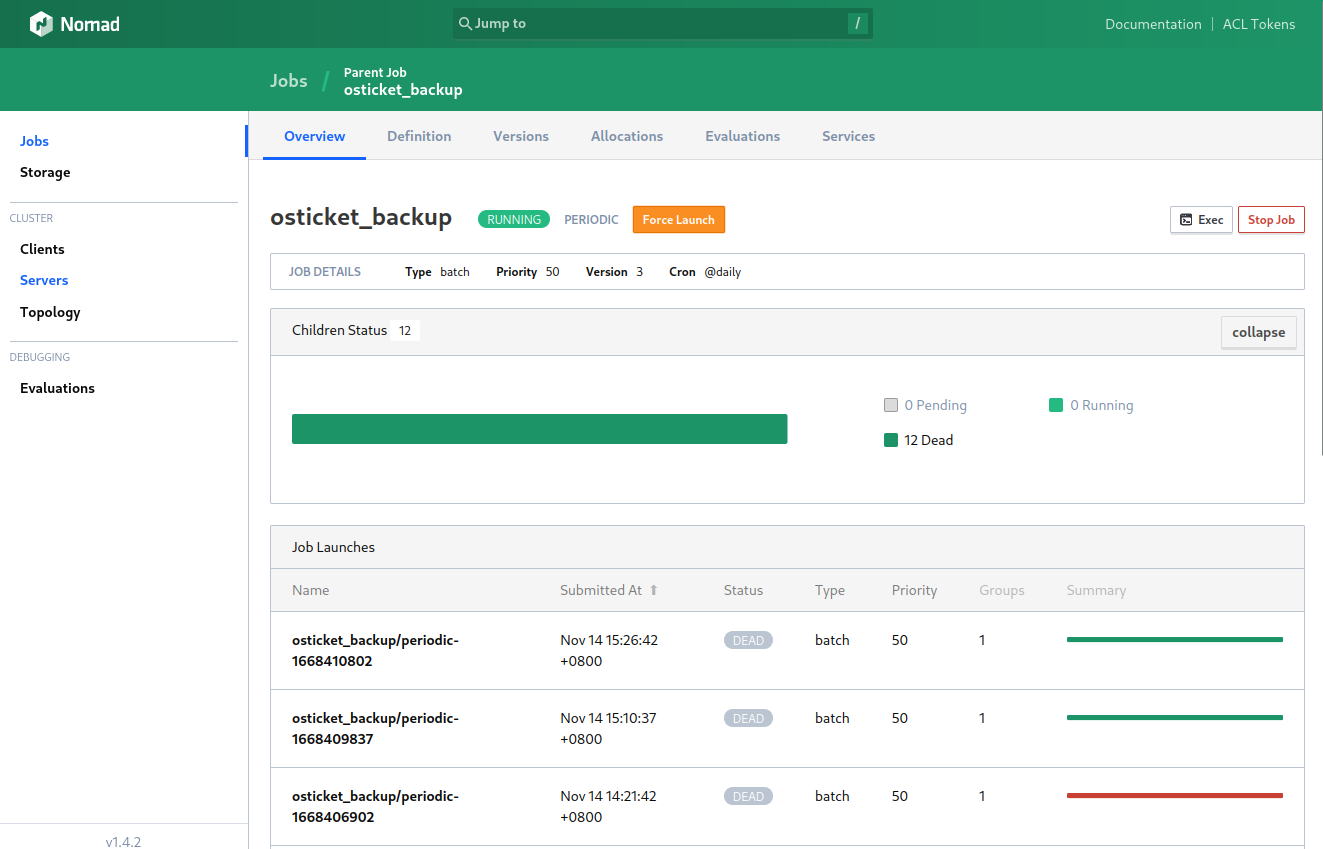
Restore a Backup
A restore can be run manually and then copied to the data directory restoring the old database. To find the correct backup we have to find the short allocation ID for the backup job run:
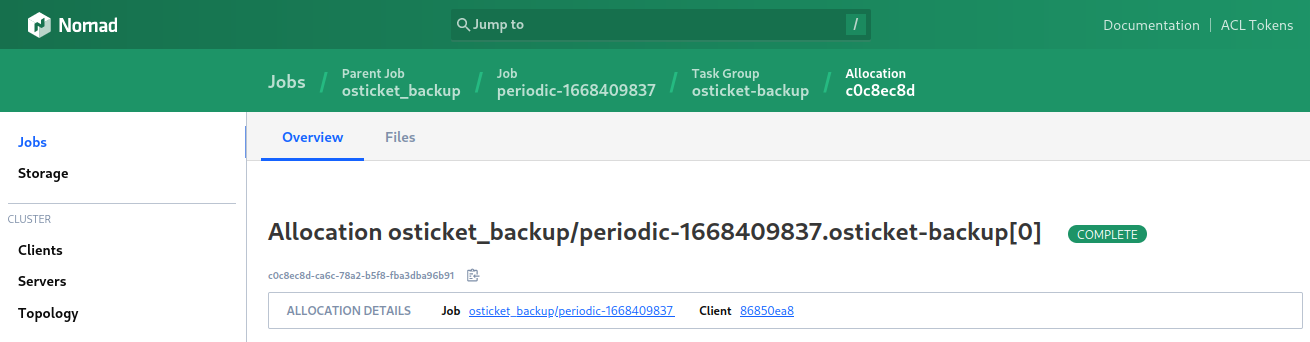
In the case above it is c0c8ec8d. We have to use the ARCHIVE=c0c8ec8d environment variable accordingly to retrieve our data:
docker run \
--rm \
-e BORG_REPO=/opt/borg \
-e ARCHIVE=c0c8ec8d \
-e BORG_PASSPHRASE=mypassword \
-e EXTRACT_TO=/borg/output \
-v /opt/borg/config:/root \
-v /opt/borg/repo:/opt/borg \
-v /opt/borg/output:/borg/output/data \
--security-opt label:disable \
--name borg-backup \
pschiffe/borg
...
terminating with success status, rc 0