spaCy NER Predictions

- Part I - Tesseract OCR on Arch Linux
- Part II - spaCy NER on Arch Linux
- Part III - spaCy NER Predictions
I now want to use my model to extract the name, email address, web address and designation from an unknown name card:

Setup
Re-enter the virtual environment and create a new Python notebook in Jupyter:
source .env/bin/activate
jupyter notebook
Import Libraries
import numpy as np
import pandas as pd
import cv2 as cv
import pytesseract
from glob import glob
import spacy
import re
import string
Text Cleanup
I can re-use the clean text function created in the Data Preprocessing step:
def cleanText(txt):
whitespace = string.whitespace
punctuation = '!#$%&\'()*+:;<=>?[\\]^`{|}~'
tableWhitespace = str.maketrans('','',whitespace)
tablePunctuation = str.maketrans('','',punctuation)
text = str(txt)
text = text.lower()
removeWhitespace = text.translate(tableWhitespace)
removePunctuation = removeWhitespace.translate(tablePunctuation)
return str(removePunctuation)
Load NER Model
All I need to do here is to import the best-model with spaCy from the output folder:
model_ner = spacy.load('./output/model-best/')
Process your Data
Load Image
Use OpenCV2 to load the image (and verify that the images was loaded):
image = cv.imread('../images/card_00.jpg')
# cv.imshow('businesscard', image)
# cv.waitKey(0)
# cv.destroyAllWindows()
Extract Data
Now grab the text from the image using Pytesseract:
tessData = pytesseract.image_to_data(image)
Run tessData to verify that the data was sucessfully extracted:
tessData
...
Mike\n5\t1\t1\t1\t1\t2\t645\t29\t225\t34\t69\tPolinowski\n2\t1\t2\t0\t0\t0\t628\t78\t247\t37\t-1\t\n3\t1\t2\t1\t0\t0\t628\t78\t247\t37\t-1\t\n4\t1\t2\t1\t1\t0\t628\t78\t244\t19\t-1\t\n5\t1\t2\t1\t1\t1\t628\t78\t62\t19\t91\tChief\n5\t1\t2\t1\t1\t2\t701\t78\t171\t19\t90\tProcrastinator\n
...
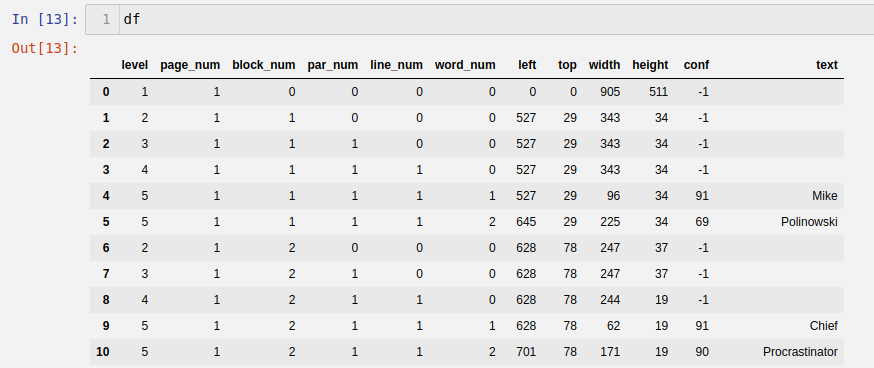
Convert this data into a Pandas Dataframe:
tessList = list(map(lambda x:x.split('\t'),tessData.split('\n')))
df = pd.DataFrame(tessList[1:],columns=tessList[0])
Run df to verify that the data was wrapped inside the data frame:
Clean the data frame:
df.dropna(inplace=True) #Drop missing values
df['text'] = df['text'].apply(cleanText) #Apply cleanText function on text column
Data Preprocessing
df_clean = df.query('text !="" ') #Ignore whitespace
content = " ".join([w for w in df_clean['text']]) #Join every word in text column concatenated by spaces
Verify by printing content:
print(content)
mike polinowski chief procrastinator i 39c, street 318, boeung keng kong phnom penh, cambodia tel 855 0 23 21 59 60 email me@example.com www.some-place.com
Get Predictions from NER Model
Now I can use the NER model to get my named entities out of that string:
doc = model_ner(content)
spaCy offers a tool that allows us to display the recognized named entities:
from spacy import displacy
displacy.serve(doc,style='ent')
The display is served on localhost port 5000.
Use
displacy.render(doc,style='ent')instead if you are using a Jupyter notebook.

All entities were sucessfully recognized - except the job designation. Procrastination does not seem to have much of a future ...
Bringing Results into a Dataframe
To work with the data I will now write it into an JSON object:
dockJSON = doc.to_json()
This way I can now get hold of the data by keys - text (all recognized strings), ents (the tags used to those words) and tokens (character positions within the string):
dockJSON.keys()
This will retrieve the available keys - dict_keys(['text', 'ents', 'tokens']) which can be queried by:
dockJSON['text']
dockJSON['ents']
dockJSON['tokens']
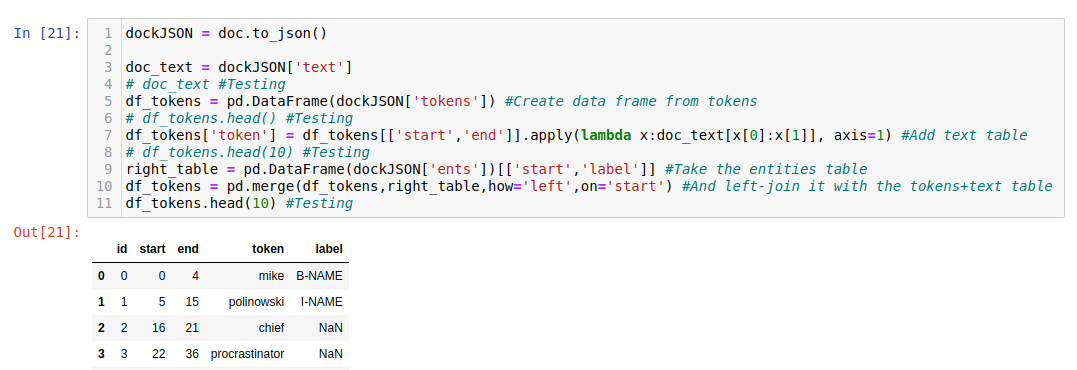
Let's wrap everything into a Pandas Data Frame:
dockJSON = doc.to_json()
doc_text = dockJSON['text']
# doc_text #Testing
df_tokens = pd.DataFrame(dockJSON['tokens']) #Create data frame from tokens
# df_tokens.head() #Testing
df_tokens['token'] = df_tokens[['start','end']].apply(lambda x:doc_text[x[0]:x[1]], axis=1) #Add text table
# df_tokens.head(10) #Testing
right_table = pd.DataFrame(dockJSON['ents'])[['start','label']] #Take the entities table
df_tokens = pd.merge(df_tokens,right_table,how='left',on='start') #And left-join it with the tokens+text table
# df_tokens.head(10) #Testing
Replace all NaN fields in the lable column with O's:
df_tokens.fillna('O',inplace=True)
Drawing Bounding Boxes
End and Start Position
To highlight detected entities we need the position of each entity as reported by Pytesseract:

For this we can join df_tokens table with the df_clean table using a common key.
- Get the End Position of every word inside the
textcolumn indf_clean['text']:
lambda x: len(x)+1.cumsum()-1 #End position is length of each string +1 space. The cummulative sum adds the length of each prior string to get the absolut endposition inside `text`
Cumulative sum example:
- Input: 10, 15, 20, 25, 30
- Output: 10, 25, 45, 70, 100
df_clean['end'] = df_clean['text'].apply(lambda x: len(x) + 1).cumsum() -1
- The Start Position of each word is the end position minus the length of the word:
df_clean['start'] = df_clean[['text','end']].apply(lambda x: x[1] - len(x[0]),axis=1)
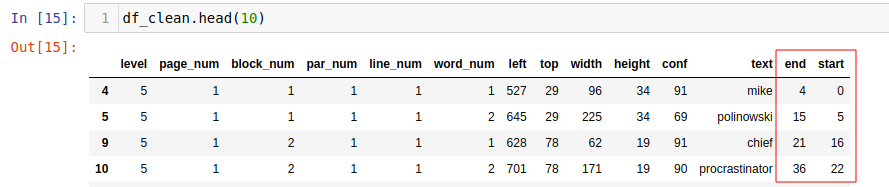
Table Join
Now that we have a common key in both tables df_clean and df_tokens we can use that one - the Start Position - to perform an inner join:
df_card = pd.merge(df_clean,df_tokens[['start','token','label']],how='inner',on='start')
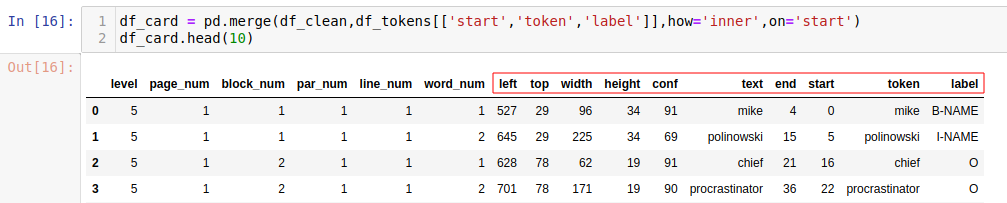
The table contains all the information that we need to draw our bounding box. I can extract them for every entity that is not labled with O:
bb_df = df_card.query("label ! = 'O'")
From this I can now:
img = image.copy() #first take a copy of the original image
for x,y,w,h,label in bb_df[['left','top','width','height','label']].values: #write data into an array
x = int(x)
y = int(y)
w = int(w)
h = int(h)
cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2) #Draw rectangle around entities
cv.putText(img,str(label),(x,y),cv.FONT_HERSHEY_PLAIN,1,(255,0,0),2) #Add a tag from value of label
cv.imshow('Prediction', img)
cv.waitKey(0)
cv.destroyAllWindows()

The bounding boxes are still split into several parts that need to be combined. I labeled them with B- and I- prefixes - e.g. B-NAME for the beginning of the name entity and I-NAME for all following entities that are part of it. We can remove those prefixes with:
bb_df['label'] = bb_df['label'].apply(lambda x: x[2:])

And now I can group all entities that are assigned the same label:
class groupgen():
def __init__(self):
self.id = 0
self.text = ''
def getgroup(self,text):
if self.text == text: #If entity has the same label - group them under the same id
return self.id
else:
self.id +=1 #Else increment
self.text = text
return self.id
grp_gen = groupgen()
Add the group ID to the bounding box data frame:
bb_df['group'] = bb_df['label'].apply(grp_gen.getgroup)
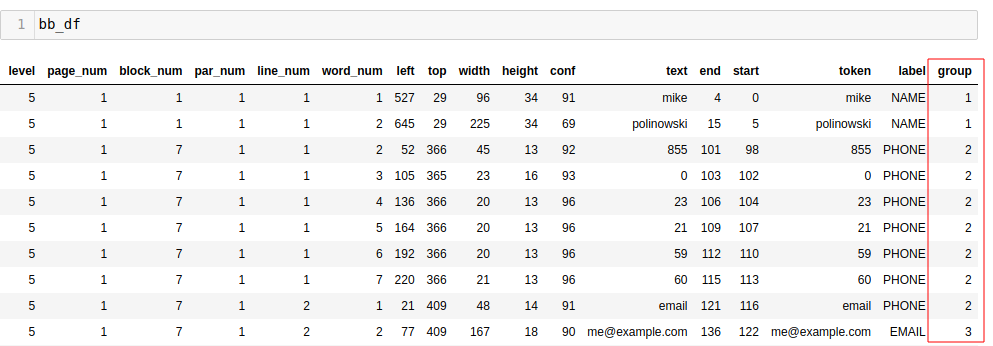
Calculate the missing parameter of the right and bottom edge:
bb_df[['top','left','width','height']] = bb_df[['top','left','width','height']].astype(int)
bb_df['right'] = bb_df['left'] + bb_df['width'] #Calculate right edge
bb_df['bottom'] = bb_df['top'] + bb_df['height'] #Calculate bottom edge
Aggregate all entities of a group and find the position of the enclosing bounding box:
- Left - Minimum value of
leftcolumn - Right - Maximum value of
rightcolumn - Top - Minimum value of
topcolumn - Bottom - Maximum value of
bottomcolumn
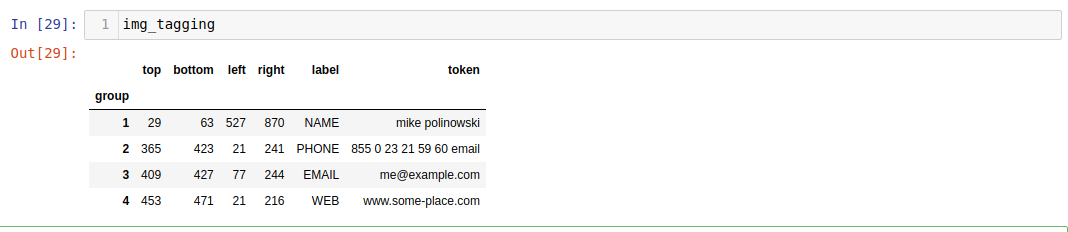
col_group = ['top','bottom','left','right','label','token','group']
group_tag_img = bb_df[col_group].groupby(by='group')
img_tagging = group_tag_img.agg({
'top':min,
'bottom':max,
'left':min,
'right':max,
'label':np.unique,
'token':lambda x: " ".join(x) #Join all words together seperated by a space
})