See also:
- Fun, fun, tensors: Tensor Constants, Variables and Attributes, Tensor Indexing, Expanding and Manipulations, Matrix multiplications, Squeeze, One-hot and Numpy
- Tensorflow 2 - Neural Network Regression: Building a Regression Model, Model Evaluation, Model Optimization, Working with a "Real" Dataset, Feature Scaling
- Tensorflow 2 - Neural Network Classification: Non-linear Data and Activation Functions, Model Evaluation and Performance Improvement, Multiclass Classification Problems
- Tensorflow 2 - Convolutional Neural Networks: Binary Image Classification, Multiclass Image Classification
- Tensorflow 2 - Transfer Learning: Feature Extraction, Fine-Tuning, Scaling
- Tensorflow 2 - Unsupervised Learning: Autoencoder Feature Detection, Autoencoder Super-Resolution, Generative Adverserial Networks
Tensorflow Neural Network Regression
Preprocessing Data
Normalization & Standardization
Change the values of features to a common scale without distorting differences in their ranges.
X["age"].plot(kind="hist")

X["bmi"].plot(kind="hist")
X["children"].value_counts()
# 0 574
# 1 324
# 2 240
# 3 157
# 4 25
# 5 18
# Name: children, dtype: int64
Feature Scaling with SciKit
To bring all values on the same scale we can use SciKit-Learn:
- Normalization:
MinMaxScalerconverts all values to a range between1and0while preserving the original distribution. - Standardization:
StandardScalerremoves the mean and divides each value by the standard deviation (reduces effect from outliers)
# get insurance dataset
insurance_data = pd.read_csv('https://raw.githubusercontent.com/mpolinowski/Machine-Learning-with-R-datasets/master/insurance.csv')
insurance_data_random = insurance_data.sample(frac=1)
# create a column transformer
transformer = make_column_transformer(
(MinMaxScaler(), ["age", "bmi", "children"]), # Normalize
(OneHotEncoder(handle_unknown="ignore"), ["sex", "smoker", "region"]) # OneHotEncode
)
# create features and labels
# we need to predict "charges" - so drop this column from features
X = insurance_data_random.drop("charges", axis=1)
y = insurance_data_random["charges"]
# training and testing data split using scikit-learn
# this function actually randomizes the dataset for us
# we did not need to shuffle the dataframe before - doesn't hurt, though
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=42)
# fit transformer to training data
transformer.fit(X_train)
# normalize training and test data with transformer
X_train_norm = transformer.transform(X_train)
X_test_norm = transformer.transform(X_test)
X_train.loc[88], X_train_norm[88]
# (age 46
# sex female
# bmi 27.74
# children 0
# smoker no
# region northwest
# Name: 88, dtype: object,
# array([0.65217391, 0.52905569, 0.8 , 0. , 1. ,
# 1. , 0. , 1. , 0. , 0. ,
# 0. ]))
Model Training
tf.random.set_seed(42)
# increase number of units
insurance_model_norm = tf.keras.Sequential([
layers.Dense(8, input_shape=[11], name="input_layer"),
layers.Dense(16, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="insurance_model_norm")
insurance_model_norm.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
earlystop_callback = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0.00001,
patience=100, restore_best_weights=True)
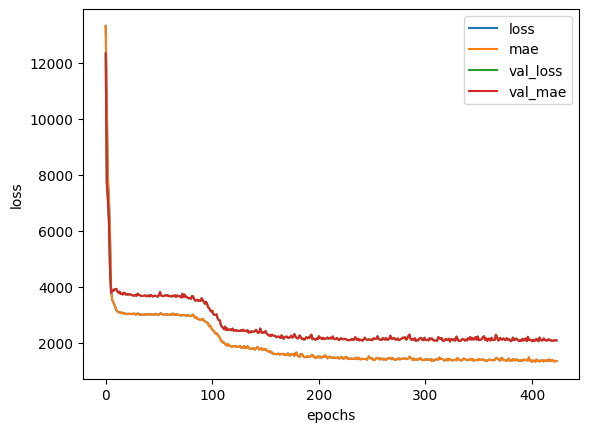
history_norm = insurance_model_norm.fit(X_train_norm, y_train,
validation_data=(X_test_norm, y_test),
epochs=5000, callbacks=[earlystop_callback])
# Epoch 950/5000
# 34/34 [==============================] - 0s 4ms/step - loss: 1292.6730 - mae: 1292.6730 - val_loss: 2108.5374 - val_mae: 2108.5374
# history plot
pd.DataFrame(history_norm.history).plot()
plt.ylabel("loss")
plt.xlabel("epochs")
tf.random.set_seed(42)
# increase number of units
insurance_model_norm_1 = tf.keras.Sequential([
layers.Dense(11, name="input_layer"),
layers.Dense(32, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="insurance_model_norm_1")
insurance_model_norm_1.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.02),
metrics="mae")
earlystop_callback = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0.00001,
patience=100, restore_best_weights=True)
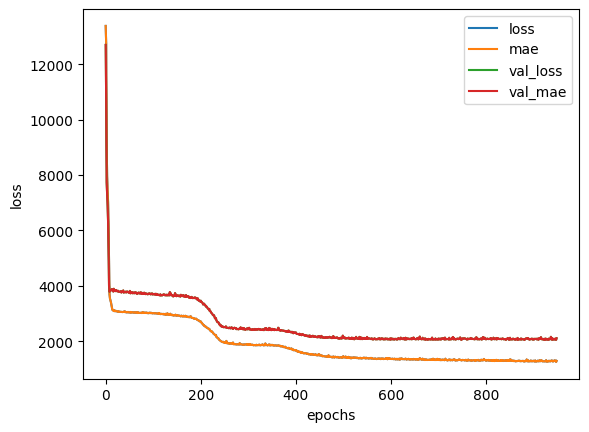
history_norm_1 = insurance_model_norm_1.fit(X_train_norm, y_train,
validation_data=(X_test_norm, y_test),
epochs=5000, callbacks=[earlystop_callback])
# Epoch 424/5000
# 34/34 [==============================] - 0s 4ms/step - loss: 1358.7324 - mae: 1358.7324 - val_loss: 2093.2083 - val_mae: 2093.2083
# history plot
pd.DataFrame(history_norm_1.history).plot()
plt.ylabel("loss")
plt.xlabel("epochs")