
See also:
- Fun, fun, tensors: Tensor Constants, Variables and Attributes, Tensor Indexing, Expanding and Manipulations, Matrix multiplications, Squeeze, One-hot and Numpy
- Tensorflow 2 - Neural Network Regression: Building a Regression Model, Model Evaluation, Model Optimization, Working with a "Real" Dataset, Feature Scaling
- Tensorflow 2 - Neural Network Classification: Non-linear Data and Activation Functions, Model Evaluation and Performance Improvement, Multiclass Classification Problems
- Tensorflow 2 - Convolutional Neural Networks: Binary Image Classification, Multiclass Image Classification
- Tensorflow 2 - Transfer Learning: Feature Extraction, Fine-Tuning, Scaling
- Tensorflow 2 - Unsupervised Learning: Autoencoder Feature Detection, Autoencoder Super-Resolution, Generative Adverserial Networks
Tensorflow Neural Network Regression
Medical Cost Dataset
The Medical Cost Dataset investigates if you can accurately predict insurance costs based on:
- age: age of primary beneficiary
- sex: insurance contractor gender, female, male
- bmi: Body mass index, providing an understanding of body, weights that are relatively high or low relative to height, objective index of body weight (
kg / m ^ 2) using the ratio of height to weight, ideally18.5to24.9 - children: Number of children covered by health insurance / Number of dependents
- smoker: Smoking
- region: the beneficiary's residential area in the US, northeast, southeast, southwest, northwest.
- charges: Individual medical costs billed by health insurance
# get insurance dataset
insurance_data = pd.read_csv('https://raw.githubusercontent.com/mpolinowski/Machine-Learning-with-R-datasets/master/insurance.csv')
insurance_data
# shuffle dataframe to prevent bias
insurance_data_random = insurance_data.sample(frac=1)
insurance_data_random
# creating numerical labels for strings
# convert categorical variables into indicator variables with pandas get_dummies
insurance_one_hot = pd.get_dummies(insurance_data_random)
insurance_one_hot.head()

# create features and labels
# we need to predict "charges" - so drop this column from features
X = insurance_one_hot.drop("charges", axis=1)
y = insurance_one_hot["charges"]
# training and testing data split using scikit-learn
# this function actually randomizes the dataset for us
# we did not need to shuffle the dataframe before - doesn't hurt, though
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=42)
X_train
# 80% => 1070 rows × 11 columns
Model Building
tf.random.set_seed(42)
# building the model (based on the "best model" above)
insurance_model = tf.keras.Sequential([
layers.Dense(10, input_shape=[11], name="input_layer"),
layers.Dense(16, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="insurance_model")
insurance_model.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.001),
metrics="mae")
# model training
insurance_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# Epoch 500/500
# 34/34 [==============================] - 0s 3ms/step - loss: 2702.7041 - mae: 2702.7041 - val_loss: 2433.1829 - val_mae: 2433.1829
# we have an average absolute validation error of val_mae: `2433.1829`
y_train.median(), y_train.mean()
# (9373.744050000001, 13240.898205242056)
# the arithmetic average is of medical charges is `13240.898` => 18.4% off
Improving the Model
# since the model was still improving I will extend the training
insurance_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5000)
# I am still seeing improvements after 5000 epochs
# Epoch 5000/5000
# 34/34 [==============================] - 0s 3ms/step - loss: 1498.0355 - mae: 1498.0355 - val_loss: 1543.5344 - val_mae: 1543.5344
# the error is now down to 11% from 18% before
# since before removing complexity actually improved the model
# removing one dense layer
insurance_model_1 = tf.keras.Sequential([
layers.Dense(10, input_shape=[11], name="input_layer"),
layers.Dense(8, activation="relu", name="dense_layer"),
layers.Dense(1, name="output_layer")
], name="insurance_model_1")
insurance_model_1.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.001),
metrics="mae")
insurance_model_1.summary()
# Model: "insurance_model_1"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_layer (Dense) (None, 10) 120
# dense_layer (Dense) (None, 8) 88
# output_layer (Dense) (None, 1) 9
# =================================================================
# Total params: 217
# Trainable params: 217
# Non-trainable params: 0
# _________________________________________________________________
insurance_model_1.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# this decreased the performance with the error after 500 cycles
# Epoch 500/500
# 34/34 [==============================] - 0s 3ms/step - loss: 3530.7039 - mae: 3530.7039 - val_loss: 3634.2502 - val_mae: 3634.2502
# mae `2433.1829` => mae `3634.2502`
tf.random.set_seed(42)
# back to the initial model but with a larger learning rate
insurance_model_2 = tf.keras.Sequential([
layers.Dense(8, input_shape=[11], name="input_layer"),
layers.Dense(16, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="insurance_model_2")
insurance_model_2.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
insurance_model_2.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# Epoch 500/500
# 34/34 [==============================] - 0s 3ms/step - loss: 2059.1406 - mae: 2059.1406 - val_loss: 2059.2986 - val_mae: 2059.2986
# mae `2433.1829` => mae `2059.2986`
tf.random.set_seed(42)
# increase number of units
insurance_model_3 = tf.keras.Sequential([
layers.Dense(8, input_shape=[11], name="input_layer"),
layers.Dense(32, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="insurance_model_3")
insurance_model_3.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
history = insurance_model_3.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# Epoch 500/500
# 34/34 [==============================] - 0s 3ms/step - loss: 2110.4812 - mae: 2110.4812 - val_loss: 1937.2085 - val_mae: 1937.2085
# even better
# mae `2433.1829` => mae `1937.2085`
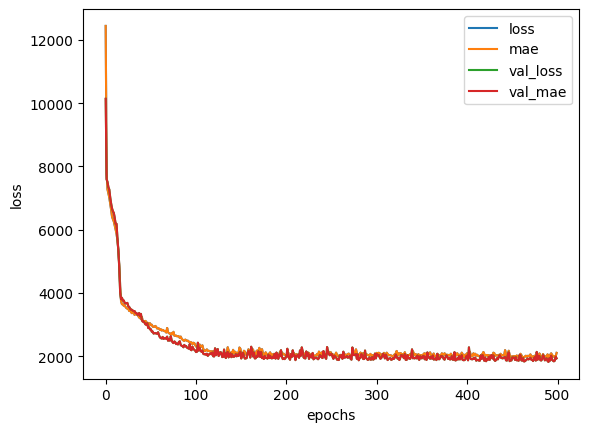
# history plot
pd.DataFrame(history.history).plot()
plt.ylabel("loss")
plt.xlabel("epochs")
# the improvements keep creeping in slowly.
When to stop training?
# a way to keep training until a minimum of
# improvement is reached you can use the
# `EarlyStopping()` callback
# stop when loss stops improving min 0.0001
# over 10 cycles
earlystop_callback = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0.0001,
patience=10, restore_best_weights=True)
history = insurance_model_3.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=5000, callbacks=[earlystop_callback])
# since the model is already trained it won't run for long now before the callback is triggered:
# Epoch 21/5000
# 34/34 [==============================] - 0s 3ms/step - loss: 1843.7740 - mae: 1843.7740 - val_loss: 1802.4473 - val_mae: 1802.4473