Using Tensorflow Models in OpenCV
Scikit-Learn ML Model Explainability
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allocation with local explanations using the classic Shapley values from game theory and their related extensions.
import boto3
from datetime import date
import lightgbm as lgb
import math
import matplotlib.pyplot as plt
import numpy as pd
import pandas as pd
import seaborn as sns
import shap
from sklearn import metrics
from sklearn.model_selection import StratifiedShuffleSplit, GridSearchCV, train_test_split
Using tqdm.autonotebook.tqdm in notebook mode. Use tqdm.tqdm instead to force console mode (e.g. in jupyter console)
Dataset
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv')
df = pd.concat([df_train, df_test])
df.shape
(21287, 14)
df.head().transpose()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| enrollee_id | 8949 | 29725 | 11561 | 33241 | 666 |
| city | city_103 | city_40 | city_21 | city_115 | city_162 |
| city_development_index | 0.92 | 0.776 | 0.624 | 0.789 | 0.767 |
| gender | Male | Male | NaN | NaN | Male |
| relevent_experience | Has relevent experience | No relevent experience | No relevent experience | No relevent experience | Has relevent experience |
| enrolled_university | no_enrollment | no_enrollment | Full time course | NaN | no_enrollment |
| education_level | Graduate | Graduate | Graduate | Graduate | Masters |
| major_discipline | STEM | STEM | STEM | Business Degree | STEM |
| experience | >20 | 15 | 5 | <1 | >20 |
| company_size | NaN | 50-99 | NaN | NaN | 50-99 |
| company_type | NaN | Pvt Ltd | NaN | Pvt Ltd | Funded Startup |
| last_new_job | 1 | >4 | never | never | 4 |
| training_hours | 36 | 47 | 83 | 52 | 8 |
| target | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
Preprocessing
# can ID be used as unique identifier?
df['enrollee_id'].nunique() == df.shape[0]
# there are as many IDs as there are rows in the dataset
True
df['duplicated'] = df.drop(columns=['enrollee_id']).duplicated()
df['duplicated'].value_counts()
# there are 50 ids that are dups
False 21237 True 50 Name: duplicated, dtype: int64
# drop all lines that are duplicated entries
df.drop(df[df['duplicated'] == True].index, inplace = True)
df['duplicated'].value_counts()
False 21235 Name: duplicated, dtype: int64
for col in df.columns:
print(f' \n {col.upper()} :: {df[col].nunique()} UNIQUE :: {df[col].isnull().sum()} NULL')
ENROLLEE_ID :: 21235 UNIQUE :: 0 NULL
CITY :: 123 UNIQUE :: 0 NULL
CITY_DEVELOPMENT_INDEX :: 93 UNIQUE :: 0 NULL
GENDER :: 3 UNIQUE :: 5015 NULL
RELEVENT_EXPERIENCE :: 2 UNIQUE :: 0 NULL
ENROLLED_UNIVERSITY :: 3 UNIQUE :: 417 NULL
EDUCATION_LEVEL :: 5 UNIQUE :: 512 NULL
MAJOR_DISCIPLINE :: 6 UNIQUE :: 3121 NULL
EXPERIENCE :: 22 UNIQUE :: 70 NULL
COMPANY_SIZE :: 8 UNIQUE :: 6541 NULL
COMPANY_TYPE :: 6 UNIQUE :: 6755 NULL
LAST_NEW_JOB :: 6 UNIQUE :: 463 NULL
TRAINING_HOURS :: 241 UNIQUE :: 0 NULL
TARGET :: 2 UNIQUE :: 2127 NULL
DUPLICATED :: 1 UNIQUE :: 0 NULL
# remove all entires that don't have the target value
df.dropna(subset=['target'], how='all', inplace=True)
df['target'].value_counts()
# we need a model that can handle imbalanced datasets -> gradient boosted decision trees (lightgbm)
0.0 14343 1.0 4765 Name: target, dtype: int64
df['company_size'].value_counts()
50-99 3080 100-500 2560 10000+ 2009 10/49 1470 1000-4999 1322 <10 1308 500-999 877 5000-9999 562 Name: company_size, dtype: int64
df['company_size'] = df['company_size'].apply(lambda x: '10-49' if x == '10/49' else x)
df['company_size'].value_counts()
50-99 3080 100-500 2560 10000+ 2009 10-49 1470 1000-4999 1322 <10 1308 500-999 877 5000-9999 562 Name: company_size, dtype: int64
df['training_hours'].hist()
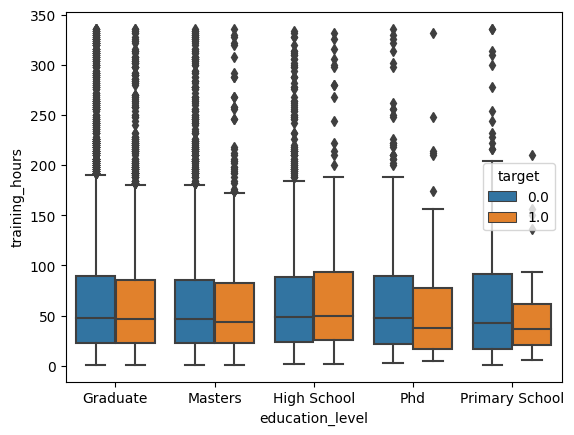
sns.boxplot(data=df, x='education_level', y='training_hours', hue='target')
# drop columns that will not have an influence on the target variable
df_train = df.drop(['duplicated', 'enrollee_id'], axis=1)
# make target variable int
df_train['target'] = pd.to_numeric(df_train['target'])
df_train['target'] = df_train['target'].astype(int)
Data Transformation
# encode categorical columns
categorical_columns = []
for col in df_train.columns:
print('\n')
print(f'INFO :: Column {col} is of type {df_train[col].dtype} .')
if df_train[col].dtype == 'object':
print('PROCESSING :: Added for dummy variable creation.')
categorical_columns.append(col)
df_train = pd.get_dummies(df_train, columns=categorical_columns)
INFO :: Column city is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column city_development_index is of type float64 .
INFO :: Column gender is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column relevent_experience is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column enrolled_university is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column education_level is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column major_discipline is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column experience is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column company_size is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column company_type is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column last_new_job is of type object . PROCESSING :: Added for dummy variable creation.
INFO :: Column training_hours is of type int64 .
INFO :: Column target is of type int64 .
# correlation to target
def gen_correlation_df(dataframe, target):
correlations = {
'variable': [],
'corr': []
}
for col in list(dataframe.columns):
if dataframe[col].dtype not in ['object', '<M8[ns]'] and col != target:
r = dataframe[target].corr(dataframe[col])
correlations['variable'].append(col)
correlations['corr'].append(r)
return pd.DataFrame(correlations).sort_values(by=['corr'], ascending = False)
df_cor = gen_correlation_df(df_train, 'target')
df_cor
| variable | corr | |
|---|---|---|
| 66 | city_city_21 | 0.319434 |
| 130 | enrolled_university_Full time course | 0.149529 |
| 129 | relevent_experience_No relevent experience | 0.127994 |
| 13 | city_city_11 | 0.091457 |
| 133 | education_level_Graduate | 0.087214 |
| 164 | experience_<1 | 0.079047 |
| 144 | experience_1 | 0.069583 |
| 157 | experience_3 | 0.066304 |
| 26 | city_city_128 | 0.050778 |
| 143 | major_discipline_STEM | 0.050013 |
| 158 | experience_4 | 0.049482 |
| 5 | city_city_101 | 0.047004 |
| 155 | experience_2 | 0.046997 |
| 104 | city_city_74 | 0.046142 |
| 185 | last_new_job_never | 0.045534 |
| 41 | city_city_145 | 0.044923 |
| 46 | city_city_155 | 0.033568 |
| 180 | last_new_job_1 | 0.029297 |
| 75 | city_city_33 | 0.027429 |
| 81 | city_city_42 | 0.026713 |
| 24 | city_city_126 | 0.025354 |
| 159 | experience_5 | 0.025253 |
| 108 | city_city_78 | 0.024855 |
| 161 | experience_7 | 0.024617 |
| 63 | city_city_19 | 0.023563 |
| 34 | city_city_139 | 0.020590 |
| 100 | city_city_70 | 0.020259 |
| 160 | experience_6 | 0.019471 |
| 82 | city_city_43 | 0.019350 |
| 86 | city_city_48 | 0.017434 |
| 16 | city_city_115 | 0.017167 |
| 11 | city_city_107 | 0.017094 |
| 118 | city_city_90 | 0.015416 |
| 39 | city_city_143 | 0.015099 |
| 60 | city_city_179 | 0.013111 |
| 56 | city_city_171 | 0.012551 |
| 119 | city_city_91 | 0.011924 |
| 121 | city_city_94 | 0.011539 |
| 125 | gender_Female | 0.008742 |
| 69 | city_city_25 | 0.008382 |
| 52 | city_city_162 | 0.007534 |
| 19 | city_city_118 | 0.007300 |
| 48 | city_city_158 | 0.006651 |
| 38 | city_city_142 | 0.006401 |
| 142 | major_discipline_Other | 0.006048 |
| 83 | city_city_44 | 0.005959 |
| 109 | city_city_79 | 0.005943 |
| 42 | city_city_146 | 0.005943 |
| 88 | city_city_53 | 0.004976 |
| 85 | city_city_46 | 0.004568 |
| 12 | city_city_109 | 0.004213 |
| 10 | city_city_106 | 0.004213 |
| 29 | city_city_131 | 0.004213 |
| 103 | city_city_73 | 0.004204 |
| 139 | major_discipline_Business Degree | 0.004155 |
| 106 | city_city_76 | 0.003626 |
| 18 | city_city_117 | 0.003517 |
| 59 | city_city_176 | 0.003467 |
| 115 | city_city_84 | 0.003467 |
| 31 | city_city_134 | 0.003260 |
| 127 | gender_Other | 0.002882 |
| 92 | city_city_59 | 0.002678 |
| 55 | city_city_167 | 0.002678 |
| 23 | city_city_123 | 0.002450 |
| 22 | city_city_121 | 0.002432 |
| 40 | city_city_144 | 0.002387 |
| 90 | city_city_55 | 0.002275 |
| 117 | city_city_9 | 0.002016 |
| 131 | enrolled_university_Part time course | 0.001623 |
| 62 | city_city_180 | 0.001608 |
| 35 | city_city_14 | 0.000056 |
| 61 | city_city_18 | 0.000021 |
| 74 | city_city_31 | 0.000021 |
| 54 | city_city_166 | 0.000021 |
| 44 | city_city_150 | -0.000435 |
| 141 | major_discipline_No Major | -0.000687 |
| 116 | city_city_89 | -0.001449 |
| 177 | company_type_Other | -0.001790 |
| 89 | city_city_54 | -0.002196 |
| 58 | city_city_175 | -0.002196 |
| 43 | city_city_149 | -0.002384 |
| 30 | city_city_133 | -0.002611 |
| 25 | city_city_127 | -0.002611 |
| 162 | experience_8 | -0.003014 |
| 68 | city_city_24 | -0.003108 |
| 70 | city_city_26 | -0.003364 |
| 21 | city_city_120 | -0.003388 |
| 4 | city_city_100 | -0.003633 |
| 45 | city_city_152 | -0.004028 |
| 36 | city_city_140 | -0.004170 |
| 53 | city_city_165 | -0.004531 |
| 112 | city_city_81 | -0.004713 |
| 120 | city_city_93 | -0.004869 |
| 156 | experience_20 | -0.005391 |
| 99 | city_city_7 | -0.005581 |
| 20 | city_city_12 | -0.005761 |
| 174 | company_type_Early Stage Startup | -0.005792 |
| 71 | city_city_27 | -0.006643 |
| 77 | city_city_37 | -0.006666 |
| 14 | city_city_111 | -0.007223 |
| 27 | city_city_129 | -0.007223 |
| 80 | city_city_41 | -0.007451 |
| 111 | city_city_80 | -0.007518 |
| 181 | last_new_job_2 | -0.007570 |
| 51 | city_city_160 | -0.007645 |
| 73 | city_city_30 | -0.008166 |
| 110 | city_city_8 | -0.008340 |
| 113 | city_city_82 | -0.008340 |
| 37 | city_city_141 | -0.008801 |
| 47 | city_city_157 | -0.008868 |
| 98 | city_city_69 | -0.009085 |
| 94 | city_city_62 | -0.009325 |
| 146 | experience_11 | -0.009632 |
| 166 | company_size_10-49 | -0.010248 |
| 138 | major_discipline_Arts | -0.010679 |
| 64 | city_city_2 | -0.011034 |
| 102 | city_city_72 | -0.011176 |
| 2 | city_city_1 | -0.011431 |
| 65 | city_city_20 | -0.013150 |
| 78 | city_city_39 | -0.013833 |
| 182 | last_new_job_3 | -0.013902 |
| 79 | city_city_40 | -0.014132 |
| 28 | city_city_13 | -0.014426 |
| 124 | city_city_99 | -0.014593 |
| 17 | city_city_116 | -0.014710 |
| 183 | last_new_job_4 | -0.015328 |
| 178 | company_type_Public Sector | -0.015365 |
| 49 | city_city_159 | -0.015976 |
| 140 | major_discipline_Humanities | -0.016998 |
| 163 | experience_9 | -0.017082 |
| 114 | city_city_83 | -0.017769 |
| 148 | experience_13 | -0.019034 |
| 84 | city_city_45 | -0.019214 |
| 95 | city_city_64 | -0.019522 |
| 9 | city_city_105 | -0.020172 |
| 107 | city_city_77 | -0.020649 |
| 91 | city_city_57 | -0.020956 |
| 145 | experience_10 | -0.021133 |
| 1 | training_hour "line": 1590, s | -0.021179 |
| 154 | experience_19 | -0.022050 |
| 123 | city_city_98 | -0.022057 |
| 3 | city_city_10 | -0.022491 |
| 6 | city_city_102 | -0.023017 |
| 147 | experience_12 | -0.023773 |
| 176 | company_type_NGO | -0.024453 |
| 96 | city_city_65 | -0.024939 |
| 57 | city_city_173 | -0.025485 |
| 152 | experience_17 | -0.025806 |
| 153 | experience_18 | -0.027003 |
| 172 | company_size_5000-9999 | -0.027311 |
| 149 | experience_14 | -0.027454 |
| 101 | city_city_71 | -0.028219 |
| 87 | city_city_50 | -0.028243 |
| 122 | city_city_97 | -0.029486 |
| 33 | city_city_138 | -0.030509 |
| 137 | education_level_Primary School | -0.034393 |
| 76 | city_city_36 | -0.035708 |
| 93 | city_city_61 | -0.036076 |
| 67 | city_city_23 | -0.036596 |
| 150 | experience_15 | -0.036696 |
| 136 | education_level_Phd | -0.037587 |
| 171 | company_size_500-999 | -0.038555 |
| 72 | city_city_28 | -0.039877 |
| 151 | experience_16 | -0.040968 |
| 97 | city_city_67 | -0.041123 |
| 134 | education_level_High School | -0.042942 |
| 105 | city_city_75 | -0.043489 |
| 135 | education_level_Masters | -0.043751 |
| 7 | city_city_103 | -0.044411 |
| 8 | city_city_104 | -0.045717 |
| 169 | company_size_10000+ | -0.046135 |
| 173 | company_size_<10 | -0.048945 |
| 175 | company_type_Funded Startup | -0.059407 |
| 32 | city_city_136 | -0.059726 |
| 168 | company_size_1000-4999 | -0.061808 |
| 184 | last_new_job_>4 | -0.069695 |
| 170 | company_size_50-99 | -0.073381 |
| 126 | gender_Male | -0.074494 |
| 167 | company_size_100-500 | -0.080041 |
| 50 | city_city_16 | -0.090270 |
| 15 | city_city_114 | -0.094945 |
| 165 | experience_>20 | -0.100802 |
| 128 | relevent_experience_Has relevent experience | -0.127994 |
| 132 | enrolled_university_no_enrollment | -0.140493 |
| 179 | company_type_Pvt Ltd | -0.161860 |
| 0 | city_development_index | -0.341331 |
Model Training
# train-test split
train, test = train_test_split(df_train, test_size=0.2)
# remove target label from training dataset
X_cols = list(set(train.columns) - set(['target']))
def split_xy(train_in, test_in, X_cols, target):
train = train_in.copy()
test = test_in.copy()
X_train = train[X_cols].copy()
X_test = test[X_cols].copy()
y_train = train[target]
y_test = test[target]
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = split_xy(test, train, X_cols, 'target')
# verify 80/20 train-test split
print(X_test.shape[0] / (X_train.shape[0] + X_test.shape[0]) * 100)
79.99790663596399
Grid Search
# create shuffled splits
cv_split = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=77)
# create search params
param_grid = {
'learning_rate': [0.05],
'n_estimators': [400],
'max_depth': [5, 7],
'min_child_samples': [50, 200, 600],
'num_leaves': [31, 63]
}
def fit_lgb(param_grid, X, y, cv):
gbm = lgb.LGBMClassifier(
objective='binary',
feature_fraction=0.9
)
grid_search = GridSearchCV(
gbm,
param_grid=param_grid,
scoring='roc_auc',
cv=cv,
verbose=1,
n_jobs=-1
)
grid_search.fit(X=X, y=y.values.ravel())
print(grid_search.best_score_)
print(grid_search.best_estimator_)
print(grid_search.best_params_)
return grid_search
grid_search = fit_lgb(param_grid, X_train, y_train, cv_split)
# 0.8067351303514142
# LGBMClassifier(feature_fraction=0.9, learning_rate=0.05, max_depth=5,
# min_child_samples=50, n_estimators=400, objective='binary')
# {'learning_rate': 0.05, 'max_depth': 5, 'min_child_samples': 50, 'n_estimators': 400, 'num_leaves': 31}
Model Evaluation
# pass test data to trained model
y_pred = grid_search.best_estimator_.predict_proba(X_test)[:,1]
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] Accuracy may be bad since you didn't explicitly set num_leaves OR 2^max_depth > num_leaves. (num_leaves=31).
auc = metrics.roc_auc_score(y_true=y_test, y_score=y_pred)
auc
0.7834230893204323
feature_importance = pd.Series(grid_search.best_estimator_.feature_importances_, index=X_cols).sort_values(ascending=False)
feature_importance
training_hours 1530 city_development_index 651 last_new_job_1 208 company_type_Pvt Ltd 205 education_level_Graduate 126 company_size_50-99 112 relevent_experience_No relevent experience 109 city_city_103 102 enrolled_university_no_enrollment 85 major_discipline_STEM 80 experience_3 79 last_new_job_never 77 city_city_21 73 company_type_Funded Startup 68 gender_Male 66 company_type_Public Sector 64 company_size_1000-4999 62 company_size_<10 58 experience_>20 56 company_size_100-500 56 gender_Female 56 enrolled_university_Full time course 54 company_type_Early Stage Startup 54 education_level_Masters 53 experience_4 52 last_new_job_2 51 experience_<1 49 last_new_job_4 47 company_size_10000+ 45 company_type_NGO 44 relevent_experience_Has relevent experience 42 company_size_500-999 40 experience_2 39 experience_8 30 enrolled_university_Part time course 30 city_city_100 29 experience_9 27 company_size_5000-9999 25 experience_17 25 company_size_10-49 24 city_city_16 23 experience_11 23 major_discipline_Humanities 23 city_city_160 23 major_discipline_No Major 22 experience_14 22 major_discipline_Business Degree 21 city_city_67 20 experience_10 19 city_city_136 19 last_new_job_>4 18 major_discipline_Other 18 education_level_High School 17 last_new_job_3 17 experience_13 16 experience_16 16 experience_12 14 city_city_114 13 education_level_Primary School 13 experience_15 10 experience_6 10 city_city_102 9 experience_7 9 experience_5 6 city_city_104 6 experience_19 3 city_city_11 3 experience_1 3 city_city_142 0 city_city_74 0 city_city_141 0 city_city_144 0 city_city_9 0 city_city_138 0 city_city_175 0 city_city_26 0 city_city_109 0 city_city_70 0 city_city_77 0 city_city_94 0 city_city_149 0 city_city_2 0 city_city_75 0 city_city_64 0 city_city_159 0 education_level_Phd 0 city_city_18 0 city_city_166 0 city_city_81 0 city_city_45 0 city_city_13 0 city_city_55 0 city_city_146 0 city_city_37 0 city_city_28 0 city_city_123 0 city_city_116 0 city_city_76 0 city_city_72 0 major_discipline_Arts 0 city_city_57 0 city_city_73 0 city_city_12 0 city_city_33 0 city_city_59 0 city_city_126 0 city_city_25 0 city_city_7 0 city_city_118 0 city_city_107 0 city_city_139 0 city_city_176 0 city_city_179 0 city_city_39 0 experience_18 0 city_city_143 0 city_city_127 0 city_city_69 0 city_city_105 0 city_city_80 0 city_city_71 0 city_city_117 0 city_city_140 0 city_city_50 0 city_city_131 0 city_city_150 0 city_city_171 0 city_city_93 0 city_city_120 0 city_city_24 0 city_city_53 0 city_city_41 0 city_city_91 0 city_city_1 0 city_city_152 0 experience_20 0 city_city_54 0 city_city_133 0 city_city_145 0 city_city_173 0 city_city_82 0 city_city_106 0 city_city_78 0 city_city_98 0 city_city_27 0 city_city_157 0 city_city_180 0 city_city_79 0 city_city_99 0 city_city_8 0 city_city_40 0 city_city_31 0 city_city_19 0 city_city_46 0 city_city_42 0 city_city_128 0 city_city_20 0 city_city_97 0 city_city_36 0 city_city_101 0 city_city_44 0 city_city_134 0 city_city_10 0 gender_Other 0 city_city_115 0 company_type_Other 0 city_city_158 0 city_city_162 0 city_city_129 0 city_city_61 0 city_city_30 0 city_city_84 0 city_city_90 0 city_city_83 0 city_city_165 0 city_city_48 0 city_city_65 0 city_city_23 0 city_city_43 0 city_city_155 0 city_city_111 0 city_city_121 0 city_city_14 0 city_city_62 0 city_city_167 0 city_city_89 0 dtype: int32
plt.figure(figsize=(48, 5))
plt.plot(feature_importance)
plt.xticks(rotation=45)
plt.savefig('assets/Feature_Importance.png', bbox_inches='tight')

Model Explainability
# fit the explainer
explainer = shap.Explainer(grid_search.best_estimator_.predict, X_test)
# calculate shap values
shap_values = explainer(X_test)
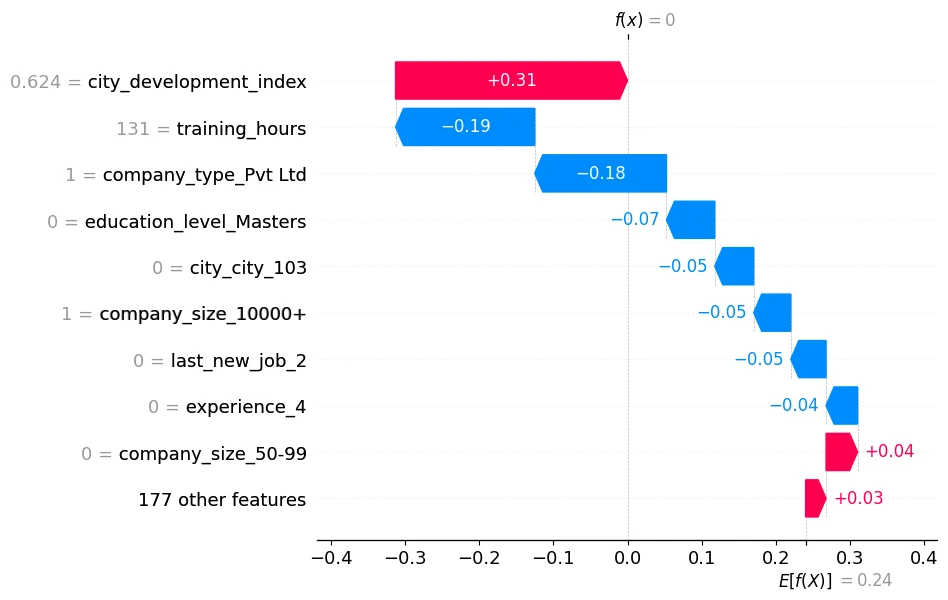
The above explanation shows features each contributing to push the model output from the base value (the average model output over the training dataset we passed) to the model output. Features pushing the prediction higher are shown in red, those pushing the prediction lower are in blue.
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
The mean absolute value of the SHAP values for each feature:
# show mean absolute effect
shap.plots.bar(shap_values)
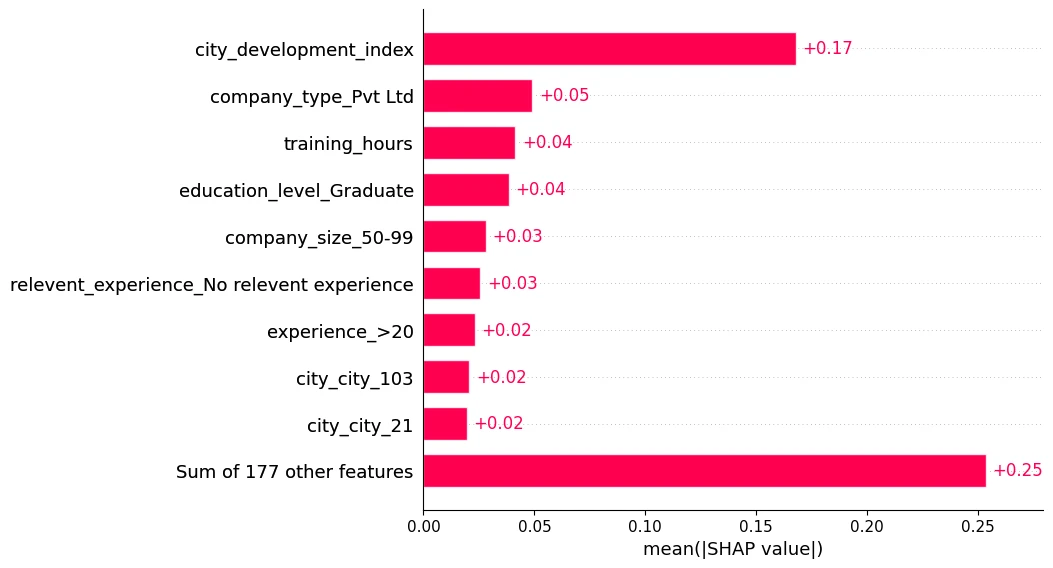
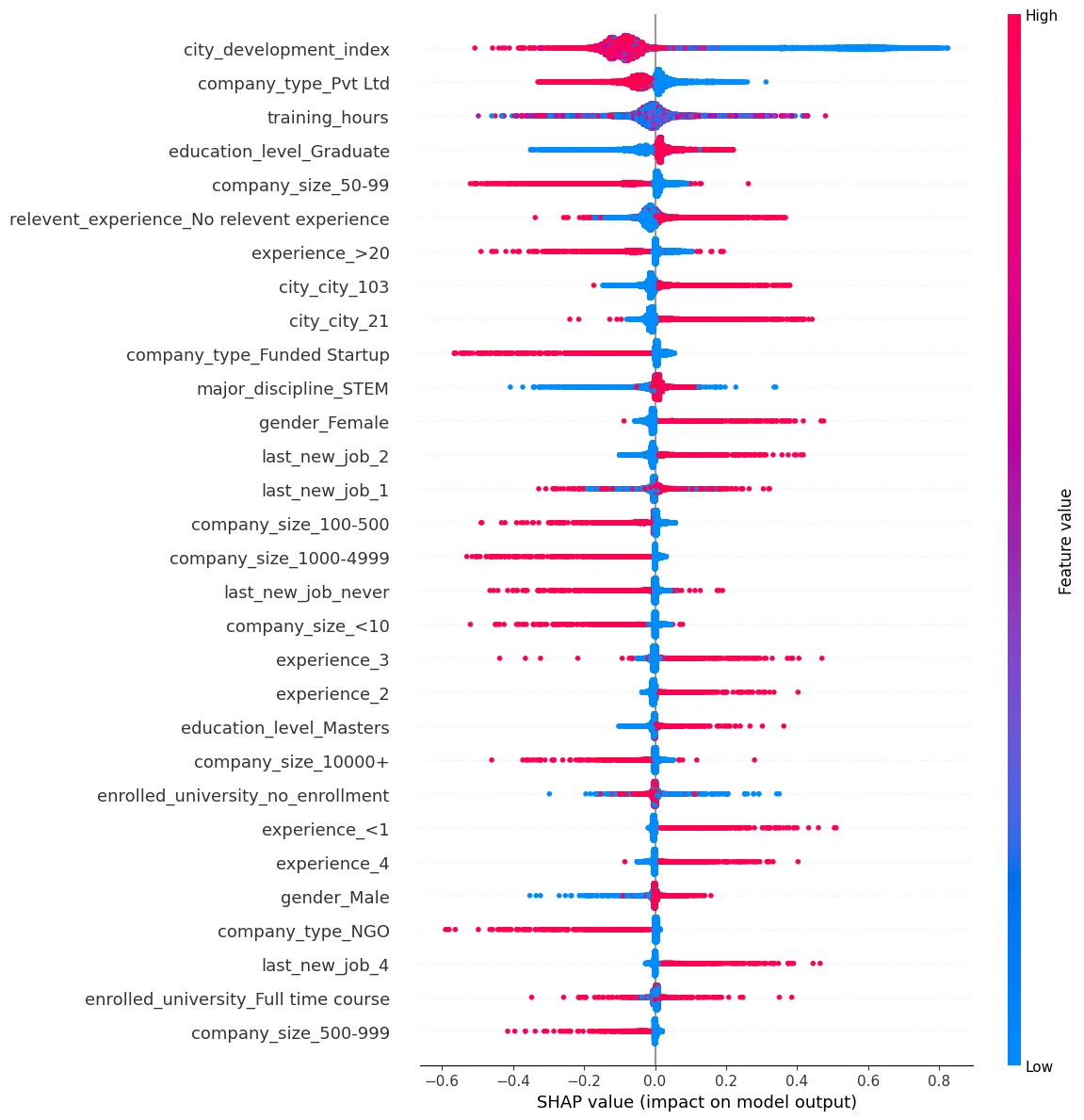
To get an overview of which features are most important for a model we can plot the SHAP values of every feature for every sample. The plot below sorts features by the sum of SHAP value magnitudes over all samples, and uses SHAP values to show the distribution of the impacts each feature has on the model output. The color represents the feature value (red high, blue low). This reveals for example that a high city_development_index lowers the predicted target - chance that an employee is searching for a new job.
shap.summary_plot(shap_values, plot_size=(12,12), max_display=30)