Tensorflow Image Classification

Datasets
CIFAR-10
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class. You can download the Keras dataset by:
from tensorflow.keras import datasets
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
Keras models and datasets will be saved to
/home/myuser/.kerason Linux.
# print sample images from dataset
plt.figure(figsize=(10,10))
# pick 25 images
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# choose images from training set
plt.imshow(train_images[i], cmap=plt.cm.binary)
# use train class name as labels
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Building the Model
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32,32, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.summary()
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
Training the Model
# compile the model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# saving checkpoints when there are improvements
MCName = os.path.sep.join(["./checkpoints", "weights-{epoch:03d}-{val_loss:.4f}.hdf5"])
checkpoint = ModelCheckpoint(MCName, monitor="val_loss", mode="min", save_best_only=True, verbose=1)
callbacks = [checkpoint]
# fit the model
history = model.fit(train_images,
train_labels,
epochs=25,
callbacks=callbacks,
validation_data=(test_images, test_labels))
Evaluating the Model
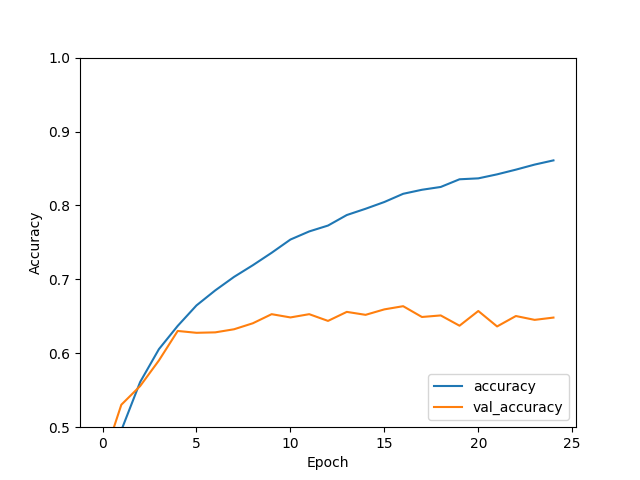
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 1.6254 - accuracy: 0.6483 - 507ms/epoch - 2ms/step
Run Predictions
We can now use the test dataset to verify our training:
# load cifar10
# to use images from the test dataset for prediction
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
print(type(x_test))
print(type(y_test[0]))
# cifar10 category label name
cifar10_labels = np.array([
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'])
Use Keras to load the latest training checkpoint:
# load latest checkpoint
model = load_model('checkpoints/weights-008-1.0783.hdf5')
Tensorflow does not like the shape the images are in:
ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 32, 32, 3), found shape=(1, 32, 3)
We need to take care of that by providing the following function:
# prepare test image
def convertCIFER10Data(image):
img = image.astype('float32')
c = np.zeros(32*32*3).reshape((1,32,32,3))
c[0] = img
return c
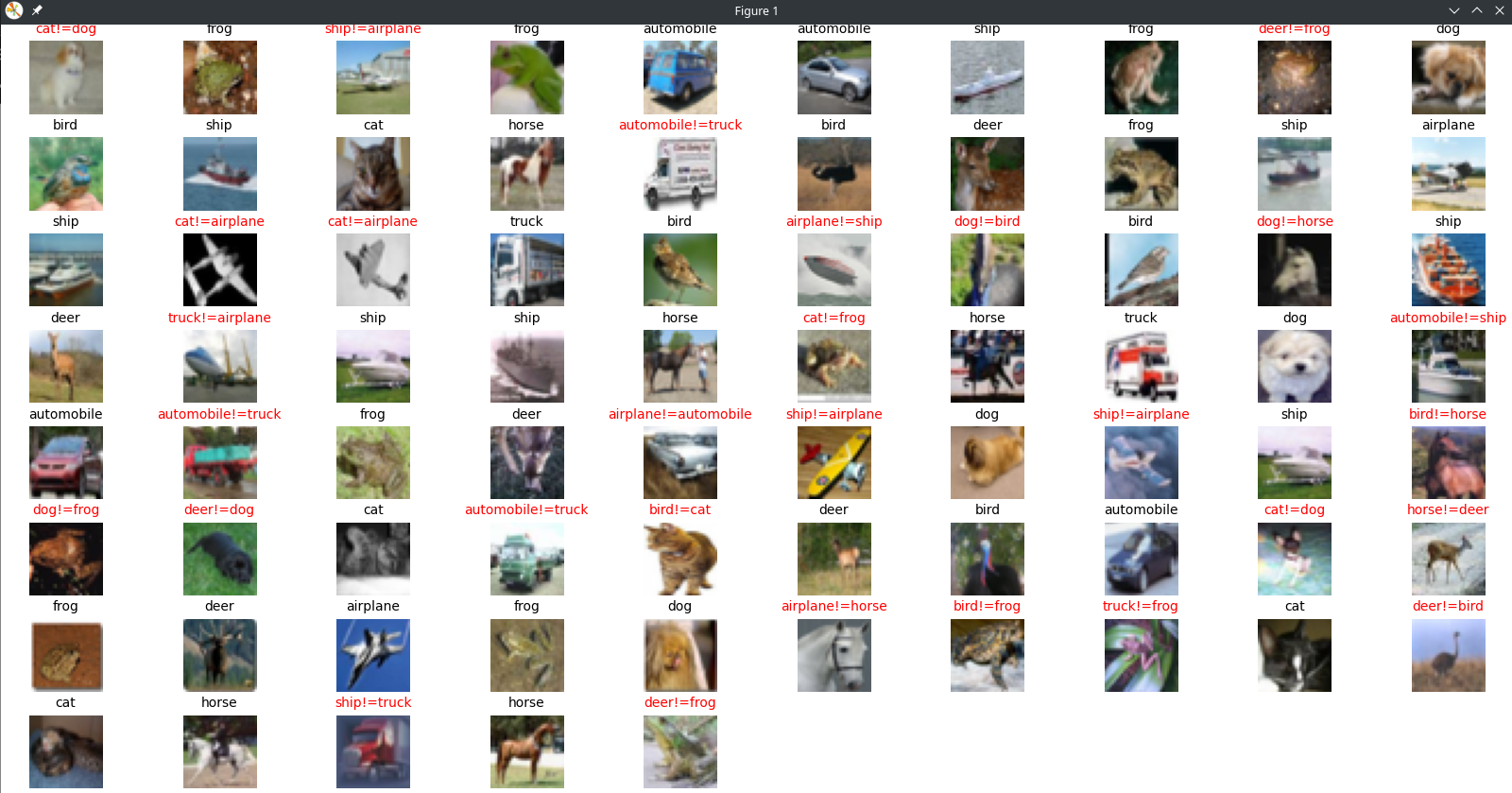
Now we can run a prediction loop over a batch of test images:
# run prediction
for i in range(75):
# Random test image
index = random.randint(0, x_test.shape[0])
image = x_test[index]
data = convertCIFER10Data(image)
plt.subplot(10, 10, i+1)
plt.tight_layout()
plt.imshow(image)
plt.axis('off')
ret = model.predict(data, batch_size=1)
bestnum = 0.0
bestclass = 0
for n in [0,1,2,3,4,5,6,7,8,9]:
if bestnum < ret[0][n]:
bestnum = ret[0][n]
bestclass = n
if y_test[index] == bestclass:
plt.title(cifar10_labels[bestclass], fontsize=10)
right += 1
else:
plt.title(cifar10_labels[bestclass] + "!=" + cifar10_labels[y_test[index][0]], color='#ff0000', fontsize=10)
mistake += 1
plt.show()
print("Correct predictions:", right)
print("False predictions:", mistake)
print("Rate:", right/(mistake + right)*100, '%')
On average I am seeing correct detection rates of around 60% which is not so bad for a training run of 25 epochs:
Correct predictions: 46
False predictions: 29
Rate: 61.33333333333333 %