
See also:
- Fun, fun, tensors: Tensor Constants, Variables and Attributes, Tensor Indexing, Expanding and Manipulations, Matrix multiplications, Squeeze, One-hot and Numpy
- Tensorflow 2 - Neural Network Regression: Building a Regression Model, Model Evaluation, Model Optimization, Working with a "Real" Dataset, Feature Scaling
- Tensorflow 2 - Neural Network Classification: Non-linear Data and Activation Functions, Model Evaluation and Performance Improvement, Multiclass Classification Problems
- Tensorflow 2 - Convolutional Neural Networks: Binary Image Classification, Multiclass Image Classification
- Tensorflow 2 - Transfer Learning: Feature Extraction, Fine-Tuning, Scaling
- Tensorflow 2 - Unsupervised Learning: Autoencoder Feature Detection, Autoencoder Super-Resolution, Generative Adverserial Networks
Tensorflow Transfer Learning
Model Scaling
- Pretraining EfficientNetB0 (10% of Dataset with 10 Classes)
- Fine-Tuning (100% of Dataset with 10 Classes)
- Scaling the Model to all 101 Classes (10% of Dataset with 101 Classes)
import datetime
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import random
from sklearn.metrics import accuracy_score, classification_report
import tensorflow as tf
from tensorflow.keras.utils import image_dataset_from_directory
# export helper functions from above into helper script
from helper import (create_tensorboard_callback,
create_checkpoint_callback,
plot_accuracy_curves,
combine_training_curves,
data_augmentation_layer_no_rescaling,
plot_confusion_matrix)
# global variables
SEED = 42
BATCH_SIZE = 32
IMG_SHAPE = (224, 224)
Get Data
# preparing datasets
# wget https://storage.googleapis.com/ztm_tf_course/food_vision/101_food_classes_10_percent.zip
training_directory = "../datasets/101_food_classes_10_percent/train"
testing_directory = "../datasets/101_food_classes_10_percent/test"
training_data_101_10 = image_dataset_from_directory(training_directory,
labels='inferred',
label_mode='categorical',
seed=SEED,
shuffle=True,
image_size=IMG_SHAPE,
batch_size=BATCH_SIZE)
testing_data_101_10 = image_dataset_from_directory(testing_directory,
labels='inferred',
label_mode='categorical',
seed=SEED,
shuffle=False,
image_size=IMG_SHAPE,
batch_size=BATCH_SIZE)
# get class names
class_names_101_10 = training_data_101_10.class_names
len(class_names_101_10), class_names_101_10
# Found 7575 files belonging to 101 classes.
# Found 25250 files belonging to 101 classes.
# (101,
# ['apple_pie',
# 'baby_back_ribs',
# 'baklava',
# 'beef_carpaccio',
# 'beef_tartare',
# 'beet_salad',
# 'beignets',
# 'bibimbap',
# 'bread_pudding',
# 'breakfast_burrito',
# 'bruschetta',
# 'caesar_salad',
# 'cannoli',
# 'caprese_salad',
# 'carrot_cake',
# 'ceviche',
# 'cheese_plate',
# 'cheesecake',
# 'chicken_curry',
# 'chicken_quesadilla',
# 'chicken_wings',
# 'chocolate_cake',
# 'chocolate_mousse',
# 'churros',
# 'clam_chowder',
# 'club_sandwich',
# 'crab_cakes',
# 'creme_brulee',
# 'croque_madame',
# 'cup_cakes',
# 'deviled_eggs',
# 'donuts',
# 'dumplings',
# 'edamame',
# 'eggs_benedict',
# 'escargots',
# 'falafel',
# 'filet_mignon',
# 'fish_and_chips',
# 'foie_gras',
# 'french_fries',
# 'french_onion_soup',
# 'french_toast',
# 'fried_calamari',
# 'fried_rice',
# 'frozen_yogurt',
# 'garlic_bread',
# 'gnocchi',
# 'greek_salad',
# 'grilled_cheese_sandwich',
# 'grilled_salmon',
# 'guacamole',
# 'gyoza',
# 'hamburger',
# 'hot_and_sour_soup',
# 'hot_dog',
# 'huevos_rancheros',
# 'hummus',
# 'ice_cream',
# 'lasagna',
# 'lobster_bisque',
# 'lobster_roll_sandwich',
# 'macaroni_and_cheese',
# 'macarons',
# 'miso_soup',
# 'mussels',
# 'nachos',
# 'omelette',
# 'onion_rings',
# 'oysters',
# 'pad_thai',
# 'paella',
# 'pancakes',
# 'panna_cotta',
# 'peking_duck',
# 'pho',
# 'pizza',
# 'pork_chop',
# 'poutine',
# 'prime_rib',
# 'pulled_pork_sandwich',
# 'ramen',
# 'ravioli',
# 'red_velvet_cake',
# 'risotto',
# 'samosa',
# 'sashimi',
# 'scallops',
# 'seaweed_salad',
# 'shrimp_and_grits',
# 'spaghetti_bolognese',
# 'spaghetti_carbonara',
# 'spring_rolls',
# 'steak',
# 'strawberry_shortcake',
# 'sushi',
# 'tacos',
# 'takoyaki',
# 'tiramisu',
# 'tuna_tartare',
# 'waffles'])
Model Building and Training
# create callbacks from helper.py
## checkpoint callback
checkpoint_callback = create_checkpoint_callback(
dir_name='../checkpoints/transfer_learning_scaling',
experiment_name='101_classes_10_percent_dataset')
## tensorboard callback
tensorboard_callback = create_tensorboard_callback(
dir_name='../tensorboard/transfer_learning_scaling',
experiment_name='101_classes_10_percent_dataset')
# get base model from keras applications
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=False
)
base_model.trainable = False
# build model using keras functional API
input_layer = tf.keras.layers.Input(shape=IMG_SHAPE+(3,), name='input_layer')
# use image augmentation layer from helper.py
data = data_augmentation_layer_no_rescaling(input_layer)
# run in inference mode so batchnorm statistics don't get updated
# even after unfreezing the base model for fine-tuning
data = base_model(data, training=False)
data = tf.keras.layers.GlobalAveragePooling2D(name="global_average_pooling_layer")(data)
output_layer = tf.keras.layers.Dense(len(class_names_101_10), activation="softmax", name="output_layer")(data)
model = tf.keras.Model(input_layer, output_layer)
# compile the model
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
# fit the model
tf.random.set_seed(SEED)
## training epochs before fine-tuning
pretraining_epochs = 5
history_model = model.fit(
training_data_101_10,
epochs=pretraining_epochs,
steps_per_epoch=len(training_data_101_10),
validation_data=testing_data_101_10,
# evaluate performance on 15% of the testing dataset
validation_steps=int(0.15 * len(testing_data_101_10)),
callbacks=[tensorboard_callback,
checkpoint_callback])
# Epoch 5/5
# 73s 307ms/step - loss: 1.5557 - accuracy: 0.6176 - val_loss: 1.8671 - val_accuracy: 0.5246
# evaluate performance on whole dataset
pre_training_results = model.evaluate(testing_data_101_10)
print(pre_training_results)
# [1.5907552242279053, 0.5817425847053528]
Fine-tuning the Model
# unfreeze entire model
base_model.trainable = True
# keep only the last 5 layers trainable
for layer in base_model.layers[:-5]:
layer.trainable = False
# list all layers in model
for layer in model.layers:
print(layer, layer.trainable)
# <keras.engine.input_layer.InputLayer object at 0x7f695c39b370> True
# <keras.engine.sequential.Sequential object at 0x7f695c39a260> True
# <keras.engine.functional.Functional object at 0x7f6943f0d300> True
# <keras.layers.pooling.global_average_pooling2d.GlobalAveragePooling2D object at 0x7f6943f4e830> True
# <keras.layers.core.dense.Dense object at 0x7f69400c0520> True
# layer 2 is the now only partly unfrozen imported model (efficientnetb0)
for layer_number, layer in enumerate(model.layers[2].layers):
print(layer_number, layer.name, layer.trainable)
# 0 input_1 False
# 1 rescaling False
# 2 normalization False
# ...
# 262 block6h_se_excite False
# 263 block6h_project_conv False
# 264 block6h_project_bn False
# 265 block6h_drop True
# 266 block6h_add True
# 267 top_conv True
# 268 top_bn True
# 269 top_activation True
# recompile the model with the new basemodel
### to prevent overfitting / to better hold on to pre-training
### the learning rate during fine-tuning should be lowered 10x
### default Adam(lr)=1e-3 => 1e-4
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
metrics=['accuracy'])
# continue training
tf.random.set_seed(SEED)
fine_tuning_epochs = pretraining_epochs + 5
history_fine_tuning_model = model.fit(
training_data_101_10,
epochs=fine_tuning_epochs,
# start from last pre-training checkpoint
# training from epoch 6 - 10
initial_epoch = history_model.epoch[-1],
steps_per_epoch=len(training_data_101_10),
validation_data=testing_data_101_10,
# evaluate performance on 15% of the testing dataset
validation_steps=int(0.15 * len(testing_data_101_10)),
callbacks=[tensorboard_callback,
checkpoint_callback])
# Epoch 10/10
# 70s 294ms/step - loss: 1.3161 - accuracy: 0.6547 - val_loss: 1.7494 - val_accuracy: 0.5469
# evaluate performance on whole dataset
fine_tuning_results = model.evaluate(testing_data_101_10)
print(fine_tuning_results)
# pre_training_results
# [1.5907552242279053, 0.5817425847053528]
# fine_tuning_results
# [1.513363242149353, 0.5931881070137024]
# print accuracy curves
plot_accuracy_curves(history_model, "Pre-Training", history_fine_tuning_model, "Fine-Tuning")
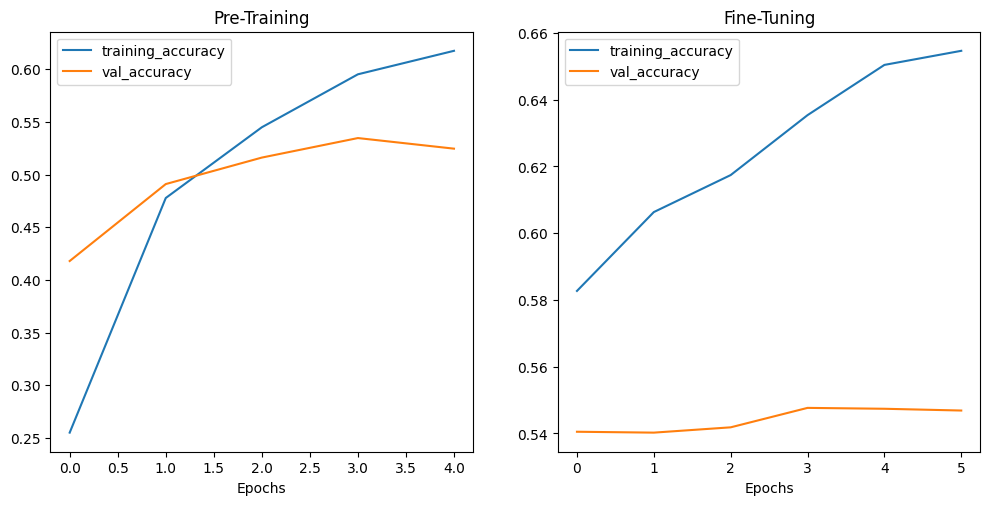
# the validation accuracy increase keeps slowing while training
# accuracy goes up this points to an overfitting problem
combine_training_curves(history_model, history_fine_tuning_model, pretraining_epochs=5)
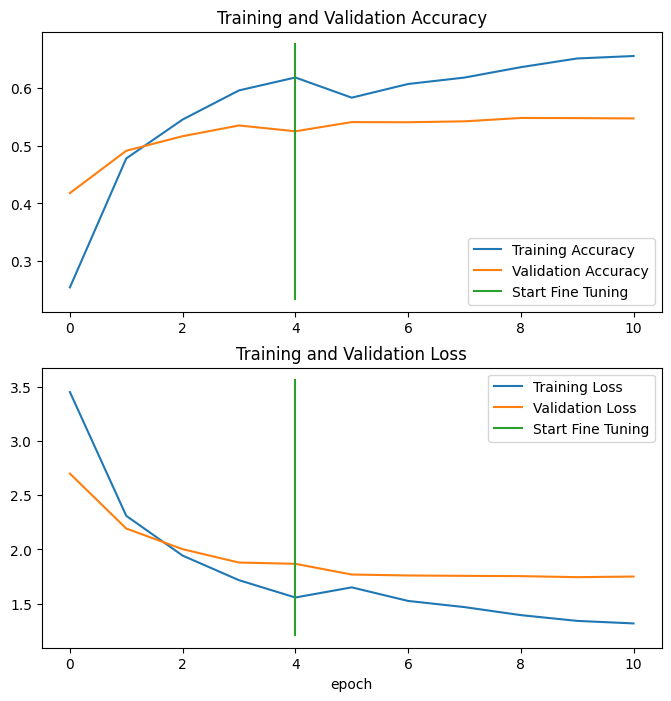
The model keeps improving but there is a growing gap between training and validation. This means that the model is overfitting the test data. Leading to worse results during the validation run.
Saving and Restoring the Trained Model
# saving the model
models_path = "../saved_models/model_101_classes_10_percent_training_data"
# model.save(models_path)
# INFO:tensorflow:Assets written to: ../saved_models/model_101_classes_10_percent_training_data/assets
# load the model
loaded_model = tf.keras.models.load_model(models_path)
# verify the model was loaded correctly
loaded_model_results = loaded_model.evaluate(testing_data_101_10)
print(loaded_model_results)
# fine_tuning_results to compare
# [1.513363242149353, 0.5931881070137024]
# loaded_model_results are the same - it worked!
# [1.513363242149353, 0.5931881070137024]
Evaluating Predictions
# making predictions on all 25250 validation images for 101 classes
test_prediction_probabilities = loaded_model.predict(testing_data_101_10, verbose=1)
print(test_prediction_probabilities.shape)
# (25250, 101)
# display prediction probabilities for the first image
print(test_prediction_probabilities[:1])
# [[2.03596894e-03 3.65167543e-05 2.17581794e-01 5.17010115e-08
# 3.32512741e-06 2.29585039e-05 2.71960180e-05 1.80260338e-06
# 5.30003861e-04 2.73975573e-04 1.06404877e-05 6.97153791e-06
# 1.50283886e-04 2.78270818e-06 3.42393899e-03 2.25132797e-02
# 2.40503272e-04 2.13146021e-04 1.64284266e-03 9.58332021e-05
# 1.32550078e-03 2.55020423e-05 7.39933093e-05 1.92245971e-05
# 8.13204853e-04 1.93982956e-03 8.89056770e-04 6.18012882e-06
# 7.59714108e-04 8.36205290e-05 3.92342417e-06 2.00494527e-04
# 2.51588156e-03 6.87084466e-05 7.40043120e-04 4.45897895e-05
# 4.05072642e-04 4.21193661e-04 1.59948692e-02 2.43602030e-04
# 1.10967096e-03 6.28277950e-04 5.56461528e-05 6.36936966e-05
# 4.16825242e-05 8.82518361e-05 1.96498135e-04 4.21540433e-04
# 1.76622216e-05 1.82788055e-02 4.08739754e-04 2.77833984e-04
# 6.94064796e-02 7.92958029e-03 2.63221909e-06 3.67652555e-03
# 1.11585250e-04 1.25307284e-04 5.01443865e-03 2.33431001e-05
# 9.54853363e-07 6.14999968e-04 1.00202730e-03 6.56907330e-04
# 1.59870205e-03 9.99520998e-05 5.11349281e-05 3.93474428e-03
# 1.97406291e-04 3.40633960e-05 8.98707913e-06 1.06544203e-05
# 5.15696120e-05 1.98621456e-05 5.94679965e-04 3.69085114e-06
# 1.09817571e-04 2.08929856e-03 1.73596389e-04 2.66812931e-05
# 1.44478225e-03 1.20244418e-04 1.30806561e-03 2.10159646e-06
# 2.99385400e-04 5.72092354e-01 2.51285546e-02 1.11975627e-04
# 4.98035988e-05 2.09982645e-05 3.76860640e-08 3.77362909e-07
# 1.97288580e-03 1.36366225e-05 2.58001910e-05 1.10756594e-03
# 6.64085674e-04 9.06130299e-05 4.01897114e-06 8.89552932e-04
# 1.07155865e-04]]
# the highest probabilty is `5.72092354e-01`
# get position of the class with the highest probability
arr = np.array(test_prediction_probabilities[:1])
predicted_class = np.argmax(arr)
print(f"INFO :: The predicted Class Number is: {predicted_class}")
# INFO :: The predicted Class Number is: 85
print(f"INFO :: The predicted Class is: {class_names_101_10[predicted_class]}")
# INFO :: The predicted Class is: samosa
# get all predicted classes
predicted_classes = test_prediction_probabilities.argmax(axis=1)
# there are predicted classes for all validation images
print(predicted_classes.shape)
# (25250,)
# print the predicted classes for the first 10 images
print(predicted_classes[:10])
# [85 0 0 8 8 78 29 46 0 0]
# get all true labels from batched dataset
print(testing_data_101_10)
# <BatchDataset element_spec=(TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32,name=None),
# TensorSpec(shape=(None, 101), dtype=tf.float32, name=None))>
# get class_names index value from unbatched dataset
y_labels = []
for images, labels in testing_data_101_10.unbatch():
y_labels.append(labels.numpy().argmax())
# display first result
print(y_labels[:10])
# these are the true labels and should be identical to `predicted_classes[:10]` above
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# training dataset was not shuffled -> all 10 belong to the same class:
# print(class_names_101_10[0])
# apple_pie
Accuracy Score
Compare the predicted classes to the true classes to get the accuracy score for the model.
# use sklearn to determin the accuracy
sk_accuracy = accuracy_score(y_true=y_labels,
y_pred=predicted_classes)
print(sk_accuracy)
# 0.5931881188118812 => same as validation_accuracy from tensorflow
Confusion Matrix
plot_confusion_matrix(y_pred=y_labels, y_true=predicted_classes, classes=class_names_101_10)

plot_confusion_matrix(y_pred=y_labels,
y_true=predicted_classes,
classes=class_names_101_10,
figsize = (88, 88),
text_size=8)
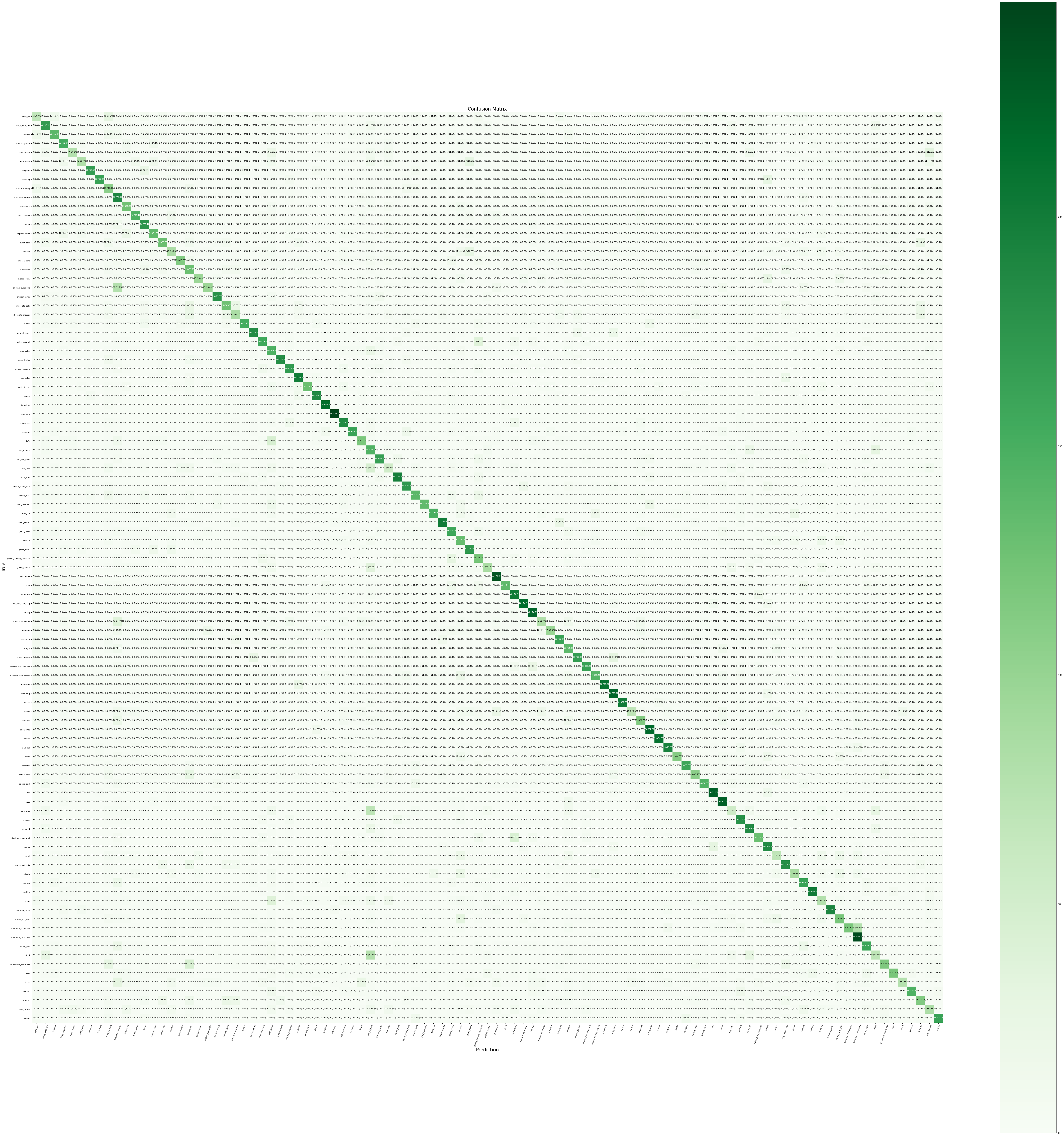
open in new tab to zoom in
We can see that the results are overall impressive. The 59.3% accuracy is mostly based on a couple of classes that might be hard to distinguish in general:
- spaghetti_carbonara <-> spaghetti_bolongnese
- prime_rib <-> steak
- steak <-> filet_mignon
- chicken_quesadilla <-> breakfast_burrito
- hamburger <-> pulled_pork_sandwich
- club_sandwich <-> grilled_cheese_sandwich
...
SciKit Learn Classification Report
print(classification_report(y_true=y_labels,
y_pred=predicted_classes))
| class # | classname | precision | recall | f1-score | support |
|---|---|---|---|---|---|
| 0 | apple_pie | 0.36 | 0.25 | 0.29 | 250 |
| 1 | baby_back_ribs | 0.61 | 0.64 | 0.62 | 250 |
| 2 | baklava | 0.67 | 0.55 | 0.60 | 250 |
| 3 | beef_carpaccio | 0.69 | 0.57 | 0.62 | 250 |
| 4 | beef_tartare | 0.65 | 0.31 | 0.42 | 250 |
| 5 | beet_salad | 0.65 | 0.32 | 0.43 | 250 |
| 6 | beignets | 0.86 | 0.71 | 0.78 | 250 |
| 7 | bibimbap | 0.85 | 0.70 | 0.76 | 250 |
| 8 | bread_pudding | 0.30 | 0.52 | 0.38 | 250 |
| 9 | breakfast_burrito | 0.32 | 0.75 | 0.45 | 250 |
| 10 | bruschetta | 0.48 | 0.52 | 0.50 | 250 |
| 11 | caesar_salad | 0.63 | 0.62 | 0.62 | 250 |
| 12 | cannoli | 0.58 | 0.66 | 0.62 | 250 |
| 13 | caprese_salad | 0.53 | 0.60 | 0.56 | 250 |
| 14 | carrot_cake | 0.50 | 0.54 | 0.52 | 250 |
| 15 | ceviche | 0.36 | 0.31 | 0.33 | 250 |
| 16 | cheese_plate | 0.67 | 0.49 | 0.56 | 250 |
| 17 | cheesecake | 0.36 | 0.42 | 0.39 | 250 |
| 18 | chicken_curry | 0.65 | 0.35 | 0.46 | 250 |
| 19 | chicken_quesadilla | 0.70 | 0.38 | 0.49 | 250 |
| 20 | chicken_wings | 0.71 | 0.70 | 0.70 | 250 |
| 21 | chocolate_cake | 0.61 | 0.52 | 0.56 | 250 |
| 22 | chocolate_mousse | 0.44 | 0.35 | 0.39 | 250 |
| 23 | churros | 0.82 | 0.64 | 0.72 | 250 |
| 24 | clam_chowder | 0.71 | 0.78 | 0.74 | 250 |
| 25 | club_sandwich | 0.65 | 0.56 | 0.60 | 250 |
| 26 | crab_cakes | 0.36 | 0.55 | 0.43 | 250 |
| 27 | creme_brulee | 0.75 | 0.72 | 0.73 | 250 |
| 28 | croque_madame | 0.58 | 0.69 | 0.63 | 250 |
| 29 | cup_cakes | 0.66 | 0.82 | 0.73 | 250 |
| 30 | deviled_eggs | 0.89 | 0.55 | 0.68 | 250 |
| 31 | donuts | 0.74 | 0.74 | 0.74 | 250 |
| 32 | dumplings | 0.75 | 0.86 | 0.80 | 250 |
| 33 | edamame | 0.94 | 0.98 | 0.96 | 250 |
| 34 | eggs_benedict | 0.56 | 0.76 | 0.65 | 250 |
| 35 | escargots | 0.69 | 0.64 | 0.66 | 250 |
| 36 | falafel | 0.53 | 0.43 | 0.47 | 250 |
| 37 | filet_mignon | 0.27 | 0.51 | 0.35 | 250 |
| 38 | fish_and_chips | 0.60 | 0.75 | 0.66 | 250 |
| 39 | foie_gras | 0.42 | 0.16 | 0.23 | 250 |
| 40 | french_fries | 0.80 | 0.74 | 0.77 | 250 |
| 41 | french_onion_soup | 0.65 | 0.70 | 0.68 | 250 |
| 42 | french_toast | 0.54 | 0.50 | 0.52 | 250 |
| 43 | fried_calamari | 0.79 | 0.55 | 0.65 | 250 |
| 44 | fried_rice | 0.73 | 0.55 | 0.63 | 250 |
| 45 | frozen_yogurt | 0.83 | 0.82 | 0.82 | 250 |
| 46 | garlic_bread | 0.53 | 0.62 | 0.57 | 250 |
| 47 | gnocchi | 0.30 | 0.56 | 0.39 | 250 |
| 48 | greek_salad | 0.56 | 0.66 | 0.61 | 250 |
| 49 | grilled_cheese_sandwich | 0.37 | 0.45 | 0.41 | 250 |
| 50 | grilled_salmon | 0.53 | 0.34 | 0.42 | 250 |
| 51 | guacamole | 0.76 | 0.93 | 0.83 | 250 |
| 52 | gyoza | 0.62 | 0.58 | 0.60 | 250 |
| 53 | hamburger | 0.49 | 0.79 | 0.61 | 250 |
| 54 | hot_and_sour_soup | 0.72 | 0.86 | 0.78 | 250 |
| 55 | hot_dog | 0.65 | 0.88 | 0.75 | 250 |
| 56 | huevos_rancheros | 0.40 | 0.34 | 0.37 | 250 |
| 57 | hummus | 0.70 | 0.36 | 0.48 | 250 |
| 58 | ice_cream | 0.66 | 0.66 | 0.66 | 250 |
| 59 | lasagna | 0.48 | 0.49 | 0.49 | 250 |
| 60 | lobster_bisque | 0.77 | 0.67 | 0.71 | 250 |
| 61 | lobster_roll_sandwich | 0.69 | 0.64 | 0.66 | 250 |
| 62 | macaroni_and_cheese | 0.66 | 0.50 | 0.57 | 250 |
| 63 | macarons | 0.97 | 0.80 | 0.88 | 250 |
| 64 | miso_soup | 0.74 | 0.87 | 0.80 | 250 |
| 65 | mussels | 0.88 | 0.81 | 0.84 | 250 |
| 66 | nachos | 0.75 | 0.23 | 0.35 | 250 |
| 67 | omelette | 0.41 | 0.43 | 0.42 | 250 |
| 68 | onion_rings | 0.73 | 0.88 | 0.80 | 250 |
| 69 | oysters | 0.83 | 0.85 | 0.84 | 250 |
| 70 | pad_thai | 0.74 | 0.80 | 0.77 | 250 |
| 71 | paella | 0.86 | 0.45 | 0.59 | 250 |
| 72 | pancakes | 0.66 | 0.62 | 0.64 | 250 |
| 73 | panna_cotta | 0.56 | 0.44 | 0.49 | 250 |
| 74 | peking_duck | 0.58 | 0.59 | 0.59 | 250 |
| 75 | pho | 0.83 | 0.88 | 0.85 | 250 |
| 76 | pizza | 0.64 | 0.90 | 0.75 | 250 |
| 77 | pork_chop | 0.32 | 0.30 | 0.31 | 250 |
| 78 | poutine | 0.61 | 0.68 | 0.65 | 250 |
| 79 | prime_rib | 0.45 | 0.82 | 0.58 | 250 |
| 80 | pulled_pork_sandwich | 0.62 | 0.52 | 0.56 | 250 |
| 81 | ramen | 0.48 | 0.77 | 0.59 | 250 |
| 82 | ravioli | 0.36 | 0.29 | 0.32 | 250 |
| 83 | red_velvet_cake | 0.69 | 0.65 | 0.67 | 250 |
| 84 | risotto | 0.43 | 0.37 | 0.40 | 250 |
| 85 | samosa | 0.48 | 0.66 | 0.55 | 250 |
| 86 | sashimi | 0.88 | 0.77 | 0.82 | 250 |
| 87 | scallops | 0.37 | 0.33 | 0.35 | 250 |
| 88 | seaweed_salad | 0.91 | 0.77 | 0.83 | 250 |
| 89 | shrimp_and_grits | 0.44 | 0.43 | 0.43 | 250 |
| 90 | spaghetti_bolognese | 0.82 | 0.56 | 0.66 | 250 |
| 91 | spaghetti_carbonara | 0.66 | 0.96 | 0.78 | 250 |
| 92 | spring_rolls | 0.61 | 0.64 | 0.63 | 250 |
| 93 | steak | 0.32 | 0.29 | 0.31 | 250 |
| 94 | strawberry_shortcake | 0.54 | 0.58 | 0.56 | 250 |
| 95 | sushi | 0.74 | 0.51 | 0.61 | 250 |
| 96 | tacos | 0.69 | 0.32 | 0.44 | 250 |
| 97 | takoyaki | 0.75 | 0.57 | 0.65 | 250 |
| 98 | tiramisu | 0.42 | 0.47 | 0.45 | 250 |
| 99 | tuna_tartare | 0.36 | 0.35 | 0.35 | 250 |
| 100 | waffles | 0.79 | 0.65 | 0.71 | 250 |
| ____________ | __________ | __________ | _________ | _________ | _________ |
| accuracy | 0.59 | 25250 | |||
| macro avg | 0.62 | 0.59 | 0.59 | 25250 | |
| weighted avg | 0.62 | 0.59 | 0.59 | 25250 |
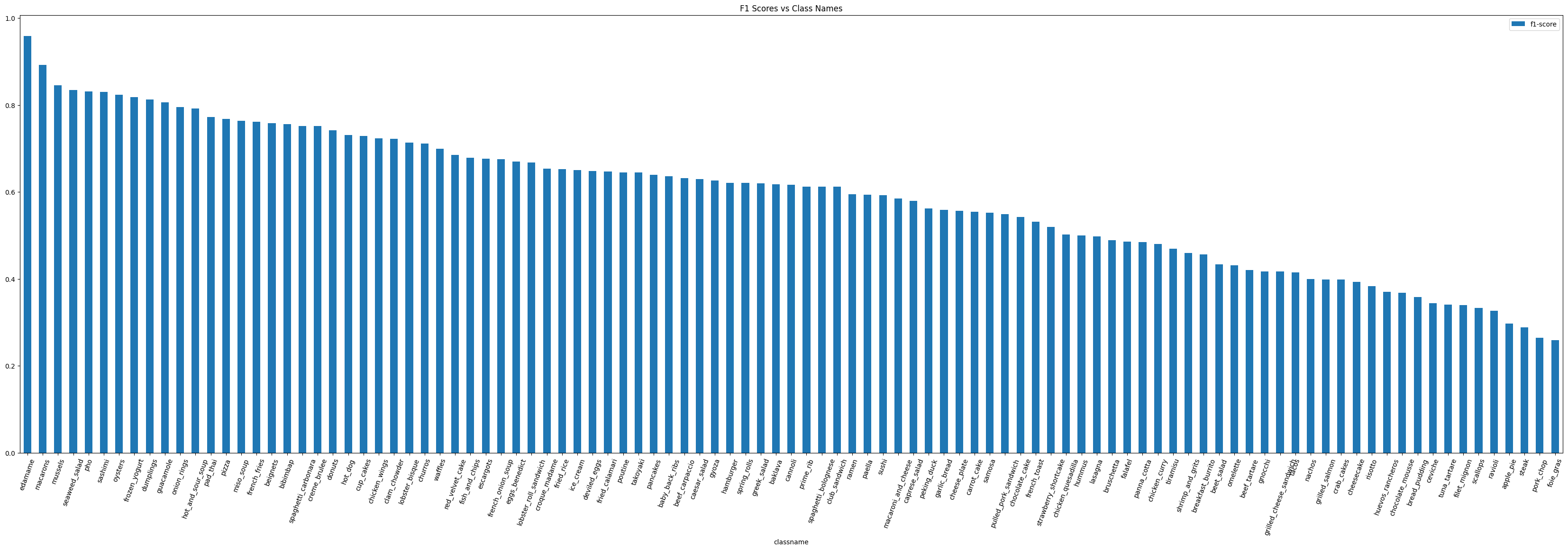
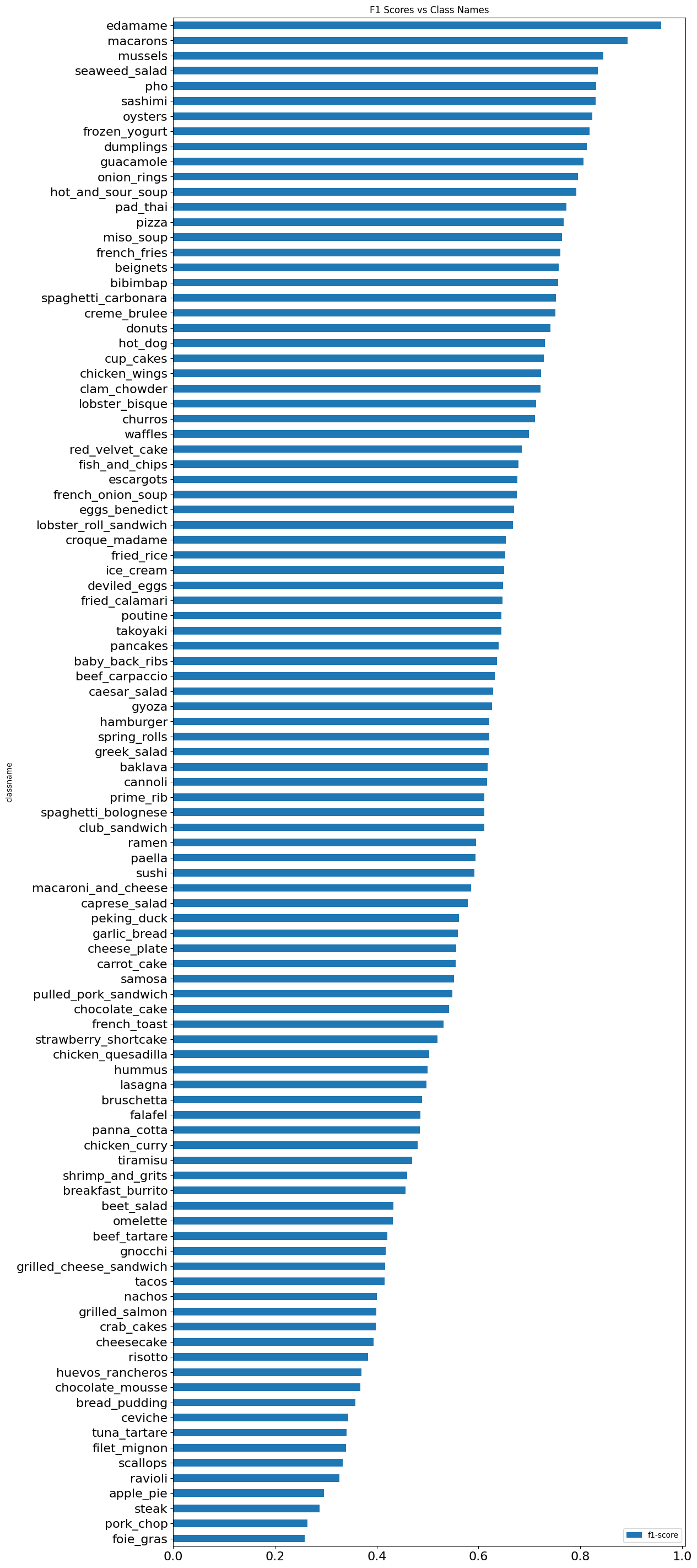
# visualizing the F1 scores per class
classification_report_dict = classification_report(y_true=y_labels,
y_pred=predicted_classes,
output_dict=True)
# {'0': {'precision': 0.36257309941520466,
# 'recall': 0.248,
# 'f1-score': 0.29453681710213775,
# 'support': 250},
# '1': {'precision': 0.6060606060606061,
# 'recall': 0.64,
# 'f1-score': 0.622568093385214,
# 'support': 250},
# ...
# extract f1-scores from dictionary
class_f1_scores = {}
## loop through classification report
for k, v in classification_report_dict.items():
# stop when you reach end of table => class# = accuracy
if k == "accuracy":
break
else:
# get class name and f1 score for class #
class_f1_scores[class_names_101_10[int(k)]] = v["f1-score"]
# print(class_f1_scores)
# {'apple_pie': 0.29453681710213775,
# 'baby_back_ribs': 0.622568093385214,
# 'baklava': 0.6008771929824562,
# ...
# write it into a dataframe
f1_scores = pd.DataFrame({"classname": list(class_f1_scores.keys()),
"f1-score": list(class_f1_scores.values())}).sort_values("f1-score", ascending=False)
print(f1_scores)
| class # | classname | f1-score |
|---|---|---|
| 33 | edamame | 0.958904 |
| 63 | macarons | 0.877729 |
| 75 | pho | 0.854369 |
| 65 | mussels | 0.844075 |
| 69 | oysters | 0.837945 |
| .. | ... | ... |
| 82 | ravioli | 0.320713 |
| 77 | pork_chop | 0.309623 |
| 93 | steak | 0.307368 |
| 0 | apple_pie | 0.294537 |
| 39 | foie_gras | 0.228070 |
f1_bar_chart = f1_scores.plot.bar(x='classname',
y='f1-score',
title="F1 Scores vs Class Names",
rot=70, legend=True,
figsize=(42,12))
f1_scores_inverse = f1_scores.sort_values(by=['f1-score'])
f1_bar_chart = f1_scores_inverse.plot.barh(x='classname',
y='f1-score', fontsize=16,
title="F1 Scores vs Class Names",
rot=0, legend=True,
figsize=(12,36))
Run Predictions
# load and preprocess custom images
def load_and_preprocess_image(filename, img_shape=224, normalize=True):
# load image
image = tf.io.read_file(filename)
# decode image into tensor
image = tf.io.decode_image(image)
# print(image.shape)
# resize image
# image = tf.image.resize(image, [img_shape[0], img_shape[1]])
image = tf.image.resize(image, [img_shape, img_shape])
# print(image.shape)
# models like efficientnet don't
# need normalization -> make it optional
if normalize:
return image/255
else:
return image
# test prediction
file_path = "../datasets/101_food_classes_10_percent/train/caesar_salad/621878.jpg"
# load and preprocess images
test_image = load_and_preprocess_image(file_path, img_shape=224, normalize=False)
# test image is (224, 224, 3) but model expects batch shape (None, 224, 224, 3)
test_image_expanded = tf.expand_dims(test_image, axis=0)
# get probabilities over all classes
prediction_probabilities = model.predict(test_image_expanded)
print(prediction_probabilities)
# get classname for highest probability
predicted_class = class_names_101_10[prediction_probabilities.argmax()]
print(prediction_probabilities.argmax())
print(predicted_class)
# 1/1 [==============================] - 2s 2s/step
# [[1.50316203e-06 6.54247488e-05 3.67346947e-05 2.69303378e-03
# 6.89498498e-04 1.87405187e-03 5.24590746e-07 9.33061761e-04
# 8.65595939e-06 3.25173722e-04 5.10892831e-04 3.65509897e-01
# 5.99349778e-06 7.83709735e-02 2.39862379e-06 5.81788830e-03
# 9.84990475e-05 3.48087779e-05 1.90171588e-04 1.23677682e-02
# 6.14877135e-05 2.40283384e-08 2.12790405e-06 1.13999391e-07
# 5.72356976e-06 7.92978518e-03 9.47913341e-03 7.58256647e-07
# 1.09906327e-02 7.71022357e-08 2.06695331e-05 5.95029064e-07
# 2.49674427e-04 6.92231743e-06 2.87168048e-04 3.15096986e-05
# 4.69330046e-03 6.78624609e-04 7.83884199e-04 1.68355810e-03
# 1.82755193e-05 9.03009493e-07 2.82402652e-05 1.71108084e-04
# 8.81860105e-05 3.58489638e-06 3.93012015e-05 4.95287916e-03
# 4.10611063e-01 2.75604805e-04 5.55841299e-03 1.80046377e-03
# 6.12967357e-04 1.32623117e-03 3.72738782e-07 7.42003205e-04
# 6.33771438e-03 1.89700077e-04 1.42778049e-06 1.78189657e-04
# 2.83671682e-08 5.77349402e-03 1.16270230e-05 1.74992886e-06
# 2.15548107e-06 1.77174807e-05 2.03449815e-03 7.82472896e-04
# 3.88388798e-07 1.51169850e-04 2.83787904e-05 9.07634239e-06
# 3.15053308e-06 2.30283586e-05 1.42191842e-04 3.49449765e-05
# 2.96340950e-05 3.22835840e-05 3.79087487e-06 3.55910415e-05
# 6.37637422e-05 1.73983644e-04 5.40133740e-04 6.14976784e-07
# 1.03683116e-04 9.38189216e-04 1.80834774e-02 7.08847656e-04
# 3.19155771e-03 3.94216222e-05 6.57606563e-07 1.21063601e-06
# 9.14987270e-03 7.52260457e-05 2.20976843e-04 2.03661504e-03
# 1.35101350e-02 1.15356571e-03 1.52835700e-08 1.37943309e-03
# 1.31967667e-04]]
# 48
# greek_salad
# run prediction on random test images
location = testing_directory
plt.figure(figsize=(17, 15))
# pick random test images in random class
for i in range(9):
# get file paths
class_name = random.choice(class_names_101_10)
file_name = random.choice(os.listdir(location + "/" + class_name))
file_path = location + "/" + class_name + "/" + file_name
# load and preprocess images
test_image = load_and_preprocess_image(file_path, img_shape=224, normalize=False)
# test image is (224, 224, 3) but model expects batch shape (None, 224, 224, 3)
test_image_expanded = tf.expand_dims(test_image, axis=0)
# get probabilities over all classes
prediction_probabilities = model.predict(test_image_expanded)
# get classname for highest probability
predicted_class = class_names_101_10[prediction_probabilities.argmax()]
plt.subplot(3, 3, i+1)
# show normalized image
plt.imshow(test_image/255.)
if class_name == predicted_class:
title_color = 'green'
else:
title_color = 'red'
plt.title(f"Pred: {predicted_class} ({prediction_probabilities.max()*100:.2f} %), True: {class_name}",
c=title_color)
plt.axis(False)

Find most Wrong Predictions
# get all images in the test dataset
test_files = testing_directory + "/*/*.jpg"
test_file_paths = []
for file_path in testing_data_101_10.list_files(test_files, shuffle=False):
test_file_paths.append(file_path.numpy())
print(test_file_paths[:1])
# [b'../datasets/101_food_classes_10_percent/test/apple_pie/1011328.jpg']
# create dataframe with filepaths and pred evals
prediction_quality = pd.DataFrame({"img_path": test_file_paths,
"y_true": y_labels,
"y_pred": predicted_classes,
"pred_conf": test_prediction_probabilities.max(axis=1),
"y_true_classname": [class_names_101_10[i] for i in y_labels],
"y_pred_classname": [class_names_101_10[i] for i in predicted_classes]})
prediction_quality
# the "most wrong" predictions are those where the the predicted and
# true classname does not match but the prediction confidence is high:
| # | img_path | y_true | y_pred | pred_conf | y_true_classname | y_pred_classname |
|---|---|---|---|---|---|---|
| 0 | b'../datasets/101_food_classes_10_percent/test... | 0 | 85 | 0.498493 | apple_pie | samosa |
| 1 | b'../datasets/101_food_classes_10_percent/test... | 0 | 0 | 0.821453 | apple_pie | apple_pie |
| 2 | b'../datasets/101_food_classes_10_percent/test... | 0 | 0 | 0.413805 | apple_pie | apple_pie |
| 3 | b'../datasets/101_food_classes_10_percent/test... | 0 | 0 | 0.242082 | apple_pie | apple_pie |
| 4 | b'../datasets/101_food_classes_10_percent/test... | 0 | 8 | 0.625819 | apple_pie | bread_pudding |
| ... | ... | ... | ... | ... | ... | ... |
| 25245 | b'../datasets/101_food_classes_10_percent/test... | 100 | 100 | 0.860823 | waffles | waffles |
| 25246 | b'../datasets/101_food_classes_10_percent/test... | 100 | 100 | 0.969415 | waffles | waffles |
| 25247 | b'../datasets/101_food_classes_10_percent/test... | 100 | 74 | 0.259333 | waffles | peking_duck |
| 25248 | b'../datasets/101_food_classes_10_percent/test... | 100 | 100 | 0.266893 | waffles | waffles |
| 25249 | b'../datasets/101_food_classes_10_percent/test... | 100 | 100 | 0.248541 | waffles | waffles |
# add bool comlumn for correct predictions
prediction_quality["pred_correct"] = prediction_quality["y_true"] == prediction_quality["y_pred"]
# create new dataframe with the 100 most wrong predictions
top_100_wrong = prediction_quality[prediction_quality["pred_correct"] == False].sort_values("pred_conf", ascending=False)[:100]
top_100_wrong
| # | img_path | y_true | y_pred | pred_conf | y_true_classname | y_pred_classname | pred_correct |
|---|---|---|---|---|---|---|---|
| 23797 | b'../datasets/101_food_classes_10_percent/test... | 95 | 86 | 0.997811 | sushi | sashimi | False |
| 10880 | b'../datasets/101_food_classes_10_percent/test... | 43 | 68 | 0.997761 | fried_calamari | onion_rings | False |
| 14482 | b'../datasets/101_food_classes_10_percent/test... | 57 | 51 | 0.997528 | hummus | guacamole | False |
| 17897 | b'../datasets/101_food_classes_10_percent/test... | 71 | 65 | 0.996058 | paella | mussels | False |
| 18001 | b'../datasets/101_food_classes_10_percent/test... | 72 | 67 | 0.995309 | pancakes | omelette | False |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 13199 | b'../datasets/101_food_classes_10_percent/test... | 52 | 9 | 0.947564 | gyoza | breakfast_burrito | False |
| 20551 | b'../datasets/101_food_classes_10_percent/test... | 82 | 83 | 0.947554 | ravioli | red_velvet_cake | False |
| 5114 | b'../datasets/101_food_classes_10_percent/test... | 20 | 38 | 0.947265 | chicken_wings | fish_and_chips | False |
| 548 | b'../datasets/101_food_classes_10_percent/test... | 2 | 67 | 0.947076 | baklava | omelette | False |
| 15750 | b'../datasets/101_food_classes_10_percent/test... | 63 | 29 | 0.946876 | macarons | cup_cakes | False |
# what predictions are most often wrong
grouped_top_100_wrong_pred = top_100_wrong.groupby(['y_pred', 'y_pred_classname']).agg(', '.join).reset_index()
grouped_top_100_wrong_pred
| # | y_pred | y_pred_classname | y_true_classname |
|---|---|---|---|
| 0 | 2 | baklava | garlic_bread |
| 1 | 5 | beet_salad | seaweed_salad |
| 2 | 9 | breakfast_burrito | chicken_quesadilla, pulled_pork_sandwich, chic... |
| 3 | 12 | cannoli | baklava |
| 4 | 16 | cheese_plate | cheesecake |
| 5 | 20 | chicken_wings | fish_and_chips, french_fries |
| 6 | 26 | crab_cakes | falafel |
| 7 | 27 | creme_brulee | hummus |
| 8 | 28 | croque_madame | poutine |
| 9 | 29 | cup_cakes | macarons, carrot_cake, macarons |
| 10 | 31 | donuts | escargots |
| 11 | 32 | dumplings | gyoza, macaroni_and_cheese |
| 12 | 33 | edamame | pho |
| 13 | 38 | fish_and_chips | chicken_wings |
| 14 | 40 | french_fries | macaroni_and_cheese, poutine |
| 15 | 42 | french_toast | waffles |
| 16 | 45 | frozen_yogurt | creme_brulee |
| 17 | 46 | garlic_bread | grilled_cheese_sandwich, grilled_cheese_sandwich |
| 18 | 47 | gnocchi | risotto, hummus |
| 19 | 48 | greek_salad | ceviche |
| 20 | 51 | guacamole | hummus, fried_rice, tuna_tartare, risotto, hum... |
| 21 | 53 | hamburger | pulled_pork_sandwich, eggs_benedict |
| 22 | 54 | hot_and_sour_soup | waffles, french_onion_soup, french_onion_soup |
| 23 | 58 | ice_cream | frozen_yogurt |
| 24 | 64 | miso_soup | cheesecake, scallops, lobster_bisque |
| 25 | 65 | mussels | paella, paella |
| 26 | 67 | omelette | pancakes, baklava |
| 27 | 68 | onion_rings | fried_calamari, fried_calamari, fried_calamari... |
| 28 | 74 | peking_duck | beef_carpaccio |
| 29 | 75 | pho | ramen, hot_and_sour_soup |
| 30 | 76 | pizza | chicken_quesadilla, french_onion_soup, hummus,... |
| 31 | 78 | poutine | peking_duck, takoyaki, spaghetti_bolognese, fr... |
| 32 | 79 | prime_rib | filet_mignon |
| 33 | 81 | ramen | miso_soup, chicken_curry |
| 34 | 83 | red_velvet_cake | cup_cakes, ravioli |
| 35 | 85 | samosa | peking_duck, spring_rolls, baklava |
| 36 | 86 | sashimi | sushi , sushi |
| 37 | 91 | spaghetti_carbonara | spaghetti_bolognese, spaghetti_bolognese, ravi... |
| 38 | 92 | spring_rolls | samosa |
# what classes cause the most wrong predictions
grouped_top_100_wrong_cause = top_100_wrong.groupby(['y_true', 'y_true_classname']).agg(', '.join).reset_index()
grouped_top_100_wrong_cause
| # | y_true | y_true_classname | y_pred_classname |
|---|---|---|---|
| 0 | 2 | baklava | cannoli, samosa, omelette |
| 1 | 3 | beef_carpaccio | peking_duck |
| 2 | 14 | carrot_cake | cup_cakes |
| 3 | 15 | ceviche | greek_salad |
| 4 | 17 | cheesecake | miso_soup, cheese_plate |
| 5 | 18 | chicken_curry | ramen |
| 6 | 19 | chicken_quesadilla | breakfast_burrito, breakfast_burrito, pizza, g... |
| 7 | 20 | chicken_wings | fish_and_chips |
| 8 | 23 | churros | onion_rings, onion_rings, onion_rings |
| 9 | 26 | crab_cakes | spaghetti_carbonara |
| 10 | 27 | creme_brulee | frozen_yogurt |
| 11 | 29 | cup_cakes | red_velvet_cake |
| 12 | 34 | eggs_benedict | hamburger |
| 13 | 35 | escargots | donuts |
| 14 | 36 | falafel | crab_cakes, breakfast_burrito |
| 15 | 37 | filet_mignon | prime_rib |
| 16 | 38 | fish_and_chips | chicken_wings, breakfast_burrito |
| 17 | 40 | french_fries | chicken_wings, poutine |
| 18 | 41 | french_onion_soup | hot_and_sour_soup, pizza, hot_and_sour_soup |
| 19 | 43 | fried_calamari | onion_rings, onion_rings, onion_rings, onion_r... |
| 20 | 44 | fried_rice | guacamole |
| 21 | 45 | frozen_yogurt | ice_cream |
| 22 | 46 | garlic_bread | baklava |
| 23 | 49 | grilled_cheese_sandwich | garlic_bread, garlic_bread |
| 24 | 52 | gyoza | dumplings, breakfast_burrito, breakfast_burrito |
| 25 | 54 | hot_and_sour_soup | pho |
| 26 | 56 | huevos_rancheros | breakfast_burrito, breakfast_burrito |
| 27 | 57 | hummus | guacamole, creme_brulee, guacamole, pizza, gno... |
| 28 | 59 | lasagna | pizza |
| 29 | 60 | lobster_bisque | miso_soup |
| 30 | 62 | macaroni_and_cheese | french_fries, dumplings |
| 31 | 63 | macarons | cup_cakes, cup_cakes |
| 32 | 64 | miso_soup | ramen |
| 33 | 67 | omelette | spaghetti_carbonara |
| 34 | 71 | paella | mussels, mussels |
| 35 | 72 | pancakes | omelette |
| 36 | 74 | peking_duck | samosa, poutine |
| 37 | 75 | pho | edamame |
| 38 | 78 | poutine | croque_madame, french_fries |
| 39 | 80 | pulled_pork_sandwich | breakfast_burrito, hamburger |
| 40 | 81 | ramen | pho |
| 41 | 82 | ravioli | spaghetti_carbonara, spaghetti_carbonara, spag... |
| 42 | 84 | risotto | guacamole, gnocchi |
| 43 | 85 | samosa | spring_rolls |
| 44 | 87 | scallops | miso_soup |
| 45 | 88 | seaweed_salad | beet_salad |
| 46 | 90 | spaghetti_bolognese | spaghetti_carbonara, spaghetti_carbonara, spag... |
| 47 | 92 | spring_rolls | samosa |
| 48 | 95 | sushi | sashimi, sashimi |
| 49 | 96 | tacos | breakfast_burrito |
| 50 | 97 | takoyaki | poutine |
| 51 | 99 | tuna_tartare | guacamole |
| 52 | 100 | waffles | french_toast, hot_and_sour_soup |
# visualize test images
images_displayed = 12
start_index = 0
plt.figure(figsize=(15, 15))
# create tuples from each df row
for i, row in enumerate(top_100_wrong[start_index:start_index+images_displayed].itertuples()):
plt.subplot(4, 3, i+1)
# row[1] => 2nd cell in row = image path
img = load_and_preprocess_image(row[1], normalize=False)
# extract confidence and labels from row
_, _, _, _, pred_conf, y_true_classname, y_pred_classname, _ = row
plt.imshow(img/255.)
plt.title(f"Pred: {y_pred_classname} ({pred_conf*100:.2f} %),\nTrue: {y_true_classname}")
plt.axis(False)

Predict Custom Images��
# get list of custom image file paths
custom_images_path = "../datasets/custom_images/"
custom_images = [ custom_images_path + img_path for img_path in os.listdir(custom_images_path)]
custom_images
# ['../datasets/custom_images/cheesecake.jpg',
# '../datasets/custom_images/crema_catalana.jpg',
# '../datasets/custom_images/fish_and_chips.jpg',
# '../datasets/custom_images/jiaozi.jpg',
# '../datasets/custom_images/paella.jpg',
# '../datasets/custom_images/pho.jpg',
# '../datasets/custom_images/quesadilla.jpg',
# '../datasets/custom_images/ravioli.jpg',
# '../datasets/custom_images/waffles.jpg']
# run prediction on custom images
for image in custom_images:
image = load_and_preprocess_image(image, normalize=False)
# test image is (224, 224, 3) but model expects batch shape (None, 224, 224, 3)
image_expanded = tf.expand_dims(image, axis=0)
# get probabilities over all classes
prediction_probabilities = model.predict(image_expanded)
# get classname for highest probability
predicted_class = class_names_101_10[prediction_probabilities.argmax()]
# plot normalized image
plt.figure()
plt.imshow(image/255.)
plt.title(f"Pred: {predicted_class} ({prediction_probabilities.max()*100:.2f} %)")
plt.axis(False)
