Yolo App - Tesseract Optical Character Recognition

- Prepare your Images and get Data
- Train your Tensorflow Model
- Use your Model to do Predictions
- Use Tesseract to Read Number Plates
- Flask Web Application
- Yolo v5 - Data Prep
Now that I have the Tensorflow model that finds number plates inside images I can use OpenCV to cut them out and hand them over to Tesseract - see Install Tesseract on Arch LINUX - to apply some Optical Character Recognition (OCR).
Load an Image
import pytesseract as pt
path = './test_images/index10.jpg'
image, cods = object_detection(path)
plt.figure(figsize=(10,8))
plt.imshow(image)
plt.show()
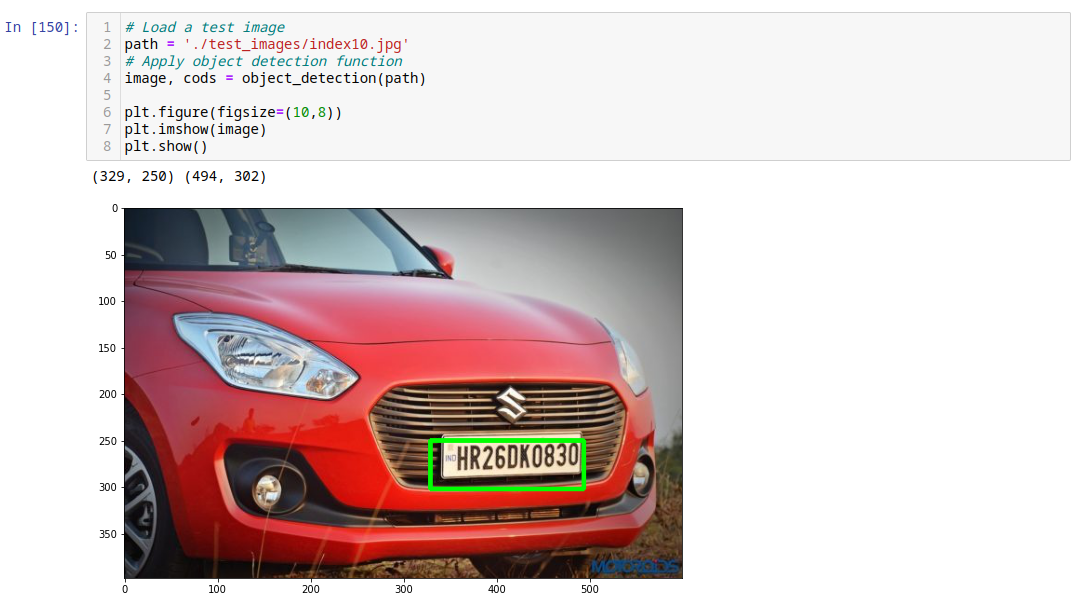
Extract Number Plate
img = np.array(load_img(path))
xmin ,xmax,ymin,ymax = cods[0]
roi = img[ymin:ymax,xmin:xmax]
plt.imshow(roi)
print('Original')
plt.show()

Data Preprocessing
Depending on the image source we might have to add some processing to the extracted region of interest to make it more readable:
# Turn grayscale
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
gray_roi = cv2.bitwise_not(gray_roi)
# threshold the image, setting all foreground pixels to
# 255 and all background pixels to 0 (invert)
thresh_roi = cv2.threshold(gray_roi, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
plt.imshow(thresh_roi)
print('Threshold')
plt.show()
canny_roi = cv2.Canny(roi, 85, 255)
plt.imshow(canny_roi)
print('Canny')
plt.show()
Tweak the thresholds until you get the best OCR results for your use case:
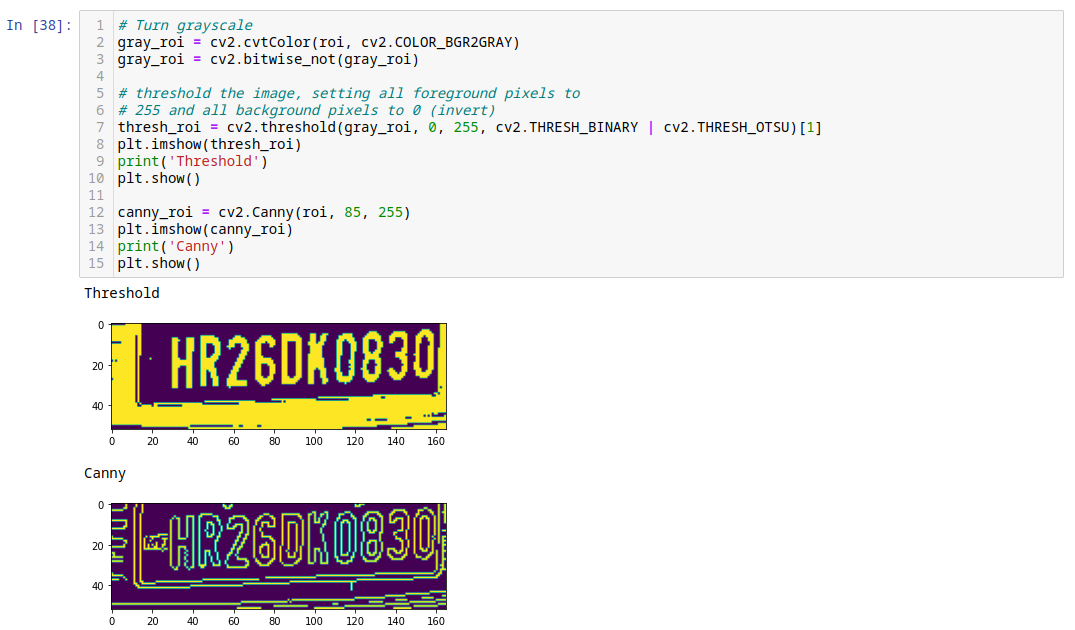
Use Tesseract
# OCR the ROI using Tesseract
text_roi = pt.image_to_string(roi)
print('Original:',text_roi)
text_thresh = pt.image_to_string(thresh_roi)
print('Threshold:',text_thresh)
text_canny = pt.image_to_string(canny_roi)
print('Canny:',text_canny)
Threshold gives me the best results for the given image, while canny fails completely. Your results will differ depending on your image source:
Original: i ~HR26I]KOB30|
Threshold: i\ HR26DK0830
Canny:
Skew Detection and Correction
THIS DOES NOT WORK: I will have to look into this more - the method by pyimagesearch seems to be distracted when the text is not only rotated but there is also some perspective shift on it.
Tesseract, unfortunately, is very sensitive against skew angles. As soon as the text is not perfectly horizontal you are not going to get any results:
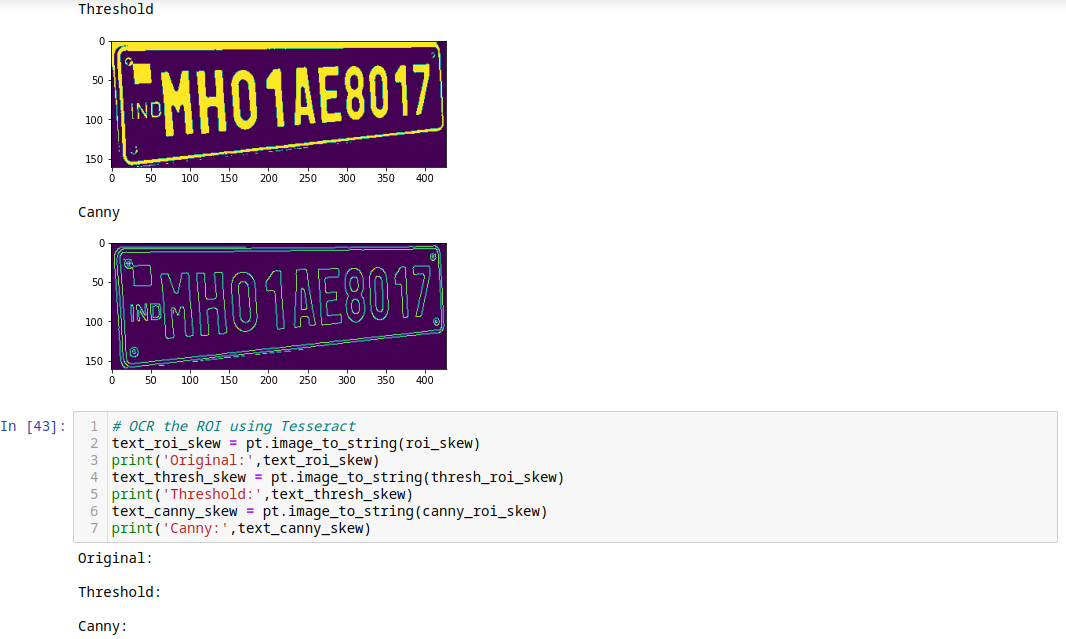
Here is an implementation to de-skew your text using OpenCV. I can use it to compute the minimum rotated bounding box that contains the text regions:
# grab the (x, y) coordinates of all pixel values that
# are greater than zero, then use these coordinates to
# compute a rotated bounding box that contains all
# coordinates
pix_coords = np.column_stack(np.where(thresh_roi_skew > 0))
angle = cv2.minAreaRect(pix_coords)[-1]
# the `cv2.minAreaRect` function returns values in the
# range [-90, 0); as the rectangle rotates clockwise the
# returned angle trends to 0 -- in this special case we
# need to add 90 degrees to the angle
if angle < -45:
angle = -(90 + angle)
# otherwise, just take the inverse of the angle to make
# it positive
else:
angle = -angle
# rotate the image to deskew it
(h, w) = thresh_roi_skew.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(thresh_roi_skew, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
# draw the correction angle on the image so we can validate it
cv2.putText(rotated, "Angle: {:.2f} degrees".format(angle), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the output image
print("[INFO] rotation angle: {:.3f}".format(angle))
plt.imshow(rotated)
plt.show()