Keras for Tensorflow - Recurrent Neural Networks

Keras is built on top of TensorFlow 2 and provides an API designed for human beings. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear & actionable error messages.
See also:
- Keras for Tensorflow - An (Re)Introduction 2023
- Keras for Tensorflow - Artificial Neural Networks
- Keras for Tensorflow - Convolutional Neural Networks
- Keras for Tensorflow - VGG16 Network Architecture
- Keras for Tensorflow - Recurrent Neural Networks
Long Short-Term Memory Models (LSTM)
Recurrent Neural Networks (RNN) are widely used to work with sequence data such as time series or natural language. Unlike CNN's RNN's persist data by introducing loops in their data flow - allowing you them to make predictions based on past events. Types of RNN's are (Image Source):
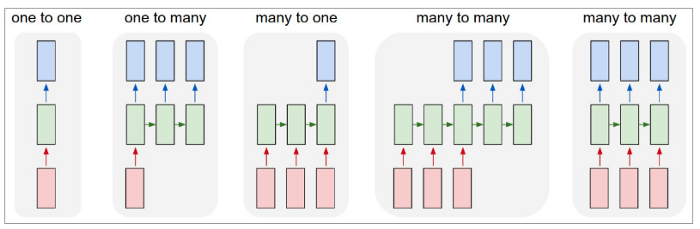
- One-to-One: A network with a single in- and output like the image classification we had before.
- One-to-Many: A network with a single in- and multiple outputs. E.g. a caption generator for an input image.
- Many-to-One: A network with multiple in- and a single output. E.g. a sentiment analyzer.
- Many-to-Many: A network with multiple in- and multiple outputs. E.g. a language translator.
Time Series
We can use the International Airline Passengers dataset to build and train an RNN prediction model in Keras:
import pandas as pd
import matplotlib.pyplot as plt
# loading the passenger into a dataframe
df = pd.read_csv('data/international-airline-passengers.csv', usecols=[1], skipfooter=2, engine='python')
df.plot()
plt.show()
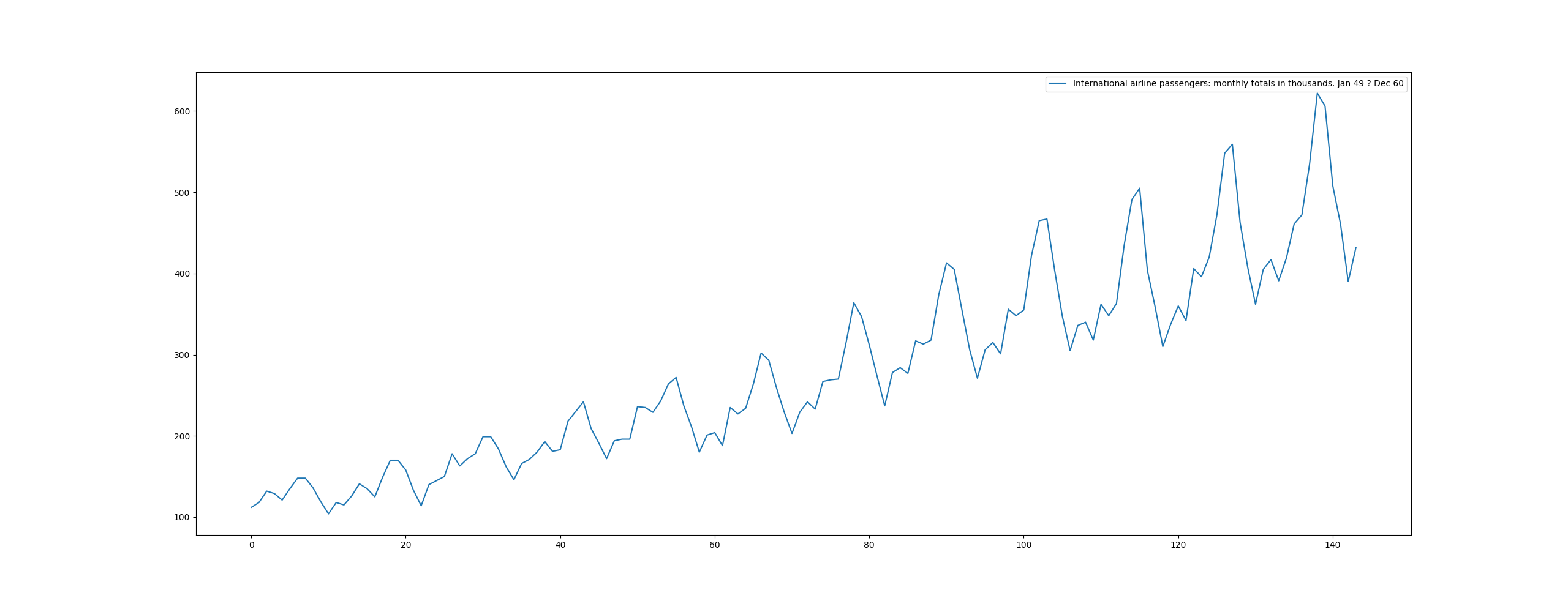
We need to first normalize the dataset so that all values range in between 0 and 1 and split the set into training and testing data:
from sklearn.preprocessing import MinMaxScaler
# pre-processing
dataset = df.values
dataset = dataset.astype('float32')
## normalize data to 0->1 range
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
## data split 70/30
train_size = int(len(dataset)*.70)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
print(train.shape, test.shape)
# (100, 1) (44, 1)
# creating the timeseries datasets
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
# input data
a = dataset[i:(i+look_back), 0]
dataX.append(a)
# output data
b = dataset[(i+look_back), 0]
dataY.append(b)
return np.array(dataX), np.array(dataY)
trainX, trainY = create_dataset(train)
testX, testY = create_dataset(test)
trainX = trainX.reshape((trainX.shape[0], 1, trainX.shape[1]))
testX = testX.reshape((testX.shape[0], 1, testX.shape[1]))
With our data pre-processed we can now compile our simple Long Short-Term Memory model:
# building the model
model = Sequential()
model.add(LSTM(4, input_shape=(1,1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 4) 96
dense (Dense) (None, 1) 5
=================================================================
Total params: 101
Trainable params: 101
Non-trainable params: 0
The compiled model now need to be fitted to our dataset:
# fitting the model
model.fit(trainX, trainY, batch_size=1, epochs=100)
To run predictions we first have to undo the normalization we have applied to our values:
# run prediction
trainPred = model.predict(trainX)
testPred = model.predict(testX)
# undo normalization
trainPred = scaler.inverse_transform(trainPred)
testPred = scaler.inverse_transform(testPred)
trainY = scaler.inverse_transform([trainY])
trainX = scaler.inverse_transform([testY])
And we can plot the predicted values on top of the training dataset:

From left to right we see three training runs with 100, 1000 and 10000 Epochs. We can see that the predicted value start to fit the earlier passenger numbers better and better. But the fit for later years continues to decrease. Thinking that this might be an overfitting issue I added a dropout layer to my model:
# building the model
model = Sequential()
model.add(LSTM(4, input_shape=(1,1)))
model.add(Dropout(0.25))
model.add(Dense(1))
And I can see a much better fit with a Dropout - even though there is still some more room for improvement:
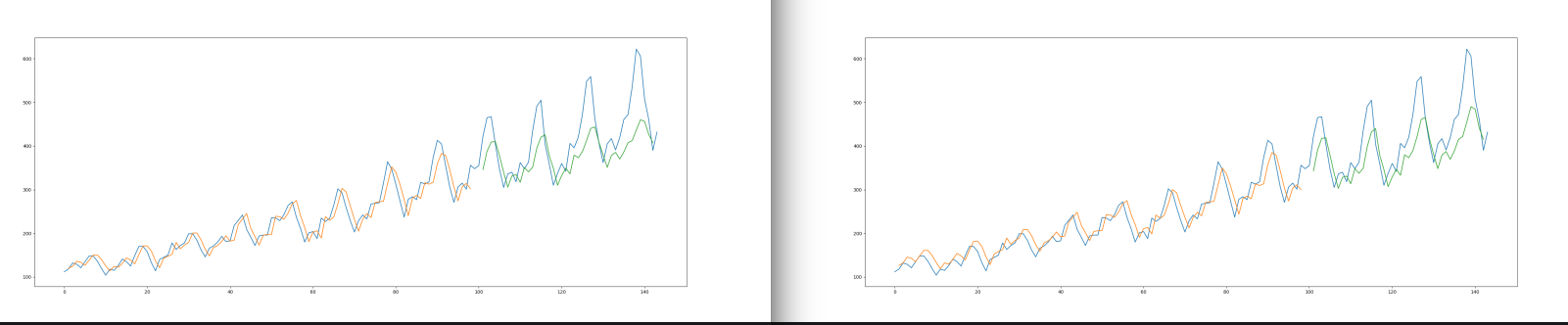
Both those graph show the prediction validation after 1000 epochs of training. On the left is the previous model without and on the right the model with a Dropout layer.
Natural Language
To work with a natural language problem we can use the IMDB dataset provided by Keras:
from keras.datasets import imdb
# loading an excerpt from the imdb dataset
top_words = 5000
(Xtrain, Ytrain), (Xtest, Ytest) = imdb.load_data(num_words=top_words)
# truncate movie reviews > 500 words
max_review_size = 500
Xtrain = sequence.pad_sequences(Xtrain, maxlen=max_review_size)
Xtest = sequence.pad_sequences(Xtest, maxlen=max_review_size)
As LSTM model we need a binary classifier - is the review positive or negative:
# building the model
## number of feature outputs
feature_length = 32
model = Sequential()
model.add(Embedding(top_words, feature_length, input_length=max_review_size))
model.add(LSTM(100))
##output binary classification
model.add(Dense(1, activation=sigmoid))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 500, 32) 160000
lstm (LSTM) (None, 100) 53200
dense (Dense) (None, 1) 101
=================================================================
Total params: 213,301
Trainable params: 213,301
Non-trainable params: 0
_________________________________________________________________
Now we can fit this model to our review dataset and validate the training:
# training the model
model.fit(Xtrain, Ytrain, epoch=2, batch_size=118)
## training validation
val_loss, val_score = model.evaluate(Xtest, Ytest)
print(val_loss, val_score)
Already after 2 epochs I am seeing an accuracy of 83% - 0.3782317042350769 0.8289600014686584. Going to 86% after 10 epochs - 0.4176311194896698 0.8595200181007385. So this seems to be a problem that can be solved with patience :)