
Building a Tensorflow Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
"Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Trans former. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion."
Vision Transformers perform very poorly on small training datasets (smaller a couple of million images). So this ViT is not going to outperform the CNN from earlier. The next step - after this proof-of-concept is to use transfer-learning to build on a ViT that has already been trained on a huge dataset.
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay)
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import (
Conv2D,
BatchNormalization,
LayerNormalization,
Dense,
Embedding,
MultiHeadAttention,
Layer,
Add,
Flatten,
RandomFlip,
RandomRotation,
RandomContrast,
RandomBrightness
)
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import CategoricalAccuracy, TopKCategoricalAccuracy
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import image_dataset_from_directory
SEED = 42
BATCH_SIZE = 32
SIZE = 256
LABELS = ['angry', 'happy', 'sad']
NLABELS = len(LABELS)
EPOCHS = 20
LR = 0.001
IN_SIZE = 256
PATCH_SIZE = 16
NPATCHES = 256
NHEADS = 4 #8
NLAYERS = 2 #4
HIDDEN_SIZE = 768
DENSE_UNITS = 128 #1024
Dataset
train_directory = './dataset/Emotions Dataset/Emotions Dataset/train'
test_directory = './dataset/Emotions Dataset/Emotions Dataset/test'
train_dataset = image_dataset_from_directory(
train_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED,
interpolation='bilinear',
follow_links=False,
crop_to_aspect_ratio=False
)
# Found 6799 images belonging to 3 classes.
test_dataset = image_dataset_from_directory(
test_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED
)
# Found 2278 images belonging to 3 classes.
data_augmentation = Sequential([
RandomRotation(factor = (0.25),),
RandomFlip(mode='horizontal',),
RandomContrast(factor=0.1),
RandomBrightness(0.1)
])
training_dataset = (
train_dataset
.map(lambda image, label: (data_augmentation(image), label))
.prefetch(tf.data.AUTOTUNE)
)
testing_dataset = (
test_dataset.prefetch(
tf.data.AUTOTUNE
)
)
Data Preprocessing (Extracting Patches)
test_image = cv.cvtColor(cv.imread('dataset/angry.jpg'), cv.COLOR_BGR2RGB)
test_image = cv.resize(test_image, (IN_SIZE, IN_SIZE))
patches = tf.image.extract_patches(
images = tf.expand_dims(test_image, axis=0),
sizes = [1, PATCH_SIZE, PATCH_SIZE, 1],
strides = [1, PATCH_SIZE, PATCH_SIZE, 1],
rates = [1, 1, 1, 1],
padding = 'VALID'
)
patches.shape
# TensorShape([1, 16, 16, 768])
# 1 image with 3 times (RGB) 16x16 patches => 3x16x16=786
patches = tf.reshape(patches, (patches.shape[0], 256, 768))
patches.shape
# TensorShape([1, 256, 768])
plt.figure(figsize=(8,8))
for i in range(patches.shape[1]):
ax = plt.subplot(16,16, i+1)
plt.imshow(tf.reshape(patches[0,i,:], (16,16,3)))
plt.axis('off')

class PatchEncoder(Layer):
def __init__ (self, NPATCHES, HIDDEN_SIZE):
super(PatchEncoder, self).__init__(name = 'patch_encoder')
self.linear_projection = Dense(HIDDEN_SIZE, name = 'linear_projection')
self.positional_embedding = Embedding(NPATCHES, HIDDEN_SIZE, name = 'positional_embedding')
self.NPATCHES = NPATCHES
def call(self, x):
patches = tf.image.extract_patches(
images = x,
sizes = [1, PATCH_SIZE, PATCH_SIZE, 1],
strides = [1, PATCH_SIZE, PATCH_SIZE, 1],
rates = [1, 1, 1, 1],
padding = 'VALID'
)
patches = tf.reshape(patches, (tf.shape(patches)[0], -1, patches.shape[-1]))
embedding_input = tf.range(start=0, limit=NPATCHES, delta=1)
output = self.linear_projection(patches) + self.positional_embedding(embedding_input)
return output
# test patch encoder
patch_enc = PatchEncoder(NPATCHES, HIDDEN_SIZE)
patch_enc(tf.zeros([32, 256, 256, 3]))
# <tf.Tensor: shape=(32, 256, 768), dtype=float32
Build the Transformer Encoder
class TransformerEncoder(Layer):
def __init__ (self, NHEADS, HIDDEN_SIZE):
super(TransformerEncoder, self).__init__(name = 'transformer_encoder')
self.layer_norm_1 = LayerNormalization(name = 'layer_normalization_1')
self.layer_norm_2 = LayerNormalization(name = 'layer_normalization_2')
self.multi_head_attention = MultiHeadAttention(
num_heads = NHEADS,
key_dim = HIDDEN_SIZE
)
self.dense_1 = Dense(HIDDEN_SIZE, activation='gelu')
self.dense_2 = Dense(HIDDEN_SIZE, activation='gelu') #tf.nn.gelu
def call(self, input):
x_1 = self.layer_norm_1(input)
x_1 = self.multi_head_attention(x_1, x_1)
x_1 = Add()([x_1, input])
x_2 = self.layer_norm_2(x_1)
x_2 = self.dense_1(x_2)
output = self.dense_2(x_2)
output = Add()([output, x_2])
return output
# test the transformer
trans_enc = TransformerEncoder(NHEADS, HIDDEN_SIZE)
trans_enc(tf.zeros([1, 256, 768]))
# <tf.Tensor: shape=(1, 256, 768), dtype=float32
Build the ViT Model
class ViT(Model):
def __init__(self, NHEADS, HIDDEN_SIZE, NPATCHES, NLAYERS, NLABELS, DENSE_UNITS):
super(ViT, self).__init__(name='vision_transformer')
self.NLAYERS = NLAYERS
self.patch_encoder = PatchEncoder(NPATCHES, HIDDEN_SIZE)
self.trans_encs = [TransformerEncoder(NHEADS, HIDDEN_SIZE) for _ in range(NLAYERS)]
self.dense_1 = Dense(DENSE_UNITS, activation='gelu')
self.dense_2 = Dense(DENSE_UNITS, activation='gelu')
self.dense_3 = Dense(NLABELS, activation='softmax')
def call(self, input, training=True):
x = self.patch_encoder(input)
for i in range(self.NLAYERS):
x = self.trans_encs[i](x)
x = Flatten()(x)
x = self.dense_1(x)
x = self.dense_2(x)
return self.dense_3(x)
vit = ViT(NHEADS, HIDDEN_SIZE, NPATCHES, NLAYERS, NLABELS, DENSE_UNITS)
# test the model
vit(tf.zeros([32,256,256,3]))
# <tf.Tensor: shape=(32, 3), dtype=float32
vit.summary()
Model Training
loss_function = CategoricalCrossentropy()
metrics = [CategoricalAccuracy(name='accuracy'), TopKCategoricalAccuracy(k=2, name='topk_accuracy')]
vit.compile(
optimizer = Adam(learning_rate = LR),
loss = loss_function,
metrics = metrics
)
vit_history = vit.fit(
training_dataset,
validation_data = testing_dataset,
epochs = EPOCHS,
verbose = 1
)
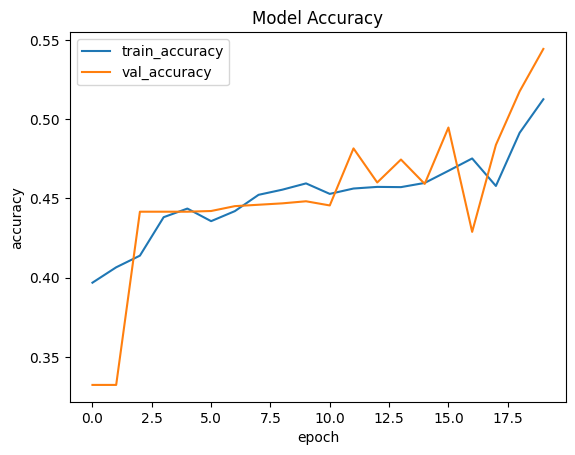
# loss: 0.9974
# accuracy: 0.5126
# topk_accuracy: 0.8128
# val_loss: 0.9803
# val_accuracy: 0.5443
# val_topk_accuracy: 0.8090
vit.evaluate(testing_dataset)
# loss: 0.9803 - accuracy: 0.5443 - topk_accuracy: 0.8090
plt.plot(vit_history.history['loss'])
plt.plot(vit_history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.show()
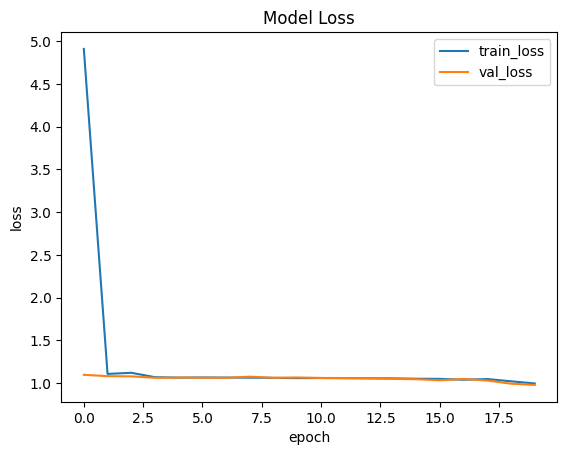
plt.plot(vit_history.history['accuracy'])
plt.plot(vit_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.show()
plt.figure(figsize=(16,16))
for images, labels in testing_dataset.take(1):
for i in range(16):
ax = plt.subplot(4,4,i+1)
true = "True: " + LABELS[tf.argmax(labels[i], axis=0).numpy()]
pred = "Predicted: " + LABELS[
tf.argmax(vit(tf.expand_dims(images[i], axis=0)).numpy(), axis=1).numpy()[0]
]
plt.title(
true + "\n" + pred
)
plt.imshow(images[i]/255.)
plt.axis('off')
plt.savefig('assets/tf_Emotion_Detection_30.webp', bbox_inches='tight')

y_pred = []
y_test = []
for img, label in testing_dataset:
y_pred.append(vit(img))
y_test.append(label.numpy())
conf_mtx = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(
np.argmax(y_test[:-1], axis=-1).flatten(),
np.argmax(y_pred[:-1], axis=-1).flatten()
),
display_labels=LABELS
)
fig, ax = plt.subplots(figsize=(16,12))
conf_mtx.plot(ax=ax, cmap='plasma', include_values=False)
plt.savefig('assets/tf_Emotion_Detection_31.webp', bbox_inches='tight')

Vision Transformer (vit-base-patch16-224-in21k)
"The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224."
This is using the same transformer as before - but is now pre-trained on a large dataset. Let's see if this can beat the results I received from the not-pre-trained ViT before:
loss: 0.9803 - accuracy: 0.5443 - topk_accuracy: 0.8090(self-build: num_attention_heads=4,num_hidden_layers=2, hidden_size=144)loss: 0.9404 - accuracy: 0.5610 - topk_accuracy: 0.8385(hf model: num_attention_heads=4,num_hidden_layers=2, hidden_size=144)loss: 0.9572 - accuracy: 0.5399 - topk_accuracy: 0.8306(hf model: num_attention_heads=8,num_hidden_layers=4, hidden_size=144)loss: 1.0289 - accuracy: 0.5000 - topk_accuracy: 0.7761(hf model: num_attention_heads=8,num_hidden_layers=4, hidden_size=768)- The accuracy here is lower - but I massively reduced the learning rate and the accuracy was still rising steadily
loss: 0.5340 - accuracy: 0.7730 - topk_accuracy: 0.9315(hf model with pre-trained weights: num_attention_heads=8,num_hidden_layers=4, hidden_size=768)
For the training with pretrained weights I increased the learning-rate again by a factor of 10. But I had to down-configure the model to prevent out-of-memory errors (configuration as seen below). So there is still room to improve the results on better hardware and with some tinkering. Still - this pre-trained model performs significantly better than the untrained transformer and already comes close to rival the CNN solution (MobileNetV3Small) used before:
loss: 0.3906 - accuracy: 0.8455 - topk_accuracy: 0.9627- MobileNetV3Small as reference
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
!pip install transformers
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay)
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import (
Conv2D,
BatchNormalization,
LayerNormalization,
Dense,
Input,
Embedding,
MultiHeadAttention,
Layer,
Add,
Resizing,
Rescaling,
Permute,
Flatten,
RandomFlip,
RandomRotation,
RandomContrast,
RandomBrightness
)
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import CategoricalAccuracy, TopKCategoricalAccuracy
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import image_dataset_from_directory
from transformers import ViTConfig, ViTModel, AutoImageProcessor, TFViTModel
SEED = 42
LABELS = ['angry', 'happy', 'sad']
NLABELS = len(LABELS)
BATCH_SIZE = 32
SIZE = 224
EPOCHS = 20
LR = 5e-6 # default 0.001
HIDDEN_SIZE = 768 # default 768
NHEADS = 8 # default 12
NLAYERS = 4 # default 12
Dataset
train_directory = './dataset/Emotions Dataset/Emotions Dataset/train'
test_directory = './dataset/Emotions Dataset/Emotions Dataset/test'
train_dataset = image_dataset_from_directory(
train_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED,
interpolation='bilinear',
follow_links=False,
crop_to_aspect_ratio=False
)
# Found 6799 images belonging to 3 classes.
test_dataset = image_dataset_from_directory(
test_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED
)
# Found 2278 images belonging to 3 classes.
data_augmentation = Sequential([
RandomRotation(factor = (0.25),),
RandomFlip(mode='horizontal',),
RandomContrast(factor=0.1),
RandomBrightness(0.1)
])
resize_rescale_reshape = Sequential([
Resizing(SIZE, SIZE),
Rescaling(1./255),
# transformer expects image shape (3,224,224)
Permute((3,1,2))
])
training_dataset = (
train_dataset
.map(lambda image, label: (data_augmentation(image), label))
.prefetch(tf.data.AUTOTUNE)
)
testing_dataset = (
test_dataset.prefetch(
tf.data.AUTOTUNE
)
)
ViT Model
# Initializing a ViT vit-base-patch16-224 style configuration
configuration = ViTConfig(
image_size=SIZE,
hidden_size=HIDDEN_SIZE,
num_attention_heads=NHEADS,
num_hidden_layers=NLAYERS
)
# Initializing a model with random weights from the vit-base-patch16-224 style configuration
# base_model = TFViTModel(configuration)
# use pretrained weights for the model instead
base_model = TFViTModel.from_pretrained("google/vit-base-patch16-224-in21k", config=configuration)
# Accessing the model configuration
configuration = base_model.config
configuration
inputs = Input(shape=(224,224,3))
x = resize_rescale_reshape(inputs)
x = base_model.vit(x)[0][:,0,:]
output = Dense(NLABELS, activation='softmax')(x)
vit_model = Model(inputs=inputs, outputs=output)
vit_model.summary()
# testing the pretrained model
test_image = cv.imread('./dataset/angry.jpg')
test_image = cv.resize(test_image, (SIZE, SIZE))
vit_model(tf.expand_dims(test_image, axis = 0))
# numpy=array([[0.4467356 , 0.46105713, 0.09220731]]
Model Training
loss_function = CategoricalCrossentropy()
metrics = [CategoricalAccuracy(name='accuracy'), TopKCategoricalAccuracy(k=2, name='topk_accuracy')]
vit_model.compile(
optimizer = Adam(learning_rate = LR),
loss = loss_function,
metrics = metrics
)
vit_history = vit_model.fit(
training_dataset,
validation_data = testing_dataset,
epochs = EPOCHS,
verbose = 1
)
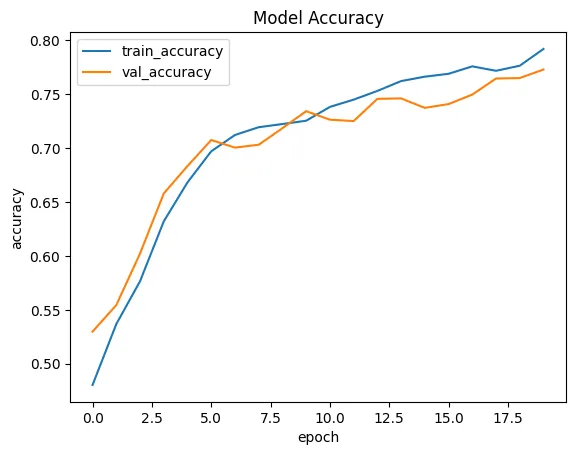
# loss: 0.5090
# accuracy: 0.7922
# topk_accuracy: 0.9384
# val_loss: 0.5340
# val_accuracy: 0.7730
# val_topk_accuracy: 0.9315
vit_model.evaluate(testing_dataset)
# loss: 0.5340 - accuracy: 0.7730 - topk_accuracy: 0.9315
plt.plot(vit_history.history['loss'])
plt.plot(vit_history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.savefig('assets/tf_Emotion_Detection_32.webp', bbox_inches='tight')

plt.plot(vit_history.history['accuracy'])
plt.plot(vit_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.savefig('assets/tf_Emotion_Detection_33.webp', bbox_inches='tight')
plt.figure(figsize=(16,16))
for images, labels in testing_dataset.take(1):
for i in range(16):
ax = plt.subplot(4,4,i+1)
true = "True: " + LABELS[tf.argmax(labels[i], axis=0).numpy()]
pred = "Predicted: " + LABELS[
tf.argmax(vit_model(tf.expand_dims(images[i], axis=0)).numpy(), axis=1).numpy()[0]
]
plt.title(
true + "\n" + pred
)
plt.imshow(images[i]/255.)
plt.axis('off')
plt.savefig('assets/tf_Emotion_Detection_34.webp', bbox_inches='tight')

y_pred = []
y_test = []
for img, label in testing_dataset:
y_pred.append(vit_model(img))
y_test.append(label.numpy())
conf_mtx = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(
np.argmax(y_test[:-1], axis=-1).flatten(),
np.argmax(y_pred[:-1], axis=-1).flatten()
),
display_labels=LABELS
)
fig, ax = plt.subplots(figsize=(16,12))
conf_mtx.plot(ax=ax, cmap='plasma', include_values=False)
plt.savefig('assets/tf_Emotion_Detection_35.webp', bbox_inches='tight')

Vision Transformer (DeiT)
Training data-efficient image transformers & distillation through attention
Hugo Touvron,Matthieu Cord,Matthijs Douze,Francisco Massa,Alexandre Sablayrolles,Herve J'egou
"Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These highperforming vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption. In this work, we produce competitive convolution-free transformers by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks."
!pip install transformers
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay)
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import (
Conv2D,
BatchNormalization,
LayerNormalization,
Dense,
Input,
Embedding,
MultiHeadAttention,
Layer,
Add,
Resizing,
Rescaling,
Permute,
Flatten,
RandomFlip,
RandomRotation,
RandomContrast,
RandomBrightness
)
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import CategoricalAccuracy, TopKCategoricalAccuracy
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import image_dataset_from_directory
from transformers import DeiTConfig, TFDeiTModel
SEED = 42
LABELS = ['angry', 'happy', 'sad']
NLABELS = len(LABELS)
BATCH_SIZE = 32
SIZE = 256
EPOCHS = 20
LR = 5e-6 # default 0.001
HIDDEN_SIZE = 768 # default 768
NHEADS = 8 # default 12
NLAYERS = 4 # default 12
Dataset
train_directory = './dataset/Emotions Dataset/Emotions Dataset/train'
test_directory = './dataset/Emotions Dataset/Emotions Dataset/test'
train_dataset = image_dataset_from_directory(
train_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED,
interpolation='bilinear',
follow_links=False,
crop_to_aspect_ratio=False
)
# Found 6799 images belonging to 3 classes.
test_dataset = image_dataset_from_directory(
test_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED
)
# Found 2278 images belonging to 3 classes.
data_augmentation = Sequential([
RandomRotation(factor = (0.25),),
RandomFlip(mode='horizontal',),
RandomContrast(factor=0.1),
RandomBrightness(0.1)
])
resize_rescale_reshape = Sequential([
Resizing(SIZE, SIZE),
Rescaling(1./255),
# transformer expects image shape (3,224,224)
Permute((3,1,2))
])
training_dataset = (
train_dataset
.map(lambda image, label: (data_augmentation(image), label))
.prefetch(tf.data.AUTOTUNE)
)
testing_dataset = (
test_dataset.prefetch(
tf.data.AUTOTUNE
)
)
DeiT Model
# Initializing a ViT vit-base-patch16-224 style configuration
configuration = DeiTConfig(
image_size=SIZE,
hidden_size=HIDDEN_SIZE,
num_attention_heads=NHEADS,
num_hidden_layers=NLAYERS
)
# Initializing a model with random weights from the vit-base-patch16-224 style configuration
# base_model = TFViTModel(configuration)
# use pretrained weights for the model instead
base_model = TFDeiTModel.from_pretrained("facebook/deit-base-distilled-patch16-224", config=configuration)
# Accessing the model configuration
configuration = base_model.config
configuration
inputs = Input(shape=(256,256,3))
x = resize_rescale_reshape(inputs)
x = base_model.deit(x)[0][:,0,:]
output = Dense(NLABELS, activation='softmax')(x)
deit_model = Model(inputs=inputs, outputs=output)
deit_model.summary()
# testing the pretrained model
test_image = cv.imread('./dataset/angry.jpg')
test_image = cv.resize(test_image, (SIZE, SIZE))
deit_model(tf.expand_dims(test_image, axis = 0))
# numpy=array([[0.50628585, 0.13601433, 0.3576998 ]]
Model Training
loss_function = CategoricalCrossentropy()
metrics = [CategoricalAccuracy(name='accuracy'), TopKCategoricalAccuracy(k=2, name='topk_accuracy')]
deit_model.compile(
optimizer = Adam(learning_rate = LR),
loss = loss_function,
metrics = metrics
)
deit_history = deit_model.fit(
training_dataset,
validation_data = testing_dataset,
epochs = EPOCHS,
verbose = 1
)
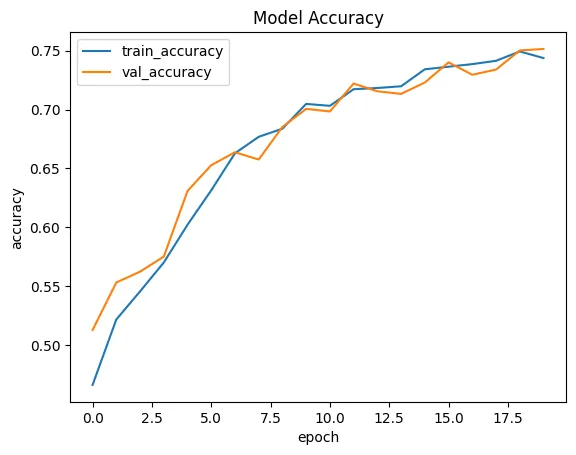
# loss: 0.5912
# accuracy: 0.7438
# topk_accuracy: 0.9226
# val_loss: 0.6060
# val_accuracy: 0.7515
# val_topk_accuracy: 0.9227
deit_model.evaluate(testing_dataset)
# loss: 0.6060 - accuracy: 0.7515 - topk_accuracy: 0.9227
plt.plot(deit_history.history['loss'])
plt.plot(deit_history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.savefig('assets/tf_Emotion_Detection_36.webp', bbox_inches='tight')

plt.plot(deit_history.history['accuracy'])
plt.plot(deit_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.savefig('assets/tf_Emotion_Detection_37.webp', bbox_inches='tight')
plt.figure(figsize=(16,16))
for images, labels in testing_dataset.take(1):
for i in range(16):
ax = plt.subplot(4,4,i+1)
true = "True: " + LABELS[tf.argmax(labels[i], axis=0).numpy()]
pred = "Predicted: " + LABELS[
tf.argmax(deit_model(tf.expand_dims(images[i], axis=0)).numpy(), axis=1).numpy()[0]
]
plt.title(
true + "\n" + pred
)
plt.imshow(images[i]/255.)
plt.axis('off')
plt.savefig('assets/tf_Emotion_Detection_38.webp', bbox_inches='tight')

y_pred = []
y_test = []
for img, label in testing_dataset:
y_pred.append(deit_model(img))
y_test.append(label.numpy())
conf_mtx = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(
np.argmax(y_test[:-1], axis=-1).flatten(),
np.argmax(y_pred[:-1], axis=-1).flatten()
),
display_labels=LABELS
)
fig, ax = plt.subplots(figsize=(16,12))
conf_mtx.plot(ax=ax, cmap='plasma', include_values=False)
plt.savefig('assets/tf_Emotion_Detection_39.webp', bbox_inches='tight')
