Tensorflow2 Model Zoo

What I am trying to do
I need to gain an understanding how different models and training steps affect the accuracy of the resulting model. Also gathering data in form of screen caps and labeling has a huge effect on the outcome of the training. Let' s see how this can be optimized.
Project Setup
I am using this Tensorflow Boilerplate. But instead of using an IP camera to film my hand and labeling hand gestures I now want to use screen caps from popular TV shows and label the characters depicted in that scene. With the exception of this change I am following the Tensorflow Tutorial and try to end up with a model that can tell me the character names when I show it a TV show.
Detection Models: Tensorflow provides a collection of detection models pre-trained on the COCO 2017 dataset. So far I have been using the SSD MobileNet V2 FPNLite 320x320. I will now replace it with the slightly slower but more accurate SSD MobileNet V2 FPNLite 640x640:
| Model name | Speed (ms) | COCO mAP | Outputs | | -- | -- | -- | -- | -- | -- | | SSD MobileNet V2 FPNLite 320x320 | 22 | 22.2 | Boxes | | SSD MobileNet V2 FPNLite 640x640 | 39 | 28.2 | Boxes |
ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8
INFO:tensorflow:Step 2000 per-step time 0.117s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.302
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.449
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.401
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.318
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.629
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.679
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.679
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.679
After 2000 steps I only got a few positive recognitions. All of them were from one label. In general the result was pretty bad... So another 3000 steps on top:
INFO:tensorflow:Step 3000 per-step time 0.123s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.486
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.669
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.604
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.488
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.707
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.721
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.721
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.721
This greatly increased the metrics above. But I still ran into the issue that only one of my labels was being recognized - Captain Jean-Luc Picard. The model also seemed to be obsessed with hair styles. Evaluating them higher than facial features...

Expanding the ROI
Which is interesting because during labeling he was the only character where I choose to make the entire head ROI. For the others I used a region of interest centered on their face to prevent the model from over-emphasizing their hair cut... so now I went back to labeling and corrected this - potential - mistake:

Now I re-ran the 3000 steps and already here I am getting a much better result:
INFO:tensorflow:Step 3000 per-step time 0.117s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.436
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.576
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.478
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.436
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.793
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.793
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.793
I now also found an image that tested - correctly - positive for another label. But I also lost a couple of detection that worked before:

So let's re-run the training and add another 10.000 steps to see if this makes a difference:
INFO:tensorflow:Step 10000 per-step time 0.125s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.473
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.558
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.558
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.473
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.831
What I am noticing here is that the Recall value greatly benefits from the training. But there is almost no increase in Precision:
- Precision: True Positive / (True Positive + False Positive)
- Recall: True Positive / (True PMost are still undetected.
This must be because the recognition in general is terrible - I am getting almost no recognitions false or positive. But if there is a hit it is almost always good. So why doesn't this work? It might be that the 320x320 image resolution is not sufficient for the training. So let's try using the higher one and see how this changes the evaluation:
| Model name | Speed (ms) | COCO mAP | Outputs | | -- | -- | -- | -- | -- | -- | | SSD MobileNet V2 FPNLite 320x320 | 22 | 22.2 | Boxes | | SSD MobileNet V2 FPNLite 640x640 | 39 | 28.2 | Boxes |
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
INFO:tensorflow:Step 2000 per-step time 0.439s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.234
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.372
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.283
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.234
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.512
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.595
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.595
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.595
INFO:tensorflow:Step 11000 per-step time 0.468s
Oh, I noticed a mistake here. I thought the steps for a new run will be added to the already run steps. But by rerunning the command with 11.000 steps I ended up at 11.000 and not 13.000 as I expected. So I am now comparing 10.000 steps for the 320 model with 11.000 steps for the 640 model
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.474
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.559
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.548
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.484
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.729
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.786
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.786
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.786
| Model name | AP (2000 steps) | AR (2000 steps) | AP (10000 steps) | AR (10000 steps) |
|---|---|---|---|---|
| SSD MobileNet V2 FPNLite 320x320 | 0.302 | 0.679 | 0.558 | 0.831 |
| SSD MobileNet V2 FPNLite 640x640 | 0.234 | 0.595 | 0.548 | 0.786 |
So the 640 performed a worse at 2000 steps but almost got the the same level as the 320 model at 11.000 steps. But given the long training time this is a bit underwhelming. Going through the images - the detection rate did not even get that much better.
Letting the training running over night to get up to 90.000 steps
INFO:tensorflow:Step 90000 per-step time 0.432s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.243
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.328
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.263
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.244
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.560
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.683
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.683
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.683
And taking a look at the results from a 20.000 (left) steps training and the end result at 90.000 (right). For all labels that already performed (at least a little bit) I can see an improvement in confidence. There have also been a few new hits (correct and false). But overall the training did lead to a more accurate model:






Labeling Done Right!
Ok, I think I figured it out. And it is pretty obvious now... Since I collected separate images for each label (character) I ended up only labeling on person per image - even if there was a group of them in there. This must have caused my model a lot of frustration due to false false-positive every time it recognized something correctly that wasn't labeled ... So now I went through my stash of images and re-did the labeling part - this time adding multiple labels to each image (where appropriated):
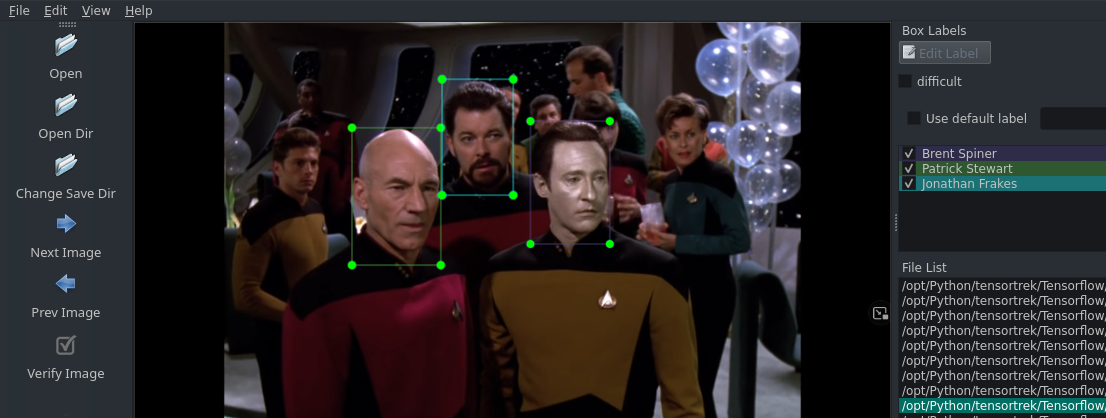
I deleted the trained model and re-run the training. I am getting a much better result - already, after only 10.000 steps:
INFO:tensorflow:Step 10000 per-step time 0.431s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.804
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.976
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.808
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.819
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.824
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.828
And the detections follow suit - so I added another 10.000 steps and saw a slight decrease in numbers:
INFO:tensorflow:Step 20000 per-step time 0.454s
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.798
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.803
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.820
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.820
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.820
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.824

And again I am surprised - while the detection rate for some labels stayed the same, it rose to the high nineties for others. While dropping blow 50% confidence where the detection rate was high before:

The next steps would be to replace the trainings images of badly performing labels with higher quality ones. And in general add more, diverse trainings images for all labels and keep running trainings until the improvements start to level out.