Related:
- Image Segmentation with PyTorch
- Semantic Segmentation Detectron2 Model Zoo
- Semantic Segmentation Detectron2 Model Zoo: Faster RCNN
- Semantic Segmentation Detectron2 Model Zoo: Mask RCNN
- Detectron Object Detection with OpenImages Dataset (WIP)
Image Segmentation with PyTorch
- Tray Food Segmentation: Food item segmentation from images of trays
- Meal-Compliance-Project
Creating Label Annotations
!pip install matplotlib opencv-python albumentations tqdm
!pip install git+https://github.com/qubvel/segmentation_models.pytorch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.optim import lr_scheduler
import segmentation_models_pytorch as smp
import torchvision
from torchvision import datasets, models, transforms
import albumentations as albu
import matplotlib.pyplot as plt
import numpy as np
import os
from helper.metrics import IoU, Accuracy, Fscore, Recall, Precision, DiceLoss
from helper.train import BaseDataset, VisualizeDataset, VisualizeResult, TestEpoch, TrainEpoch
LR = 0.0001
DLR_STEPS = 7
DLR_GAMMA = 0.1
EPOCHS = 20
MODEL_PATH = '../../saved_models/MobileNetV3Encoder_UnetPlusPlus.pth'
DATA_DIR = '../../dataset/TrayDataset/'
BATCH = 8
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Dataset
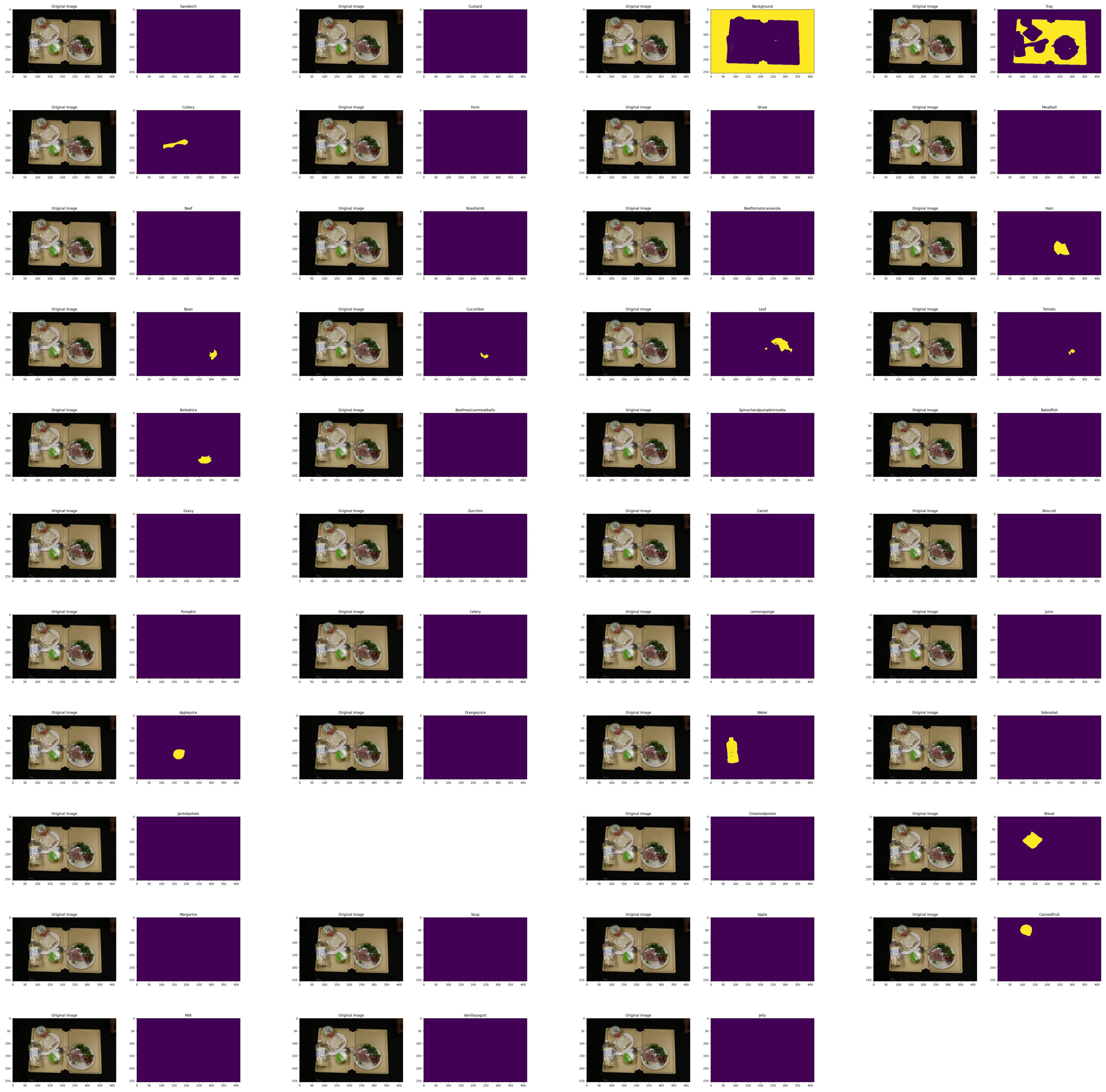
CLASS_LABELS = ['background','tray','cutlery','form','straw','meatball','beef','roastlamb','beeftomatocasserole','ham','bean','cucumber','leaf','tomato','boiledrice','beefmexicanmeatballs','spinachandpumpkinrisotto','bakedfish','gravy','zucchini','carrot','broccoli','pumpkin','celery','sandwich','sidesalad','tartaresauce','jacketpotato','creamedpotato','bread','margarine','soup','apple','cannedfruit','milk','vanillayogurt','jelly','custard','lemonsponge','juice','applejuice','orangejuice','water']
len(CLASS_LABELS)
CLASS_COLOUR_MAP = np.array([
(0, 0, 0), (100, 127, 150),(50, 0, 0),(0, 0, 255),(100, 0, 0),(0, 100, 0),
(0, 100, 0),(0, 50, 50),(50, 100, 0),(0, 250, 0),(180, 0, 0),
(100, 100, 0),(128, 0, 100),(100, 128, 0),(0, 100, 128),(100, 0, 100),
(150, 100, 0),(0, 100, 200), (100, 50, 50),(50, 100, 250),(100, 250, 50),(180, 100, 0),
(100, 50, 218),(200, 128, 100),(100, 0, 128),(10, 100, 128),(100, 150, 75),
(175, 100, 90),(30, 100, 128),(100, 250, 125),(50, 10, 50), (175, 10, 175),(25, 225, 50),
(100, 128, 218),(128, 0, 100),(128, 128, 0),(90, 100, 0),(100, 200, 0),(175, 100, 150),
(200, 100, 200),(200, 50, 50),(250, 100, 50),(100, 25, 50),(150, 100, 100)
])
x_train_dir = os.path.join(DATA_DIR, 'XTrain')
y_train_dir = os.path.join(DATA_DIR, 'yTrain')
x_test_dir = os.path.join(DATA_DIR, 'XTest')
y_test_dir = os.path.join(DATA_DIR, 'yTest')
path, dirs, files = next(os.walk(x_train_dir))
file_count = len(files)
print('Test Dataset: ',file_count)
Test Dataset: 1241
path, dirs, files = next(os.walk(x_test_dir))
file_count = len(files)
print('Training Dataset: ',file_count)
Training Dataset: 8
Preparing the Dataset
Dataset Visualization
for label in CLASS_LABELS:
dataset = BaseDataset(x_test_dir, y_test_dir, classes=[label])
image, mask = dataset[2]
VisualizeDataset(
image = image, mask=mask.squeeze(),
label = label
)
/opt/app/notebook/MobileNetV3Encoder_UnetPlusPlus/helper/train.py:20: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (matplotlib.pyplot.figure) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam figure.max_open_warning). Consider using matplotlib.pyplot.close().
plt.figure(figsize=(14, 20))
Data Augmentation
def apply_train_aug():
train_transform = [
# apply to all
albu.Resize(256, 416, p=1),
# apply to 50% of images
albu.HorizontalFlip(p=0.5),
# apply one randomly to 90% of images
albu.OneOf([
albu.RandomBrightnessContrast(
brightness_limit=0.4, contrast_limit=0.4, p=1),
albu.CLAHE(p=1),
albu.HueSaturationValue(p=1)
], p=0.9,),
# add noise to 20% of images
albu.GaussNoise(var_limit=(10.0, 50.0), mean=0, per_channel=True, always_apply=False, p=0.2),
]
return albu.Compose(train_transform)
def apply_test_aug():
"""Add paddings to make image shape divisible by 32"""
test_transform = [
albu.PadIfNeeded(256, 416)
]
return albu.Compose(test_transform)
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
def apply_preprocessing(preprocessing_fn):
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
Visualize Augmented Data
train_dataset = BaseDataset(
x_train_dir,
y_train_dir,
augmentation=apply_train_aug(),
classes=['tray'],
)
test_dataset = BaseDataset(
x_test_dir,
y_test_dir,
augmentation=apply_test_aug(),
classes=['tray'],
)
# show image with 5 different augmentations
for i in range(5):
image, mask = train_dataset[8]
VisualizeResult(image=image, mask=mask.squeeze(-1))

Data Loading
train_loader = DataLoader(
train_dataset,
batch_size=BATCH,
shuffle=True,
num_workers=0)
test_loader = DataLoader(
test_dataset,
batch_size=1,
shuffle=False,
num_workers=0)
Performance Metrics
-
Intersection-over-Union (IOU): Calculated from the overlap of the ground truth and predicted area divided by the overall area of both:
(Area of Overlap) / (Area of Union) -
Mean-Intersection-over-Union (mIOU): Mean IOU over all classes.
metrics = [
IoU(threshold=0.5),
Accuracy(threshold=0.5),
Fscore(threshold=0.5),
Recall(threshold=0.5),
Precision(threshold=0.5),
]
Building the Segmentation Model
# https://github.com/qubvel/segmentation_models.pytorch
# resnet50, resnext50_32x4d, resnext101_32x8d, xception, timm-gernet_s, mobileone_s0, timm-efficientnet-b0, timm-mobilenetv3_small_100, resnet152, vgg13
ENCODER = 'timm-mobilenetv3_small_100'
ENCODER_WEIGHTS = 'imagenet'
ACTIVATION = 'softmax'
# https://github.com/qubvel/segmentation_models.pytorch/tree/master/segmentation_models_pytorch/decoders
# FPN, PAN, PSPNet, MAnet, Linknet, FPN, DeepLabV3, DeepLabV3Plus, Unet
model = smp.UnetPlusPlus(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASS_LABELS),
activation=ACTIVATION,
)
#Normalize your data the same way as during encoder weight pre-training
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
print(model)
# Define Optimization algorithm with Learning rate
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=LR),
])
# Define Loss Function
loss = DiceLoss()
Data Loader
train_dataset = BaseDataset(
x_train_dir,
y_train_dir,
augmentation=apply_train_aug(),
preprocessing=apply_preprocessing(preprocessing_fn),
classes=CLASS_LABELS,
)
test_dataset = BaseDataset(
x_test_dir,
y_test_dir,
augmentation=apply_test_aug(),
preprocessing=apply_preprocessing(preprocessing_fn),
classes=CLASS_LABELS,
)
train_loader = DataLoader(train_dataset, batch_size=BATCH, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=0)
Model Training
train_epoch = TrainEpoch(
model,
loss=loss,
metrics=metrics,
optimizer=optimizer,
device=DEVICE,
verbose=True,
)
test_epoch = TestEpoch(
model,
loss=loss,
metrics=metrics,
device=DEVICE,
verbose=True,
)
max_score = 0
for i in range(0, 40):
print('\nEpoch: {}'.format(i))
train_logs = train_epoch.run(train_loader)
test_logs = test_epoch.run(test_loader)
# Save the model with best iou score
if max_score < test_logs['iou_score']:
max_score = test_logs['iou_score']
torch.save(model, MODEL_PATH)
print('Model saved!')
if i == 50:
optimizer.param_groups[0]['lr'] = 1e-5
print('Decrease decoder learning rate to 1e-5!')
Epoch: 39 train: 100%|█| 156/156 [06:10, 2.37s/it, dice_loss - 0.03158, iou_score - 0.9396, accuracy - 0.9985, fscore - 0.9688, recall - 0.9686, precision test: 100%|█| 8/8 [00:01, 4.94it/s, dice_loss - 0.04502, iou_score - 0.9164, accuracy - 0.9979, fscore - 0.9555, recall - 0.9552, precision - 0.
Model Evaluation
trained_model = torch.load(MODEL_PATH)
logs = test_epoch.run(test_loader)
test: 12%|▏| 1/8 [00:0215, 2.16s/it, dice_loss - 0.03128, iou_score - 0.9401, accuracy - 0.9986, fscore - 0.9691, recall - 0.9689, precision - 0.
/opt/conda/lib/python3.10/site-packages/segmentation_models_pytorch/base/modules.py:116: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument. return self.activation(x)
test: 100%|█| 8/8 [00:0300, 2.27it/s, dice_loss - 0.04451, iou_score - 0.9178, accuracy - 0.998, fscore - 0.9563, recall - 0.9558, precision - 0.9
test: 100%|█| 8/8 [00:0100, 4.21it/s, dice_loss - 0.2597, iou_score - 0.8069, accuracy - 0.9953, fscore - 0.8928, recall - 0.839, precision - 0.95
Visualize Segmentation
#Get orignial image and mask from test dataset
image, gt_mask = test_dataset[3]
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
predicted_mask = trained_model.predict(x_tensor)
pr_mask = (predicted_mask.squeeze().cpu().numpy().round())
pr_mask = pr_mask[1,:,:]
gt_mask = gt_mask[1,:,:]
image_t = image.transpose(1, 2, 0)
VisualizeResult(
image=image_t,
ground_truth_mask=gt_mask,
predicted_mask=pr_mask
)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

#Convert the predicted mask to numpy and get the predicted class indices
predicted_output = torch.argmax(predicted_mask.squeeze(), dim=0).detach().cpu().numpy()
indices = np.unique(predicted_output)
for i in indices:
print(CLASS_LABELS[i])
background tray cutlery boiledrice beefmexicanmeatballs zucchini pumpkin water
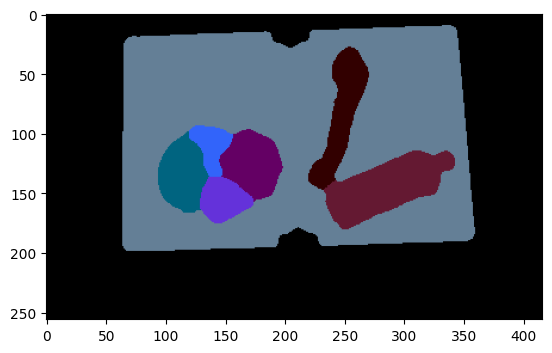
Predicted Segmentation Map
# Define function to convert 2D segmentation to RGB Image
def decode_segmentation_map(image, classesLength=43):
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
for l in range(0, classesLength):
idx = image == l
r[idx] = CLASS_COLOUR_MAP[l, 0]
g[idx] = CLASS_COLOUR_MAP[l, 1]
b[idx] = CLASS_COLOUR_MAP[l, 2]
rgb = np.stack([r, g, b], axis=2)
return rgb
rgb_map = decode_segmentation_map(predicted_output,43)
plt.imshow(rgb_map);