Yolo App - Train a Model with Tensorflow

- Prepare your Images and get Data
- Train your Tensorflow Model
- Use your Model to do Predictions
- Use Tesseract to Read Number Plates
- Flask Web Application
- Yolo v5 - Data Prep
Prepare the Neural Network
When running the following code I kept getting this warning:
Memory Error in Tensorflow:
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:936] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
Running the following command from my console to set each device to 0 got rid of the warning:
for a in /sys/bus/pci/devices/*; do echo 0 | sudo tee -a $a/numa_node; done
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2, InceptionV3, InceptionResNetV2
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.models import Model
# Inception ResNet for 224x224 3-channel image source
inception_resnet = InceptionResNetV2(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
inception_resnet.trainable=False
headmodel = inception_resnet.output
headmodel = Flatten()(headmodel)
# Build neural network layers
headmodel = Dense(500,activation='relu')(headmodel)
headmodel = Dense(250,activation='relu')(headmodel)
headmodel = Dense(4, activation='sigmoid')(headmodel)
# Define inputs / outputs for your model
model = Model(inception_resnet.input, outputs=headmodel)
# Compile the model
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4))
2022-03-05 16:55:55.576063: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 4607 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1060 6GB, pci bus id: 0000:01:00.0, compute capability: 6.1
Train your Model
from tensorflow.keras.callbacks import TensorBoard
tfb = TensorBoard('object_detection')
history = model.fit(x=x_train, y=y_train, batch_size=10, epochs=100, validation_data=(x_test, y_test), callbacks=[tfb])
With tensorflow-gpu on an Nvidia GTX 1060 I am getting training cycles of 2-3s:
Epoch 1/100
2022-03-05 17:44:41.082245: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8301
18/18 [==============================] - 13s 289ms/step - loss: 0.1179 - val_loss: 0.1214
Epoch 2/100
18/18 [==============================] - 2s 128ms/step - loss: 0.1204 - val_loss: 0.1146
Epoch 3/100
18/18 [==============================] - 2s 129ms/step - loss: 0.1223 - val_loss: 0.1235
...
Epoch 499/500
20/20 [==============================] - 3s 136ms/step - loss: 3.2455e-05 - val_loss: 0.0042
Epoch 500/500
20/20 [==============================] - 3s 137ms/step - loss: 2.7786e-05 - val_loss: 0.0042
To save the model run:
model.save('../models/object_detection.h5')
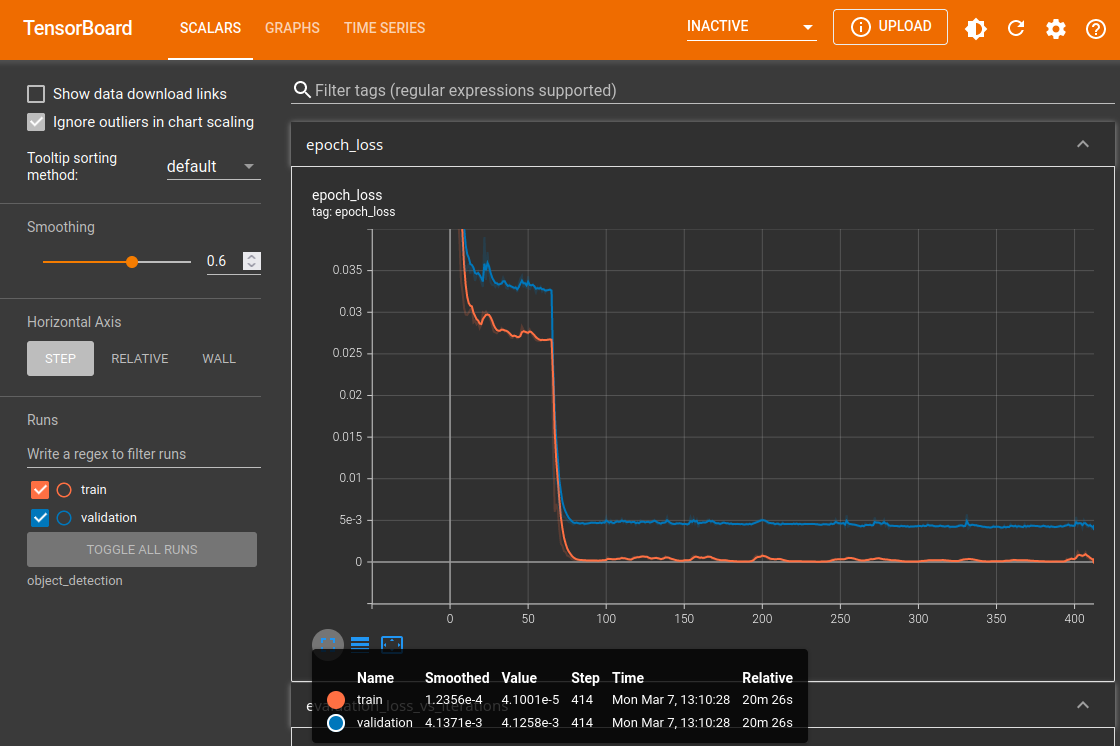
I can use Tensorboard to check the results - run the following command from your console and point it to your training data folder:
tensorboard --logdir=object_detection
TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit)