
See also:
- Fun, fun, tensors: Tensor Constants, Variables and Attributes, Tensor Indexing, Expanding and Manipulations, Matrix multiplications, Squeeze, One-hot and Numpy
- Tensorflow 2 - Neural Network Regression: Building a Regression Model, Model Evaluation, Model Optimization, Working with a "Real" Dataset, Feature Scaling
- Tensorflow 2 - Neural Network Classification: Non-linear Data and Activation Functions, Model Evaluation and Performance Improvement, Multiclass Classification Problems
- Tensorflow 2 - Convolutional Neural Networks: Binary Image Classification, Multiclass Image Classification
- Tensorflow 2 - Transfer Learning: Feature Extraction, Fine-Tuning, Scaling
- Tensorflow 2 - Unsupervised Learning: Autoencoder Feature Detection, Autoencoder Super-Resolution, Generative Adverserial Networks
Tensorflow Neural Network Regression
Optimizing Model Performance
Get more data
# create a new feature matrix
X = tf.range(-1000, 1000, 4)
# create labels for those features that follow a pattern
y = X + 10
len(X)
# 500 => 80:20 split = 400:100
# to get around biases it is better to shuffle your data
# first create random indices to be able to shuffle
# both features and lables by the same order
indices = tf.range(start=0, limit=tf.shape(X)[0], dtype=tf.int32)
shuffled_indices = tf.random.shuffle(indices)
# use random indices to shuffle both tensors
X_random = tf.gather(X, shuffled_indices)
y_random = tf.gather(y, shuffled_indices)
# re-split
X_train = X_random[:400] # take first 80% of features
X_test = X_random[400:] # take last 20% of features
y_train = y_random[:400] # take first 80% of lables
y_test = y_random[400:] # take last 20% of lables
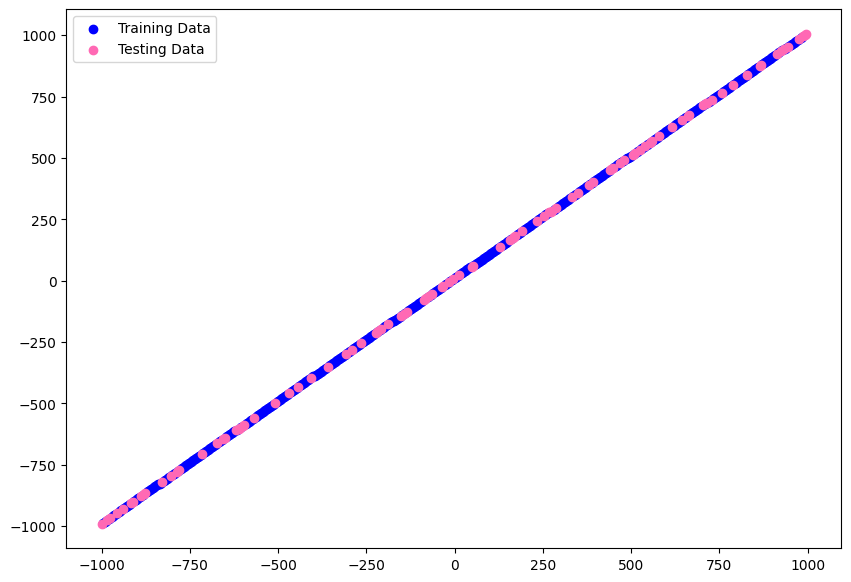
# visualize datasets
plt.figure(figsize=(10,7))
plt.scatter(X_train, y_train, color="blue", label="Training Data")
plt.scatter(X_test, y_test, color="hotpink", label="Testing Data")
plt.legend()
Add Model Complexity
model_1- longer training 200 epochsmodel_2- add another dense layermodel_3- add another dropout layermodel_4- same as model above but trained for 500 epochs- ... take the best model and reduce complexity to find an optimum
model_1
# longer training 200 epochs
model_1 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(128, activation="relu", name="dense_layer1"),
layers.Dropout(.25, name="dropout"),
layers.Dense(64, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="my_model_1")
model_1.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
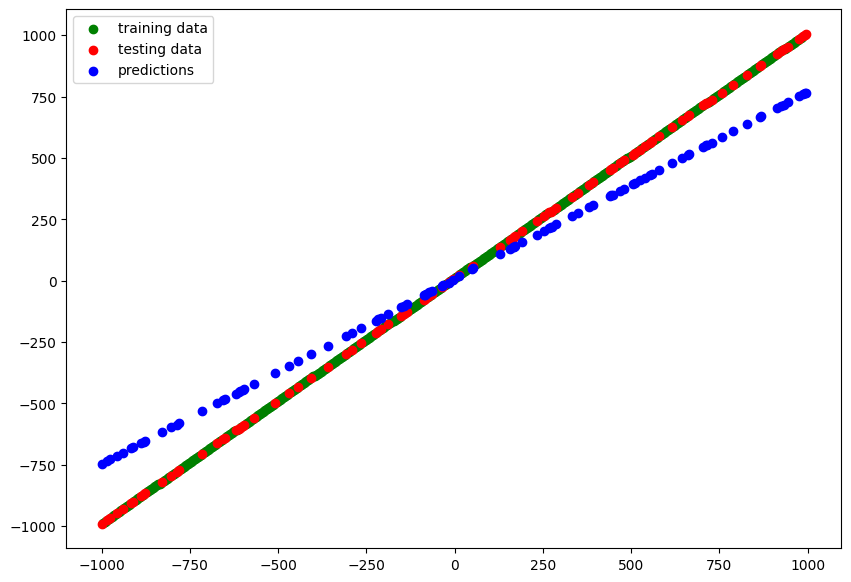
model_1.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=200)
# Epoch 200/200
# 13/13 [==============================] - 0s 5ms/step - loss: 10.6268 - mae: 10.6268 - val_loss: 122.6467 - val_mae: 122.6467
y_pred_1 = model_1.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_1)
model_2
# add another dense layer
model_2 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(128, activation="relu", name="dense_layer1"),
layers.Dropout(.25, name="dropout"),
layers.Dense(64, activation="relu", name="dense_layer2"),
layers.Dense(32, activation="relu", name="dense_layer3"),
layers.Dense(1, name="output_layer")
], name="my_model_2")
model_2.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
model_2.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100)
# Epoch 100/100
# 13/13 [==============================] - 0s 5ms/step - loss: 31.7044 - mae: 31.7044 - val_loss: 10.8619 - val_mae: 10.8619
y_pred_2 = model_2.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_2)
model_3
# add another dropout layer
model_3 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(128, activation="relu", name="dense_layer1"),
layers.Dropout(.25, name="dropout1"),
layers.Dense(64, activation="relu", name="dense_layer2"),
layers.Dropout(.25, name="dropout2"),
layers.Dense(32, activation="relu", name="dense_layer3"),
layers.Dense(1, name="output_layer")
], name="my_model_3")
model_3.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
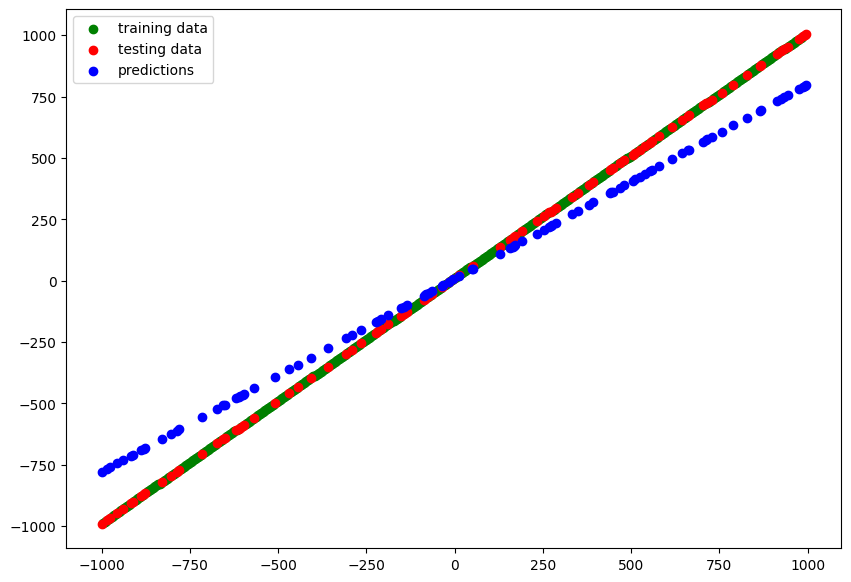
model_3.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100)
# Epoch 100/100
# 13/13 [==============================] - 0s 5ms/step - loss: 44.1139 - mae: 44.1139 - val_loss: 107.2299 - val_mae: 107.2299
y_pred_3 = model_3.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_3)
model_4
# same as model above but trained for 500 epochs
model_4 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(128, activation="relu", name="dense_layer1"),
layers.Dropout(.25, name="dropout1"),
layers.Dense(64, activation="relu", name="dense_layer2"),
layers.Dropout(.25, name="dropout2"),
layers.Dense(32, activation="relu", name="dense_layer3"),
layers.Dense(1, name="output_layer")
], name="my_model_4")
model_4.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.01),
metrics="mae")
model_4.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# Epoch 500/500
# 13/13 [==============================] - 0s 5ms/step - loss: 38.3689 - mae: 38.3689 - val_loss: 143.9144 - val_mae: 143.9144
y_pred_4 = model_4.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_4)
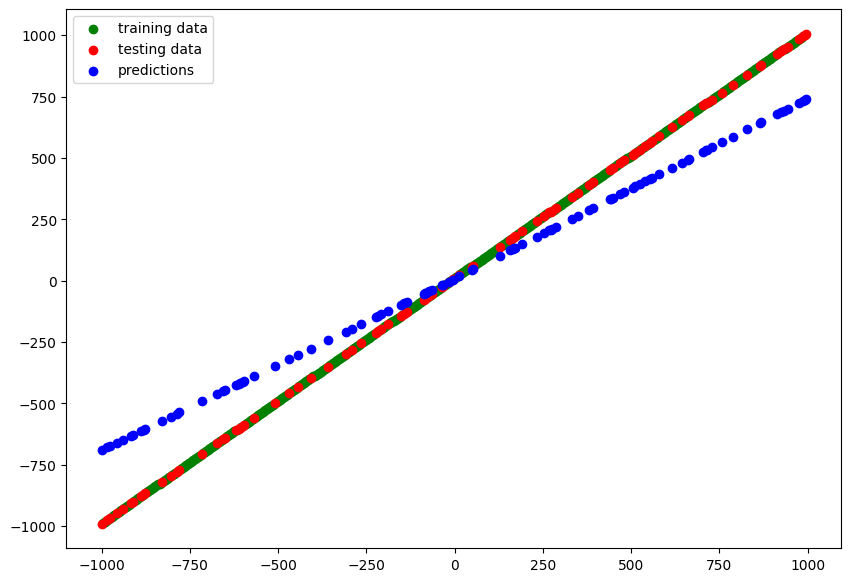
model_5
# I am getting the best results with `model_2`
# but a 2nd dropout layer seems to reduce the performance
# let's remove the 1st dropout
model_5 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(128, activation="relu", name="dense_layer1"),
layers.Dense(64, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="my_model_5")
model_5.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.001),
metrics="mae")
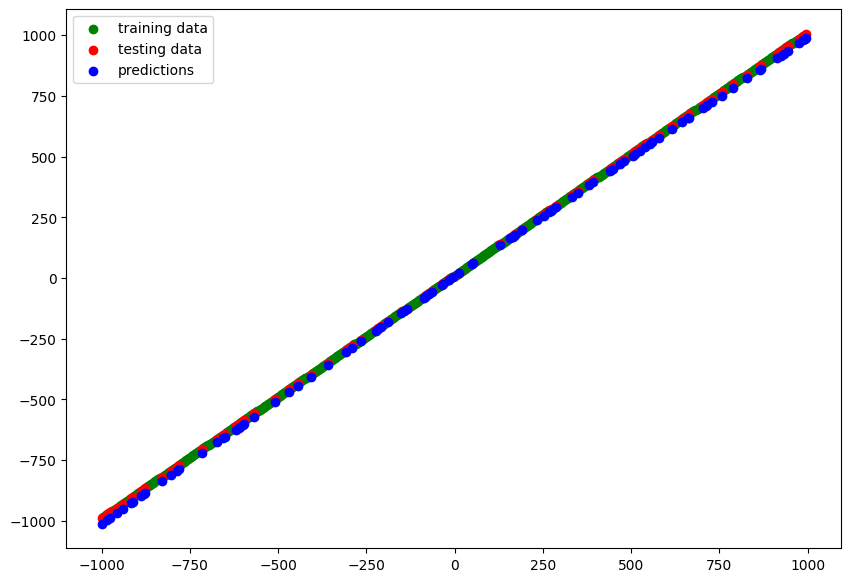
model_5.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100)
# Epoch 100/100
# 13/13 [==============================] - 0s 4ms/step - loss: 2.1195 - mae: 2.1195 - val_loss: 2.9318 - val_mae: 2.9318
y_pred_5 = model_5.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_5)
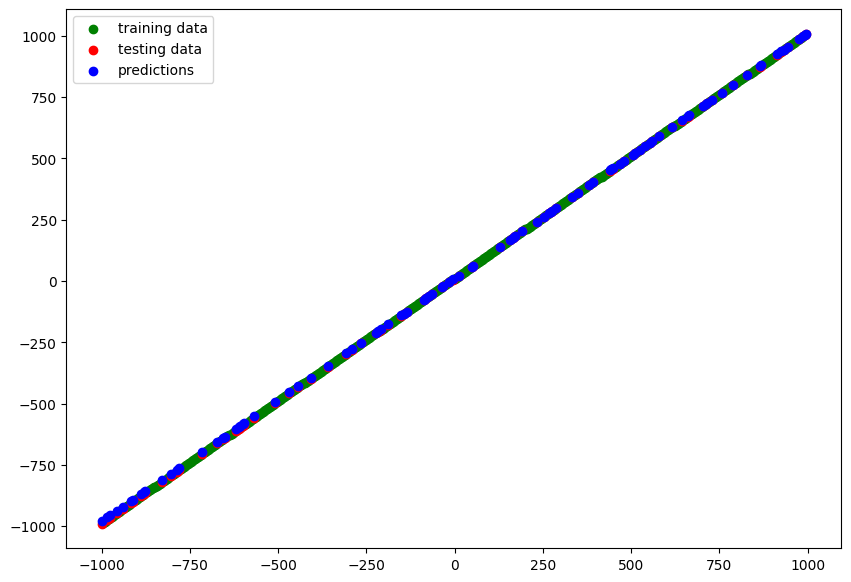
model_6
# same as above - based on `model_2`
# but more complexity removed
model_6 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(64, activation="relu", name="dense_layer1"),
layers.Dense(32, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="my_model_6")
model_6.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.001),
metrics="mae")
model_6.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100)
# Epoch 100/100
# 13/13 [==============================] - 0s 5ms/step - loss: 1.9283 - mae: 1.9283 - val_loss: 2.0062 - val_mae: 2.0062
y_pred_6 = model_6.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_6)
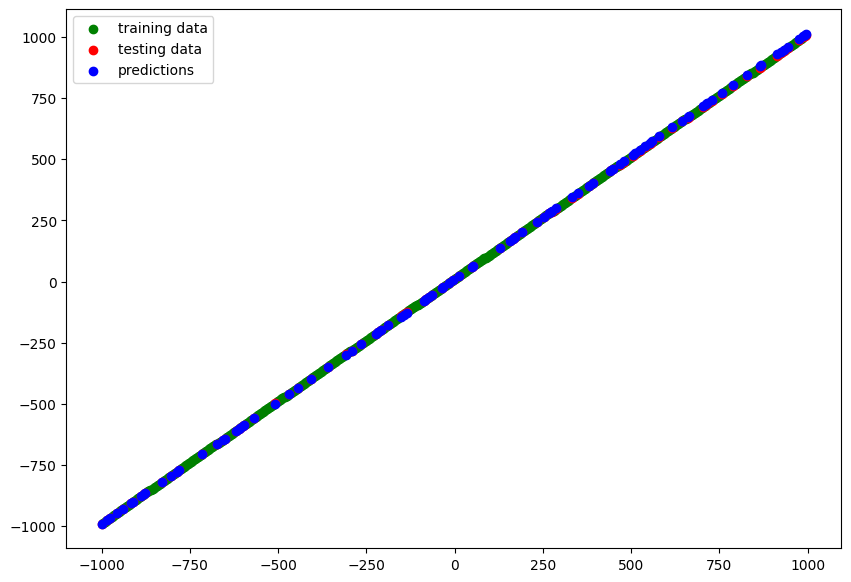
model_7
# same as above - based on `model_2`
# but even more complexity removed
model_7 = tf.keras.Sequential([
layers.Dense(1, input_shape=[1], name="input_layer"),
layers.Dense(16, activation="relu", name="dense_layer1"),
layers.Dense(8, activation="relu", name="dense_layer2"),
layers.Dense(1, name="output_layer")
], name="my_model_6")
model_7.compile(
loss=tf.keras.losses.mae,
optimizer=optimizers.Adam(learning_rate=0.001),
metrics="mae")
# increased epochs 100 -> 500
model_7.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=500)
# Epoch 500/500
# 13/13 [==============================] - 0s 5ms/step - loss: 0.6490 - mae: 0.6490 - val_loss: 0.9975 - val_mae: 0.9975
y_pred_7 = model_7.predict(X_test)
# blue dots should line up with red dots for a perfect prediction
plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=y_pred_7)
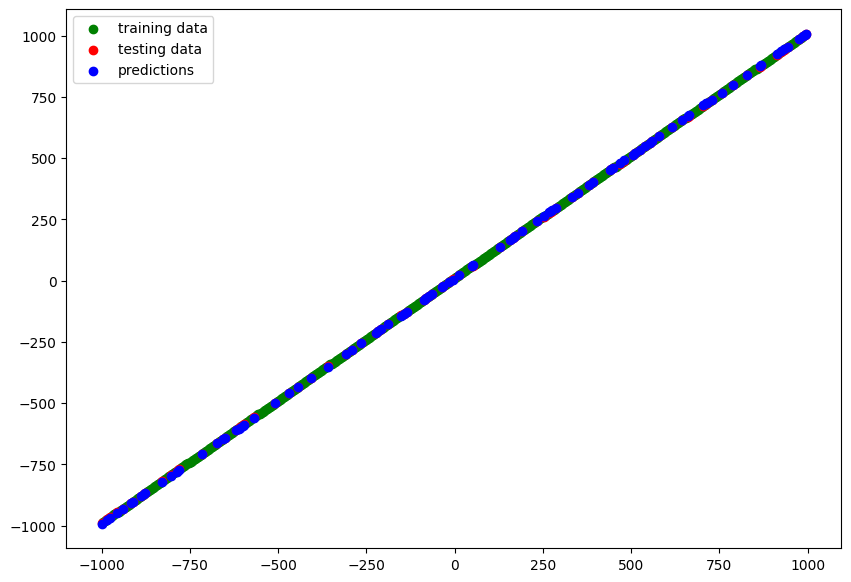
Comparing Experiments
# function to calculate mae & mse
def squared_and_absolute_error(y_true, y_pred):
mae = tf.metrics.mean_absolute_error(y_true, tf.squeeze(y_pred))
mse = tf.metrics.mean_squared_error(y_true, tf.squeeze(y_pred))
return mae.numpy(), mse.numpy()
# calculate errors for all models
model_1_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_1)
model_2_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_2)
model_3_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_3)
model_4_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_4)
model_5_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_5)
model_6_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_6)
model_7_err = squared_and_absolute_error(y_true=y_test, y_pred=y_pred_7)
model_err = [["model_1", model_1_err[0], model_1_err[1]],
["model_2", model_2_err[0], model_2_err[1]],
["model_3", model_3_err[0], model_3_err[1]],
["model_4", model_4_err[0], model_4_err[1]],
["model_5", model_5_err[0], model_5_err[1]],
["model_6", model_6_err[0], model_6_err[1]],
["model_7", model_7_err[0], model_7_err[1]]]
result_table = pd.DataFrame(model_err, columns=["model", "mae", "mse"])
# sort results by lowest error
result_table.sort_values(by=['mae'])
| model | mae | mse |
|---|---|---|
| model_7 | 1.144104 | 1.818071 |
| model_6 | 1.684225 | 3.257224 |
| model_5 | 2.049126 | 5.940683 |
| model_2 | 49.432564 | 3300.268799 |
| model_4 | 100.509567 | 14063.405273 |
| model_3 | 102.297127 | 14211.152344 |
| model_1 | 121.414032 | 20278.529297 |
# the best performing model is `model_7`
model_7.summary()
# Model: "my_model_6"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_layer (Dense) (None, 1) 2
# dense_layer1 (Dense) (None, 16) 32
# dense_layer2 (Dense) (None, 8) 136
# output_layer (Dense) (None, 1) 9
# =================================================================
# Total params: 179
# Trainable params: 179
# Non-trainable params: 0
# _________________________________________________________________
Saving the Trained Models
SavedModelformat (default)HDF5format (easier to transfer outside of TF)
# assign location
path='saved_models/SavedModel_Format'
# saving to SavedModel
model_7.save(path)
# assign location
path_hdf5='saved_models/hdf5_format.h5'
# saving to HDF5
model_7.save(path_hdf5)
Restoring a Saved Model
loaded_SavedModel = tf.keras.models.load_model(path)
# Verify that it is the correct model
loaded_SavedModel.summary()
# Model: "my_model_6"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_layer (Dense) (None, 1) 2
# dense_layer1 (Dense) (None, 16) 32
# dense_layer2 (Dense) (None, 8) 136
# output_layer (Dense) (None, 1) 9
# =================================================================
# Total params: 179
# Trainable params: 179
# Non-trainable params: 0
# _________________________________________________________________
# make a prediction with the restored model
# lets find a value pair from the test dataset
X_test[66], y_test[66]
# (<tf.Tensor: shape=(), dtype=int32, numpy=-944>,
# <tf.Tensor: shape=(), dtype=int32, numpy=-934>)
# So for a feature value of `-944` we should receive a label value of `-943`
# run prediction
loaded_SavedModel.predict([-944])
# array([[-936.5761]], dtype=float32)
loaded_HDF5Model = tf.keras.models.load_model(path_hdf5)
# Verify that it is the correct model
loaded_HDF5Model.summary()
# Model: "my_model_6"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_layer (Dense) (None, 1) 2
# dense_layer1 (Dense) (None, 16) 32
# dense_layer2 (Dense) (None, 8) 136
# output_layer (Dense) (None, 1) 9
# =================================================================
# Total params: 179
# Trainable params: 179
# Non-trainable params: 0
# _________________________________________________________________
# run prediction
loaded_HDF5Model.predict([-944])
# array([[-936.5761]], dtype=float32)
# the result is identical to the result we get from
# the restored SavedModel format model
model_7.predict([-944]) == loaded_SavedModel.predict([-944]) == loaded_HDF5Model.predict([-944])
# array([[ True]])
# the restored models predict the identical values