
Tf Image Classifier
Vision Transformer
"The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224."
This is using the same transformer as before - but is now pre-trained on a large dataset. Let's see if this can beat the results I received from the not-pre-trained ViT before:
loss: 0.9803 - accuracy: 0.5443 - topk_accuracy: 0.8090(self-build: num_attention_heads=4,num_hidden_layers=2, hidden_size=144)loss: 0.9404 - accuracy: 0.5610 - topk_accuracy: 0.8385(hf model: num_attention_heads=4,num_hidden_layers=2, hidden_size=144)loss: 0.9572 - accuracy: 0.5399 - topk_accuracy: 0.8306(hf model: num_attention_heads=8,num_hidden_layers=4, hidden_size=144)loss: 1.0289 - accuracy: 0.5000 - topk_accuracy: 0.7761(hf model: num_attention_heads=8,num_hidden_layers=4, hidden_size=768)- The accuracy here is lower - but I massively reduced the learning rate and the accuracy was still rising steadily
loss: 0.5340 - accuracy: 0.7730 - topk_accuracy: 0.9315(hf model with pre-trained weights: num_attention_heads=8,num_hidden_layers=4, hidden_size=768)loss: 0.4596 - accuracy: 0.8068 - topk_accuracy: 0.9495(re-run as above with 40 instead of 20 epochs)
For the training with pretrained weights I increased the learning-rate again by a factor of 10. But I had to down-configure the model to prevent out-of-memory errors (configuration as seen below). So there is still room to improve the results on better hardware and with some tinkering. Still - this pre-trained model performs significantly better than the untrained transformer and already comes close to rival the CNN solution (MobileNetV3Small) used before:
loss: 0.3906 - accuracy: 0.8455 - topk_accuracy: 0.9627- MobileNetV3Small as reference
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
!pip install transformers
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay)
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import (
Conv2D,
BatchNormalization,
LayerNormalization,
Dense,
Input,
Embedding,
MultiHeadAttention,
Layer,
Add,
Resizing,
Rescaling,
Permute,
Flatten,
RandomFlip,
RandomRotation,
RandomContrast,
RandomBrightness
)
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import CategoricalAccuracy, TopKCategoricalAccuracy
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import image_dataset_from_directory
from transformers import ViTConfig, ViTModel, AutoImageProcessor, TFViTModel
SEED = 42
LABELS = ['Gladiolus', 'Adenium', 'Alpinia_Purpurata', 'Alstroemeria', 'Amaryllis', 'Anthurium_Andraeanum', 'Antirrhinum', 'Aquilegia', 'Billbergia_Pyramidalis', 'Cattleya', 'Cirsium', 'Coccinia_Grandis', 'Crocus', 'Cyclamen', 'Dahlia', 'Datura_Metel', 'Dianthus_Barbatus', 'Digitalis', 'Echinacea_Purpurea', 'Echinops_Bannaticus', 'Fritillaria_Meleagris', 'Gaura', 'Gazania', 'Gerbera', 'Guzmania', 'Helianthus_Annuus', 'Iris_Pseudacorus', 'Leucanthemum', 'Malvaceae', 'Narcissus_Pseudonarcissus', 'Nerine', 'Nymphaea_Tetragona', 'Paphiopedilum', 'Passiflora', 'Pelargonium', 'Petunia', 'Platycodon_Grandiflorus', 'Plumeria', 'Poinsettia', 'Primula', 'Protea_Cynaroides', 'Rose', 'Rudbeckia', 'Strelitzia_Reginae', 'Tropaeolum_Majus', 'Tussilago', 'Viola', 'Zantedeschia_Aethiopica']
NLABELS = len(LABELS)
BATCH_SIZE = 32
SIZE = 224 # 256
EPOCHS = 40
LR = 5e-6 # default 0.001
HIDDEN_SIZE = 768 # default 768
NHEADS = 8 # default 12
NLAYERS = 4 # default 12
Dataset
train_directory = '../dataset/Flower_Dataset/split/train'
test_directory = '../dataset/Flower_Dataset/split/val'
train_dataset = image_dataset_from_directory(
train_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED,
interpolation='bilinear',
follow_links=False,
crop_to_aspect_ratio=False
)
# Found 9206 files belonging to 48 classes.
test_dataset = image_dataset_from_directory(
test_directory,
labels='inferred',
label_mode='categorical',
class_names=LABELS,
color_mode='rgb',
batch_size=BATCH_SIZE,
image_size=(SIZE, SIZE),
shuffle=True,
seed=SEED
)
# Found 3090 files belonging to 48 classes.
data_augmentation = Sequential([
RandomRotation(factor = (0.25),),
RandomFlip(mode='horizontal',),
RandomContrast(factor=0.1),
RandomBrightness(0.1)
])
resize_rescale_reshape = Sequential([
Resizing(SIZE, SIZE),
Rescaling(1./255),
# transformer expects image shape (3,224,224)
Permute((3,1,2))
])
training_dataset = (
train_dataset
.map(lambda image, label: (data_augmentation(image), label))
.prefetch(tf.data.AUTOTUNE)
)
testing_dataset = (
test_dataset.prefetch(
tf.data.AUTOTUNE
)
)
ViT Model
# Initializing a ViT vit-base-patch16-224 style configuration
configuration = ViTConfig(
image_size=SIZE,
hidden_size=HIDDEN_SIZE,
num_attention_heads=NHEADS,
num_hidden_layers=NLAYERS
)
# Initializing a model with random weights from the vit-base-patch16-224 style configuration
# base_model = TFViTModel(configuration)
# use pretrained weights for the model instead
base_model = TFViTModel.from_pretrained("google/vit-base-patch16-224-in21k", config=configuration)
# Accessing the model configuration
configuration = base_model.config
configuration
inputs = Input(shape=(224,224,3))
x = resize_rescale_reshape(inputs)
x = base_model.vit(x)[0][:,0,:]
output = Dense(NLABELS, activation='softmax')(x)
vit_model = Model(inputs=inputs, outputs=output)
vit_model.summary()
# testing the pretrained model
test_image = cv.imread('../dataset/snapshots/Viola_Tricolor.jpg')
test_image = cv.resize(test_image, (SIZE, SIZE))
vit_model(tf.expand_dims(test_image, axis = 0))
# numpy=array([[0.01901147, 0.02026679, 0.02391427, 0.01970932, 0.01464635,
# 0.0257492 , 0.01927904, 0.01793713, 0.01944521, 0.01977614,
# 0.02793077, 0.02291007, 0.02077055, 0.02195414, 0.01900317,
# 0.01640951, 0.0187414 , 0.02054461, 0.01795707, 0.01564359,
# 0.02500662, 0.02195591, 0.02427697, 0.01805321, 0.01870451,
# 0.01892176, 0.01930878, 0.02687679, 0.02315602, 0.02085607,
# 0.01970802, 0.02608317, 0.02246164, 0.01824699, 0.02068511,
# 0.0230596 , 0.02106061, 0.02080243, 0.02133719, 0.02659844,
# 0.02275858, 0.02423375, 0.01562007, 0.01791171, 0.02137934,
# 0.02457437, 0.01662222, 0.01814036]], dtype=float32)>
Model Training
loss_function = CategoricalCrossentropy()
metrics = [CategoricalAccuracy(name='accuracy')]
vit_model.compile(
optimizer = Adam(learning_rate = LR),
loss = loss_function,
metrics = metrics
)
vit_history = vit_model.fit(
training_dataset,
validation_data = testing_dataset,
epochs = EPOCHS,
verbose = 1
)
# loss: 0.4105
# accuracy: 0.8328
# topk_accuracy: 0.9560
# val_loss: 0.4596
# val_accuracy: 0.8068
# val_topk_accuracy: 0.9495
vit_model.evaluate(testing_dataset)
# loss: 0.5979 - accuracy: 0.8589
plt.plot(vit_history.history['loss'])
plt.plot(vit_history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.savefig('assets/ViT_01.webp', bbox_inches='tight')

plt.plot(vit_history.history['accuracy'])
plt.plot(vit_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.savefig('assets/ViT_02.webp', bbox_inches='tight')

test_image = cv.imread('../dataset/snapshots/Viola_Tricolor.jpg')
test_image_resized = cv.resize(test_image, (SIZE, SIZE))
img = tf.constant(test_image_resized, dtype=tf.float32)
img = tf.expand_dims(img, axis=0)
probs = vit_model(img).numpy()
label = LABELS[tf.argmax(probs, axis=1).numpy()[0]]
print(label, str(probs[0]))
plt.imshow(test_image)
plt.title(label)
plt.axis('off')
test_image = cv.imread('../dataset/snapshots/Strelitzia.jpg')
test_image_resized = cv.resize(test_image, (SIZE, SIZE))
img = tf.constant(test_image_resized, dtype=tf.float32)
img = tf.expand_dims(img, axis=0)
probs = vit_model(img).numpy()
label = LABELS[tf.argmax(probs, axis=1).numpy()[0]]
print(label, str(probs[0]))
plt.imshow(test_image)
plt.title(label)
plt.axis('off')
test_image = cv.imread('../dataset/snapshots/Water_Lilly.jpg')
test_image_resized = cv.resize(test_image, (SIZE, SIZE))
img = tf.constant(test_image_resized, dtype=tf.float32)
img = tf.expand_dims(img, axis=0)
probs = vit_model(img).numpy()
label = LABELS[tf.argmax(probs, axis=1).numpy()[0]]
print(label, str(probs[0]))
plt.imshow(test_image)
plt.title(label)
plt.axis('off')
plt.figure(figsize=(16,16))
for images, labels in testing_dataset.take(1):
for i in range(16):
ax = plt.subplot(4,4,i+1)
true = "True: " + LABELS[tf.argmax(labels[i], axis=0).numpy()]
pred = "Predicted: " + LABELS[
tf.argmax(vit_model(tf.expand_dims(images[i], axis=0)).numpy(), axis=1).numpy()[0]
]
plt.title(
true + "\n" + pred
)
plt.imshow(images[i]/255.)
plt.axis('off')
plt.savefig('assets/ViT_03.webp', bbox_inches='tight')

y_pred = []
y_test = []
for img, label in testing_dataset:
y_pred.append(vit_model(img))
y_test.append(label.numpy())
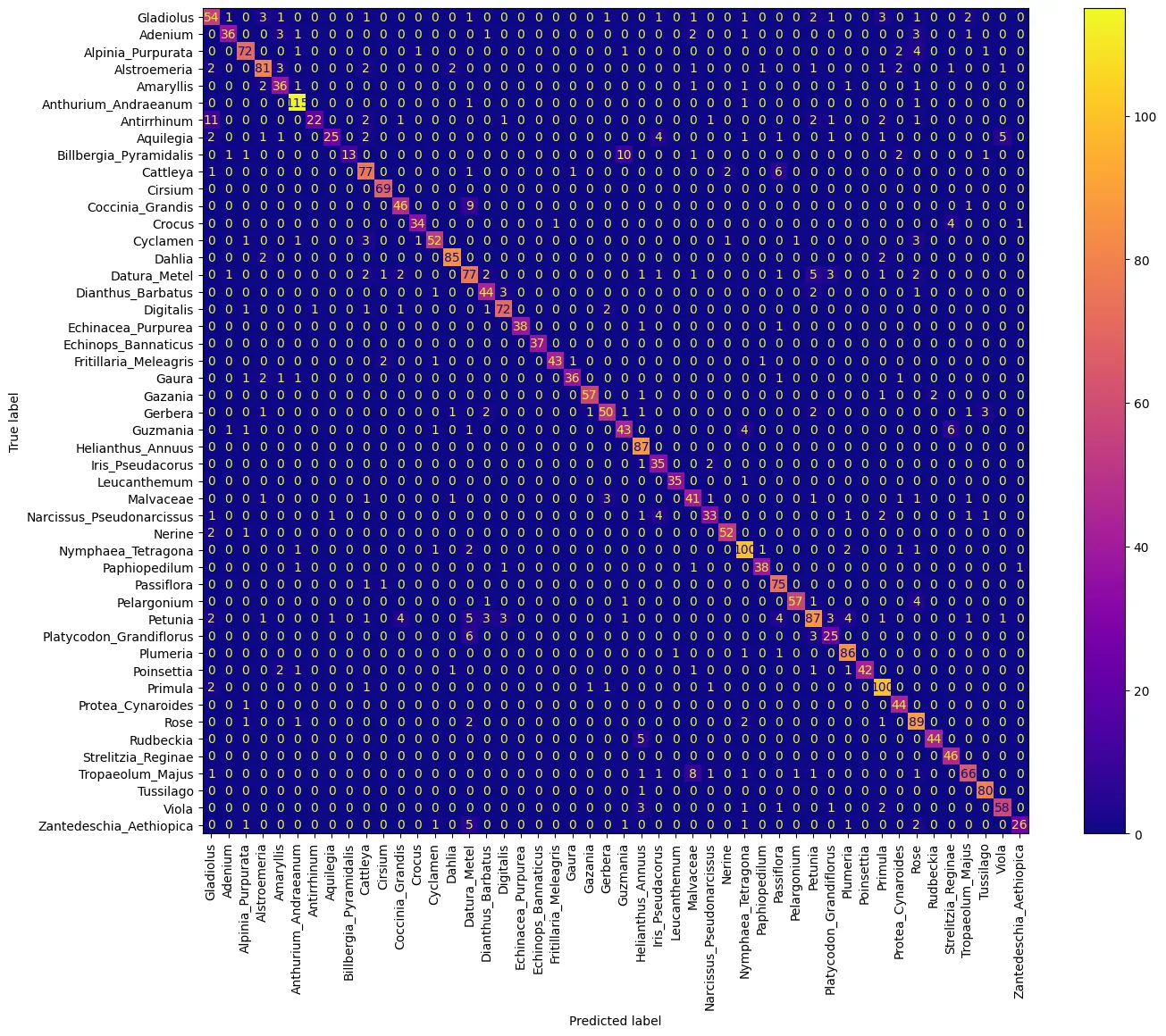
conf_mtx = ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix(
np.argmax(y_test[:-1], axis=-1).flatten(),
np.argmax(y_pred[:-1], axis=-1).flatten()
),
display_labels=LABELS
)
fig, ax = plt.subplots(figsize=(16,12))
conf_mtx.plot(ax=ax, cmap='plasma', include_values=True, xticks_rotation='vertical',)
plt.savefig('assets/ViT_04.webp', bbox_inches='tight')
Saving the Model
tf.keras.saving.save_model(
vit_model, '../saved_model/vit_model', overwrite=True, save_format='tf'
)
# restore the model
restored_model = tf.keras.saving.load_model('../saved_model/vit_model')
# Check its architecture
restored_model.summary()
restored_model.evaluate(testing_dataset)
# loss: 0.5979 - accuracy: 0.8589